折腾:
期间,想要对于这种:
去匹配到:
多个script
即分组的分组
结果用:
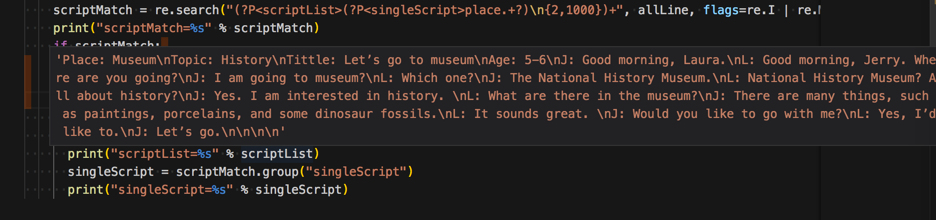
<code>scriptMatch = re.search("(?P<scriptList>(?P<singleScript>place.+?)\n{2,1000})+", allLine, flags=re.I | re.M | re.DOTALL)
</code>得到的scriptList也只是第一个script,而不是以为的所有的script
python re multiple group of group
Python Re: Multiple Capturing Groups – Stack Overflow
regex – Python Regular Expression Multiple Groups – Stack Overflow
python – How to match multiple groups regex – Stack Overflow
re中去搜索到分组的集合
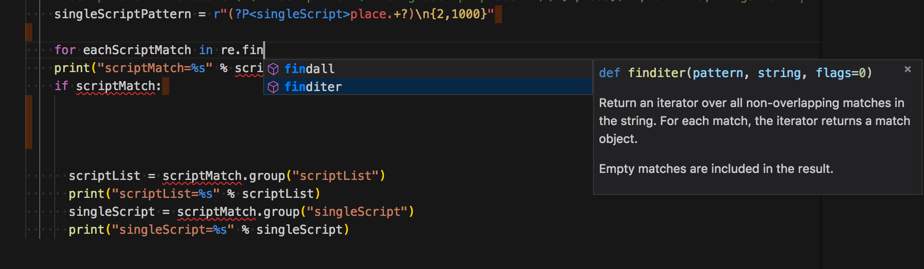
好像都提到了re.finditer
去找找re.finditer
https://docs.python.org/3/library/re.html#re.finditer
“re.finditer(pattern, string, flags=0)
Return an iterator yielding match objects over all non-overlapping matches for the RE pattern in string. The string is scanned left-to-right, and matches are returned in the order found. Empty matches are included in the result.
Changed in version 3.7: Non-empty matches can now start just after a previous empty match.
”
然后试试。
Repeating a Capturing Group vs. Capturing a Repeated Group
调试了好一会,加上
re.DOTALL的flag后,终于可以搜索到了:
然后又遇到一个坑:
iterator的object,被访问一次后,就变成空了:
所以此处的:
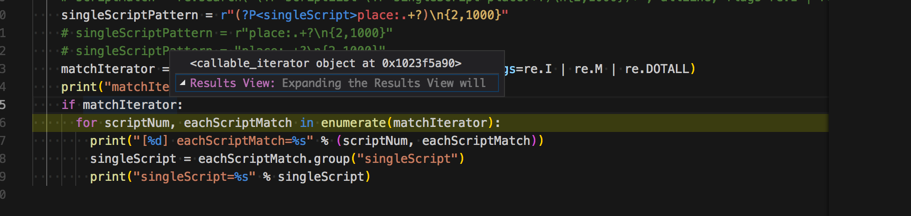
<code> matchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL)
print("matchIterator=%s" % matchIterator)
if matchIterator:
for scriptNum, eachScriptMatch in enumerate(matchIterator):
print("[%d] eachScriptMatch=%s" % (scriptNum, eachScriptMatch))
singleScript = eachScriptMatch.group("singleScript")
print("singleScript=%s" % singleScript)
</code>在:
if matchIterator:
matchIterator就是空了,后续for循环就无效了,得不到我们要的数据了。
【总结】
此处,直接用:
<code>matchIterator = re.finditer(yourPattern, toSearchStr, flags) </code>
即可得到对应的iterator类型的变量,可以用for循环去分别获取每个值
而其中的yourPattern,如果内部带group,则每个match的值中,可以直接用.group(“xx”)去获取对应的值,比如对于:
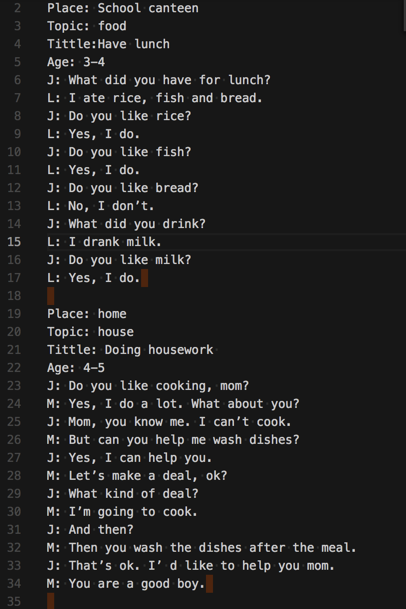
