对于之前的手动操作去 找小毛怪 Humf 的字幕:
但是找到个好(工具)网站,支持提取youtube中视频的字幕的,具体步骤:
针对于Humf的youtube官网的每个系列:
Humf – Official Channel – YouTube – YouTube
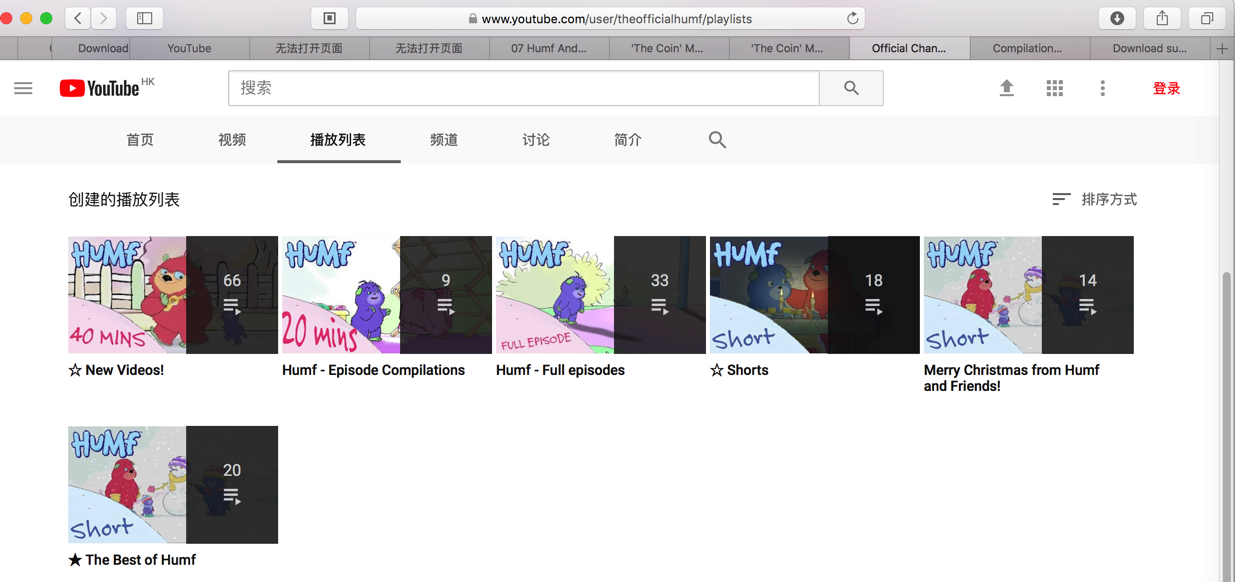
点击进去后:
https://www.youtube.com/watch?v=eDaHu2vnvlM&list=PLHOR8x-IicVIHXV3Dkro99d4KyBAuVx9_
即 对于 每个系列中的每个视频:
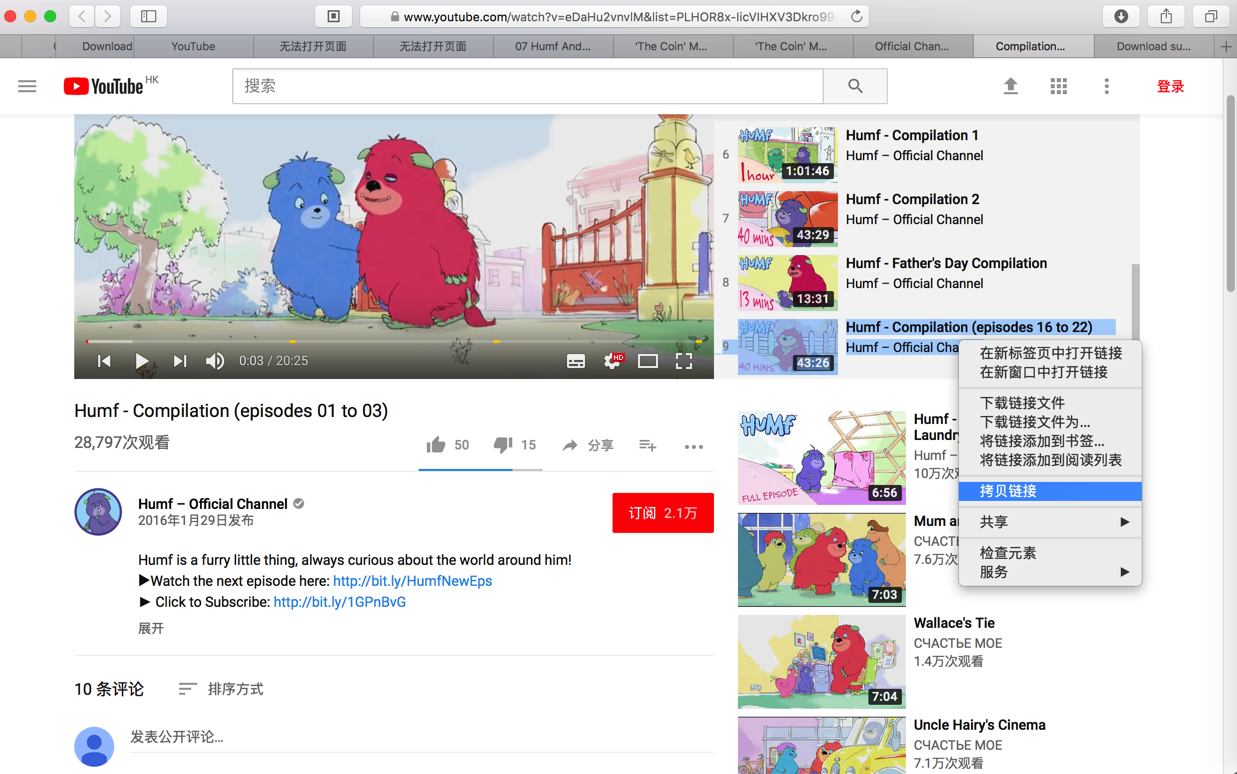
的页面地址,粘贴到:
中,然后点击Download后,即可看到有很多语言的srt字幕,点击English的下载即可得到srt文件。
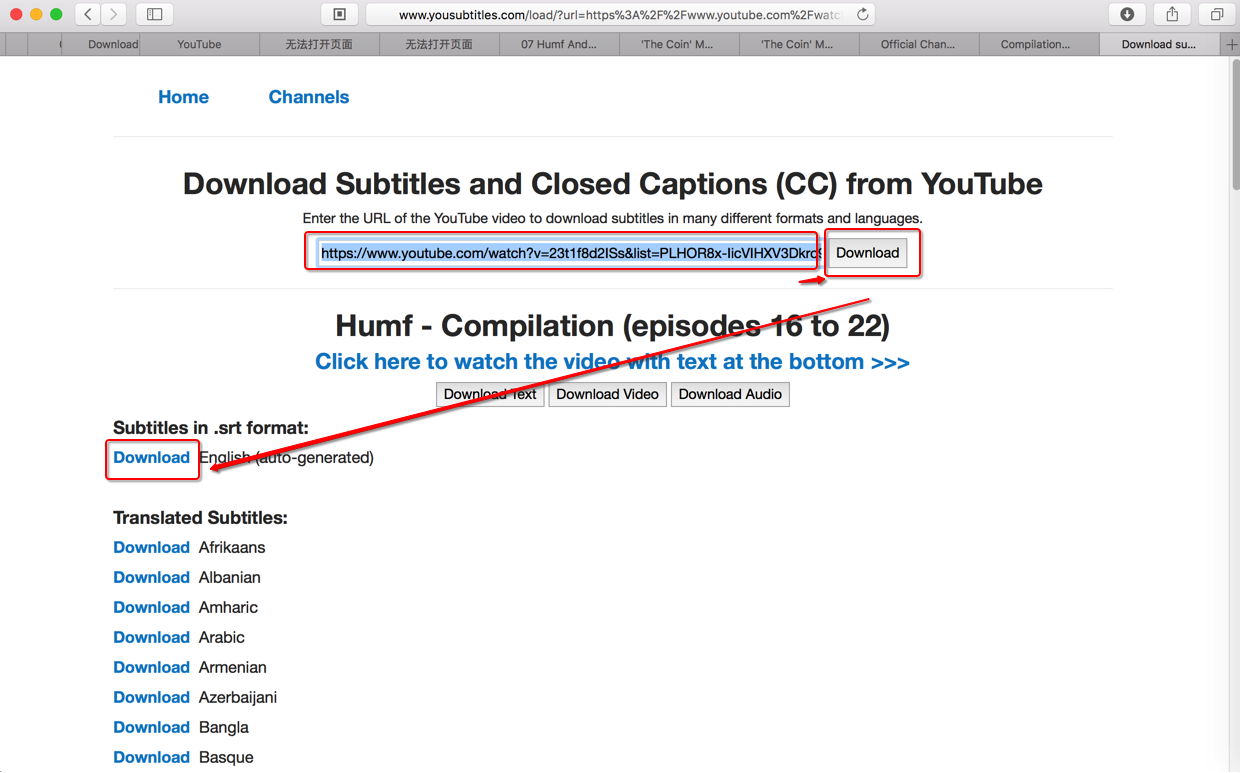
其余的100多个视频的字幕:
要么我抽空写爬虫脚本 自动化去下载
现在希望用scrapy去实现
之前已经折腾了一点scrapy了:
【记录】用Python的Scrapy去爬取cbeebies.com
现在去试试上面这个爬取。
所以入口是:
Humf – Official Channel – YouTube – YouTube
去创建项目:
➜ scrapy scrapy startproject youtubeSubtitle
New Scrapy project ‘youtubeSubtitle’, using template directory ‘/usr/local/lib/python2.7/site-packages/scrapy/templates/project’, created in:
/Users/crifan/dev/dev_root/company/naturling/projects/scrapy/youtubeSubtitle
You can start your first spider with:
cd youtubeSubtitle
scrapy genspider example example.com
➜ scrapy cd youtubeSubtitle
然后看到提示,所以去看看命令:
➜ youtubeSubtitle scrapy –help
Scrapy 1.4.0 – project: youtubeSubtitle
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
check Check spider contracts
crawl Run a spider
edit Edit spider
fetch Fetch a URL using the Scrapy downloader
genspider Generate new spider using pre-defined templates
list List available spiders
parse Parse URL (using its spider) and print the results
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
Use “scrapy <command> -h” to see more info about a command
果然genspider是用来生成默认的爬虫的,然后就去创建:
➜ youtubeSubtitle scrapy genspider YoutubeSubtitle youtube.com
Created spider ‘YoutubeSubtitle’ using template ‘basic’ in module:
youtubeSubtitle.spiders.YoutubeSubtitle
自动生成的内容是:
# -*- coding: utf-8 -*-
import scrapy
class YoutubesubtitleSpider(scrapy.Spider):
name = ‘YoutubeSubtitle’
allowed_domains = [‘youtube.com’]
start_urls = [‘http://youtube.com/’]
def parse(self, response):
pass
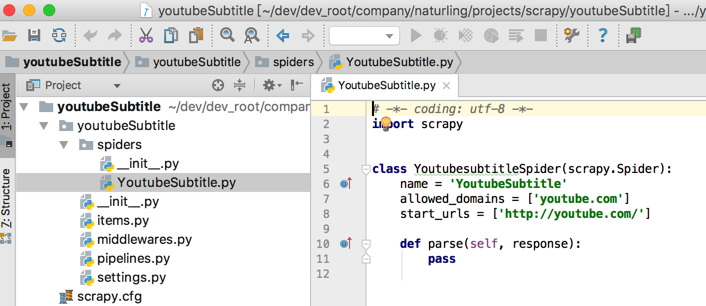
然后继续添加内容:
# -*- coding: utf-8 -*-
import scrapy
class YoutubesubtitleSpider(scrapy.Spider):
name = ‘YoutubeSubtitle’
allowed_domains = [‘youtube.com’, “yousubtitles.com”]
start_urls = [
“https://www.youtube.com/user/theofficialhumf/playlists”
]
def parse(self, response):
respUrl = response.url
print “respUrl=%s”%(respUrl)
filename = respUrl.split(“/”)[-2] + ‘.html’
with open(filename, ‘wb’) as f:
f.write(response.body)
然后去执行:
➜ youtubeSubtitle scrapy crawl YoutubeSubtitle
2018-01-13 10:49:45 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: youtubeSubtitle)
2018-01-13 10:49:45 [scrapy.utils.log] INFO: Overridden settings: {‘NEWSPIDER_MODULE’: ‘youtubeSubtitle.spiders’, ‘SPIDER_MODULES’: [‘youtubeSubtitle.spiders’], ‘ROBOTSTXT_OBEY’: True, ‘BOT_NAME’: ‘youtubeSubtitle’}
2018-01-13 10:49:45 [scrapy.middleware] INFO: Enabled extensions:
[‘scrapy.extensions.memusage.MemoryUsage’,
‘scrapy.extensions.logstats.LogStats’,
‘scrapy.extensions.telnet.TelnetConsole’,
‘scrapy.extensions.corestats.CoreStats’]
2018-01-13 10:49:45 [scrapy.middleware] INFO: Enabled downloader middlewares:
[‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware’,
‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware’,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware’,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware’,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware’,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware’,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware’,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware’,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’,
‘scrapy.downloadermiddlewares.stats.DownloaderStats’]
2018-01-13 10:49:45 [scrapy.middleware] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware’,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’,
‘scrapy.spidermiddlewares.referer.RefererMiddleware’,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware’,
‘scrapy.spidermiddlewares.depth.DepthMiddleware’]
2018-01-13 10:49:45 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-01-13 10:49:45 [scrapy.core.engine] INFO: Spider opened
2018-01-13 10:49:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:49:45 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
好像卡死了
难道是因为还没翻墙导致的?