<code> Place: School canteen Topic: food Tittle:Have lunch Age: 3-4 J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. Place: home Topic: house Tittle: Doing housework Age: 4-5 J: Do you like cooking, mom? M: Yes, I do a lot. What about you? J: Mom, you know me. I can’t cook. M: But can you help me wash dishes? J: Yes, I can help you. M: Let’s make a deal, ok? J: What kind of deal? M: I’m going to cook. J: And then? M: Then you wash the dishes after the meal. J: That’s ok. I’ d like to help you mom. M: You are a good boy. 。。。 </code>
正则代码:
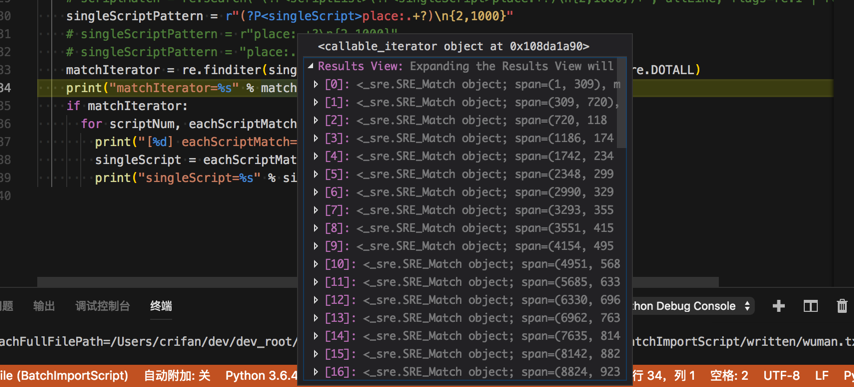
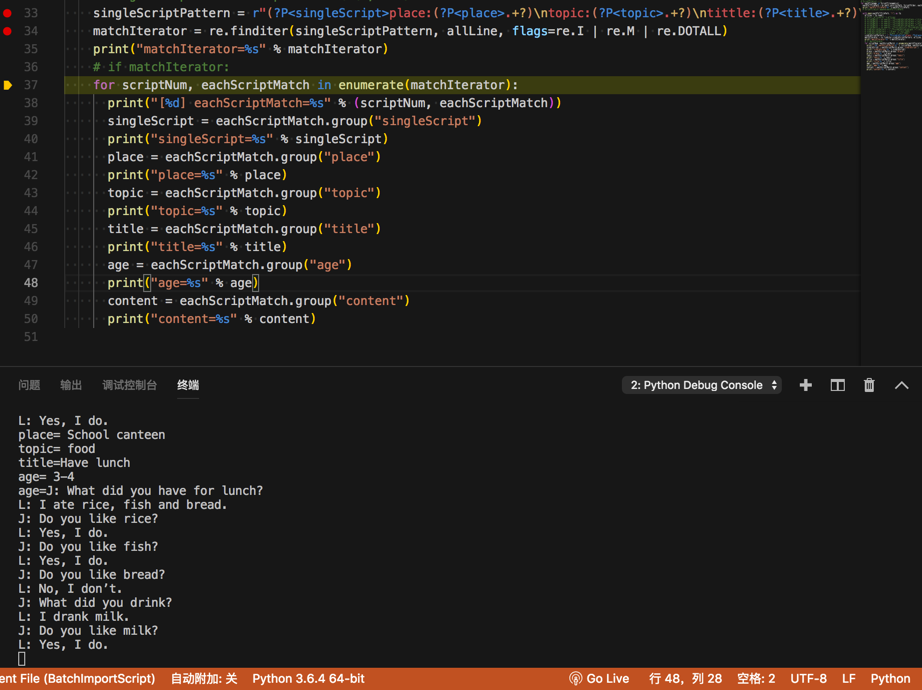
<code> singleScriptPattern = r"(?P<singleScript>place:(?P<place>.+?)\ntopic:(?P<topic>.+?)\ntittle:(?P<title>.+?)\nage:(?P<age>.+?)\n(?P<content>.+?))\n{2,1000}"
matchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL)
print("matchIterator=%s" % matchIterator)
# if matchIterator:
for scriptNum, eachScriptMatch in enumerate(matchIterator):
print("[%d] eachScriptMatch=%s" % (scriptNum, eachScriptMatch))
singleScript = eachScriptMatch.group("singleScript")
print("singleScript=%s" % singleScript)
place = eachScriptMatch.group("place")
print("place=%s" % place)
topic = eachScriptMatch.group("topic")
print("topic=%s" % topic)
title = eachScriptMatch.group("title")
print("title=%s" % title)
age = eachScriptMatch.group("age")
print("age=%s" % age)
content = eachScriptMatch.group("content")
print("content=%s" % content)
</code>结果:
<code>matchIterator=<callable_iterator object at 0x10e3f7b70> [0] eachScriptMatch=<_sre.SRE_Match object; span=(1, 309), match='Place: School canteen\nTopic: food\nTittle:Have l> singleScript=Place: School canteen Topic: food Tittle:Have lunch Age: 3-4 J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. place= School canteen topic= food title=Have lunch age= 3-4 age=J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. </code>
转载请注明:在路上 » 【已解决】Python中用正则re去搜索分组的集合