果然超时了:
2018-01-13 10:49:45 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-01-13 10:50:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:51:00 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.youtube.com/robots.txt> (failed 1 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:51:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:52:16 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.youtube.com/robots.txt> (failed 2 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:52:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:53:31 [scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET https://www.youtube.com/robots.txt> (failed 3 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:53:31 [scrapy.downloadermiddlewares.robotstxt] ERROR: Error downloading <GET https://www.youtube.com/robots.txt>: TCP connection timed out: 60: Operation timed out.
TCPTimedOutError: TCP connection timed out: 60: Operation timed out.
2018-01-13 10:53:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:54:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:54:48 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.youtube.com/user/theofficialhumf/playlists> (failed 1 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:55:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:56:04 [scrapy.downloadermiddlewares.retry] DEBUG: Retrying <GET https://www.youtube.com/user/theofficialhumf/playlists> (failed 2 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:56:45 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2018-01-13 10:57:20 [scrapy.downloadermiddlewares.retry] DEBUG: Gave up retrying <GET https://www.youtube.com/user/theofficialhumf/playlists> (failed 3 times): TCP connection timed out: 60: Operation timed out.
2018-01-13 10:57:20 [scrapy.core.scraper] ERROR: Error downloading <GET https://www.youtube.com/user/theofficialhumf/playlists>: TCP connection timed out: 60: Operation timed out.
2018-01-13 10:57:20 [scrapy.core.engine] INFO: Closing spider (finished)
2018-01-13 10:57:20 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{‘downloader/exception_count’: 6,
‘downloader/exception_type_count/twisted.internet.error.TCPTimedOutError’: 6,
‘downloader/request_bytes’: 1398,
‘downloader/request_count’: 6,
‘downloader/request_method_count/GET’: 6,
‘finish_reason’: ‘finished’,
‘finish_time’: datetime.datetime(2018, 1, 13, 2, 57, 20, 551337),
‘log_count/DEBUG’: 7,
‘log_count/ERROR’: 2,
‘log_count/INFO’: 14,
‘memusage/max’: 50995200,
‘memusage/startup’: 50167808,
‘retry/count’: 4,
‘retry/max_reached’: 2,
‘retry/reason_count/twisted.internet.error.TCPTimedOutError’: 4,
‘scheduler/dequeued’: 3,
‘scheduler/dequeued/memory’: 3,
‘scheduler/enqueued’: 3,
‘scheduler/enqueued/memory’: 3,
‘start_time’: datetime.datetime(2018, 1, 13, 2, 49, 45, 656662)}
2018-01-13 10:57:20 [scrapy.core.engine] INFO: Spider closed (finished)
所以要去:
【已解决】Scrapy如何添加本地socks代理以便能打开Youtube网页
然后从网页中提取出多个系列的地址
保存出来的页面,希望提取的是:
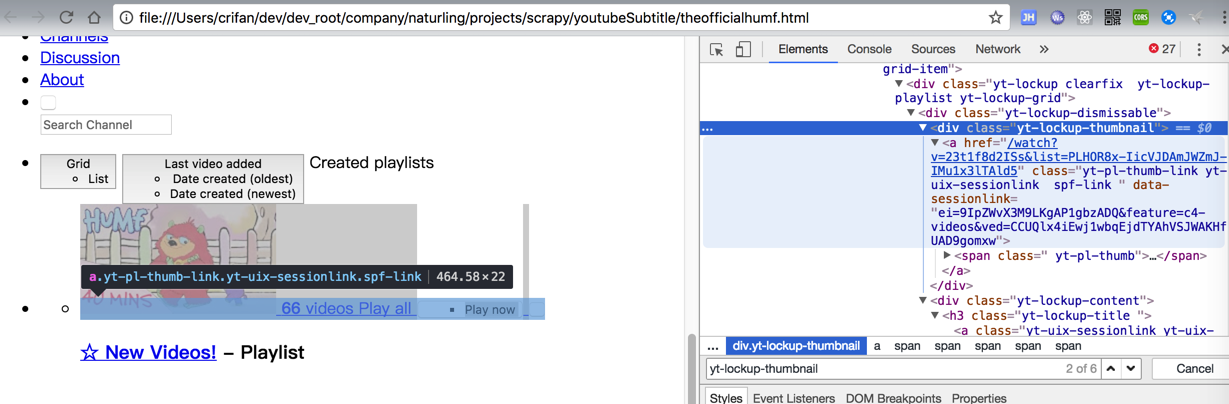
‘//div[@class=“yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’
去参考:
【记录】尝试Scrapy shell去提取cbeebies.com页面中的子url
中的scrapy shell去试试xpath能不能找到我们要的内容
先去:
➜ youtubeSubtitle scrapy shell
2018-01-13 21:05:57 [scrapy.utils.log] INFO: Scrapy 1.4.0 started (bot: youtubeSubtitle)
2018-01-13 21:05:57 [scrapy.utils.log] INFO: Overridden settings: {‘NEWSPIDER_MODULE’: ‘youtubeSubtitle.spiders’, ‘ROBOTSTXT_OBEY’: True, ‘DUPEFILTER_CLASS’: ‘scrapy.dupefilters.BaseDupeFilter’, ‘SPIDER_MODULES’: [‘youtubeSubtitle.spiders’], ‘BOT_NAME’: ‘youtubeSubtitle’, ‘LOGSTATS_INTERVAL’: 0}
2018-01-13 21:05:57 [scrapy.middleware] INFO: Enabled extensions:
[‘scrapy.extensions.memusage.MemoryUsage’,
‘scrapy.extensions.telnet.TelnetConsole’,
‘scrapy.extensions.corestats.CoreStats’]
2018-01-13 21:05:57 [scrapy.middleware] INFO: Enabled downloader middlewares:
[‘youtubeSubtitle.middlewares.ProxyMiddleware’,
‘scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware’,
‘scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware’,
‘scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware’,
‘scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware’,
‘scrapy.downloadermiddlewares.useragent.UserAgentMiddleware’,
‘scrapy.downloadermiddlewares.retry.RetryMiddleware’,
‘scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware’,
‘scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware’,
‘scrapy.downloadermiddlewares.redirect.RedirectMiddleware’,
‘scrapy.downloadermiddlewares.cookies.CookiesMiddleware’,
‘scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware’,
‘scrapy.downloadermiddlewares.stats.DownloaderStats’]
2018-01-13 21:05:57 [scrapy.middleware] INFO: Enabled spider middlewares:
[‘scrapy.spidermiddlewares.httperror.HttpErrorMiddleware’,
‘scrapy.spidermiddlewares.offsite.OffsiteMiddleware’,
‘scrapy.spidermiddlewares.referer.RefererMiddleware’,
‘scrapy.spidermiddlewares.urllength.UrlLengthMiddleware’,
‘scrapy.spidermiddlewares.depth.DepthMiddleware’]
2018-01-13 21:05:57 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-01-13 21:05:57 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x111cd2b90>
[s] item {}
[s] settings <scrapy.settings.Settings object at 0x111cd2b10>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
研究了下,最后是:
>>> fetch(“https://www.youtube.com/user/theofficialhumf/playlists“)
2018-01-13 21:07:09 [scrapy.core.engine] INFO: Spider opened
2018-01-13 21:07:09 [default] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET https://www.youtube.com/user/theofficialhumf/playlists>, spider=<DefaultSpider ‘default’ at 0x111f751d0>
2018-01-13 21:07:09 [default] INFO: request.meta{‘handle_httpstatus_list’: <scrapy.utils.datatypes.SequenceExclude object at 0x111f75090>, ‘proxy’: ‘http://127.0.0.1:1087’}
2018-01-13 21:07:09 [default] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET https://www.youtube.com/robots.txt>, spider=<DefaultSpider ‘default’ at 0x111f751d0>
2018-01-13 21:07:09 [default] INFO: request.meta{‘dont_obey_robotstxt’: True, ‘proxy’: ‘http://127.0.0.1:1087’}
2018-01-13 21:07:11 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youtube.com/robots.txt> (referer: None)
2018-01-13 21:07:13 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://www.youtube.com/user/theofficialhumf/playlists> (referer: None)
fetch(“your_url”)
得到了结果
无意间用:
>>> view(response)
True
调用了浏览器打开结果:
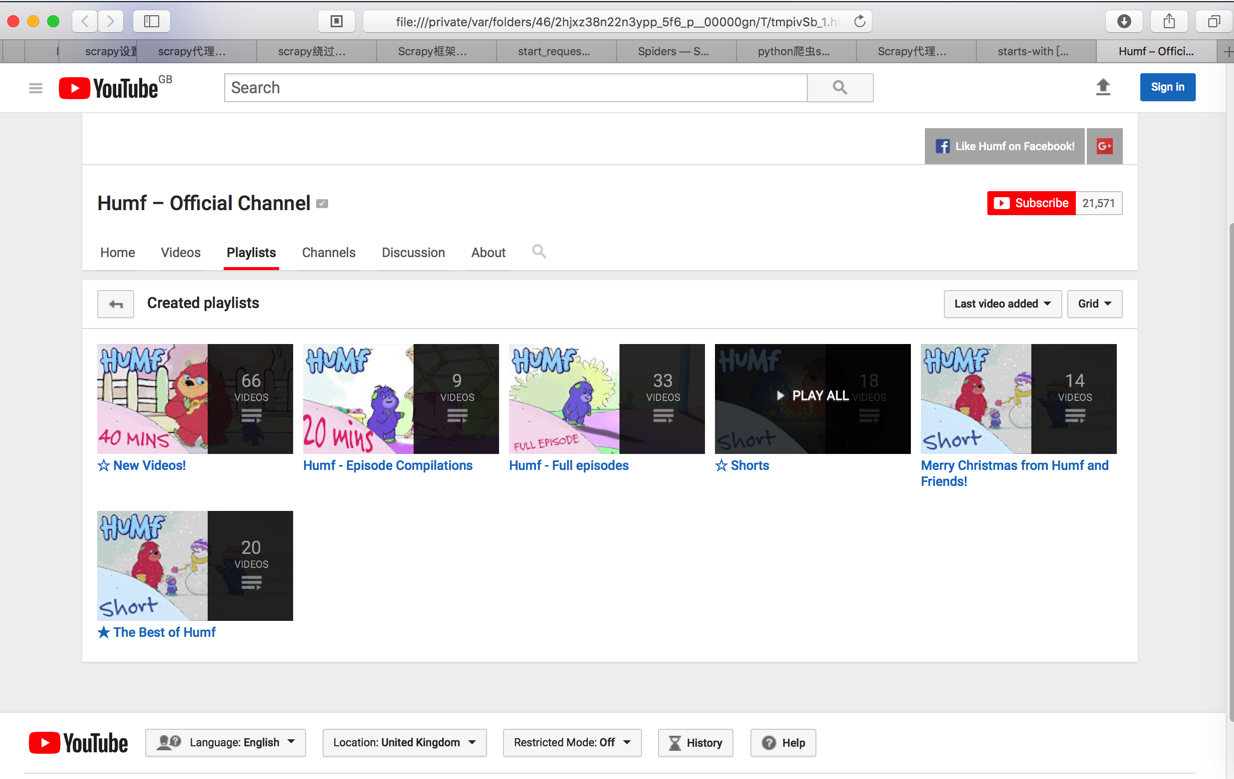
然后继续response.body可以得到结果
这样就可以接续试试xpath了
但是上面view出来的网页中,想要的地址是:
https://www.youtube.com/watch?v=eDaHu2vnvlM&list=PLHOR8x-IicVIHXV3Dkro99d4KyBAuVx9_
但是此处的:
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]’)
[<Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]’ data=u'<div class=”yt-lockup-thumbnail”>\n ‘>]
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a’)
[<Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=23t1f8d2ISs&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=eDaHu2vnvlM&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=Ensz3fh8608&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=I7xxF6iTCTc&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=gpwWkfIyOao&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a’ data=u'<a href=”/watch?v=gpwWkfIyOao&list=P’>]
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)
[<Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=23t1f8d2ISs&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=eDaHu2vnvlM&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=Ensz3fh8608&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=I7xxF6iTCTc&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=gpwWkfIyOao&list=P’>, <Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=gpwWkfIyOao&list=P’>]
地址貌似只是:
/watch?v=23t1f8d2ISs&list=P
后面地址不全的感觉
或许是此处调试期间的后续数据没有完全显示?
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)[0]
<Selector xpath=’//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’ data=u'<a href=”/watch?v=23t1f8d2ISs&list=P’>
继续调试看看
试了试a属性,结果没有:
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)[0].a
Traceback (most recent call last):
File “<console>”, line 1, in <module>
AttributeError: ‘Selector’ object has no attribute ‘a’
无意间试了试extract,结果可以看到希望的全部内容了:
>>> response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)[0].extract()
u'<a href=”/watch?v=23t1f8d2ISs&list=PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5″ class=”yt-pl-thumb-link yt-uix-sessionlink spf-link ” data-sessionlink=”ei=eQRaWs-OIsK9qQHosZ3IBA&feature=c4-videos&ved=CDcQlx4iEwiPr5_2gNXYAhXCXioKHehYB0komxw”>\n <span class=” yt-pl-thumb”>\n \n <span class=”video-thumb yt-thumb yt-thumb-196″>\n <span class=”yt-thumb-default”>\n <span class=”yt-thumb-clip”>\n \n <img width=”196″ data-ytimg=”1″ src=”https://i.ytimg.com/vi/23t1f8d2ISs/hqdefault.jpg?sqp=-oaymwEWCMQBEG5IWvKriqkDCQgBFQAAiEIYAQ==&;rs=AOn4CLAlYOJF6LvCxIQsdzkOtRxyA3l1pw” onload=”;window.__ytRIL && __ytRIL(this)” alt=”” aria-hidden=”true”>\n\n <span class=”vertical-align”></span>\n </span>\n </span>\n </span>\n\n\n <span class=”sidebar”>\n <span class=”yt-pl-sidebar-content yt-valign”>\n <span class=”yt-valign-container”>\n <span class=”formatted-video-count-label”>\n <b>66</b> videos\n </span>\n\n <span class=”yt-pl-icon yt-pl-icon-reg yt-sprite”></span>\n </span>\n </span>\n </span>\n\n <span class=”yt-pl-thumb-overlay”>\n <span class=”yt-pl-thumb-overlay-content”>\n <span class=”play-icon yt-sprite”></span>\n <span class=”yt-pl-thumb-overlay-text”>\nPlay all\n </span>\n </span>\n </span>\n\n <span class=”yt-pl-watch-queue-overlay”>\n <span class=”thumb-menu dark-overflow-action-menu video-actions”>\n <button aria-expanded=”false” aria-haspopup=”true” onclick=”;return false;” class=”yt-uix-button-reverse flip addto-watch-queue-menu spf-nolink hide-until-delayloaded yt-uix-button yt-uix-button-dark-overflow-action-menu yt-uix-button-size-default yt-uix-button-has-icon no-icon-markup yt-uix-button-empty” type=”button”><span class=”yt-uix-button-arrow yt-sprite”></span><ul class=”watch-queue-thumb-menu yt-uix-button-menu yt-uix-button-menu-dark-overflow-action-menu hid”><li role=”menuitem” class=”overflow-menu-choice addto-watch-queue-menu-choice addto-watch-queue-play-now yt-uix-button-menu-item” data-action=”play-now” onclick=”;return false;” data-list-id=”PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5″><span class=”addto-watch-queue-menu-text”>Play now</span></li></ul></button>\n </span>\n\n <button class=”yt-uix-button yt-uix-button-size-small yt-uix-button-default yt-uix-button-empty yt-uix-button-has-icon no-icon-markup addto-button addto-queue-button video-actions spf-nolink hide-until-delayloaded addto-tv-queue-button yt-uix-tooltip” type=”button” onclick=”;return false;” title=”Queue” data-style=”tv-queue” data-list-id=”PLHOR8x-IicVJDAmJWZmJ-IMu1x3lTAld5″></button>\n\n </span>\n\n </span>\n\n </a>’
{kind=link}
其中的内容,就是之前从正常的网页中拷贝出来的html:
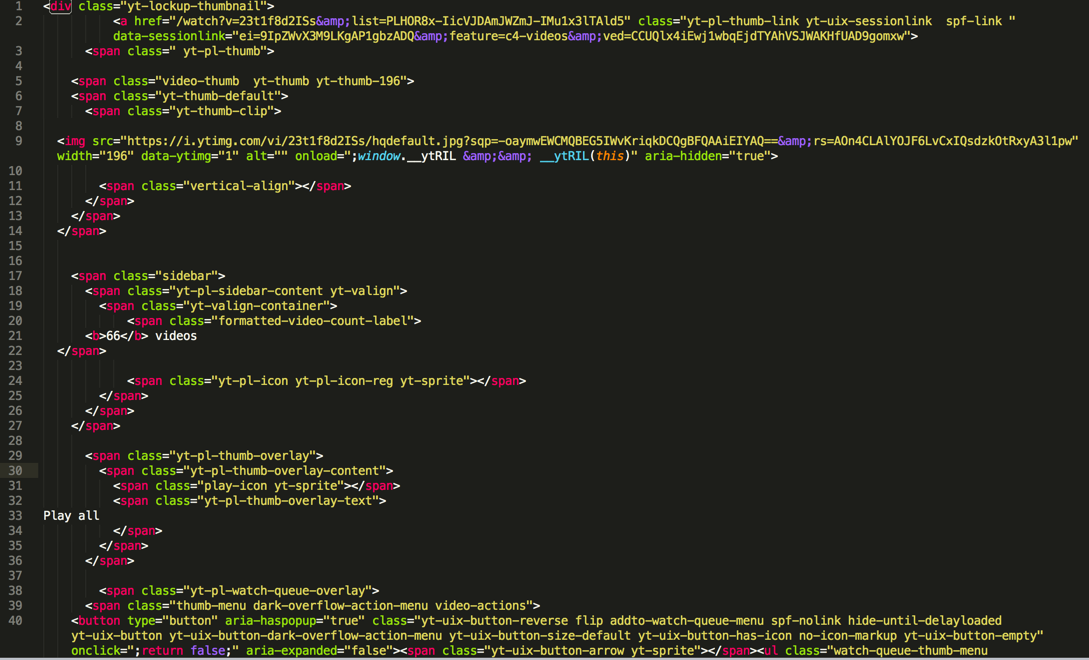
所以是可以正常获取需要的div下的a节点的
用代码:
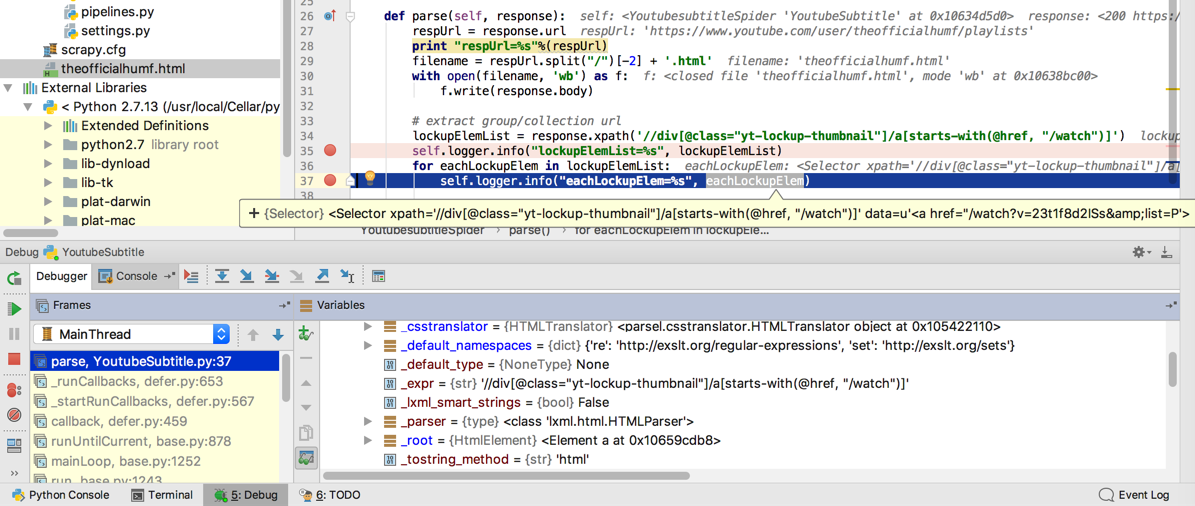
def parse(self, response):
respUrl = response.url
print “respUrl=%s”%(respUrl)
filename = respUrl.split(“/”)[-2] + ‘.html’
with open(filename, ‘wb’) as f:
f.write(response.body)
# extract group/collection url
lockupElemList = response.xpath(‘//div[@class=”yt-lockup-thumbnail”]/a[starts-with(@href, “/watch”)]’)
self.logger.info(“lockupElemList=%s”, lockupElemList)
for eachLockupElem in lockupElemList:
self.logger.info(“eachLockupElem=%s”, eachLockupElem)
是可以获得对应的div的element的:
接着就需要去搞清楚:
【已解决】如何从Scrapy的Selector中获取html元素a的href属性的值
然后接着:
【已解决】scrapy中警告:DEBUG: Forbidden by robots.txt
接着又遇到:
然后接着就是去:
【已解决】Scrapy的Python中如何解析部分的html字符串并格式化为html网页源码
接着再去想办法看看能否传递参数下去:
【已解决】Scrapy如何向后续Request的callback中传递参数
以及:
【已解决】Python中json的dumps出错:raise TypeError(repr(o) + ” is not JSON serializable”)
结果发现: