需要实现爬取汽车之家的所有的品牌的车系和车型数据:
https://www.autohome.com.cn/car/
现在去写Python的爬虫。
之前了解有多个爬虫框架,用过Scrapy,貌似有点点复杂。
听说PySpider不错,去试试,主要看中的是“WEB 界面编写”
先去了解对比看看:
pyspider vs scrapy
pyspider 和 scrapy 比较起来有什么优缺点吗? – 知乎
Python爬虫框架–pyspider初体验 – CSDN博客
pyspider 爬虫教程(一):HTML 和 CSS 选择器 | Binuxの杂货铺
爬虫框架Sasila—-乞丐版scrapy+webmagic+pyspider – 后端 – 掘金
还是直接去用吧
pyspider
pyspider是开源强大的python爬虫系统 – pyspider中文网
继续参考:
https://cuiqingcai.com/2652.html
去试试
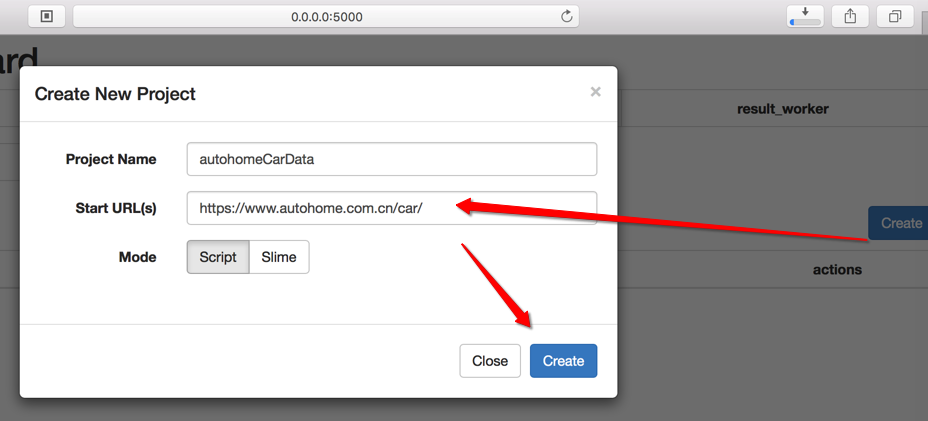
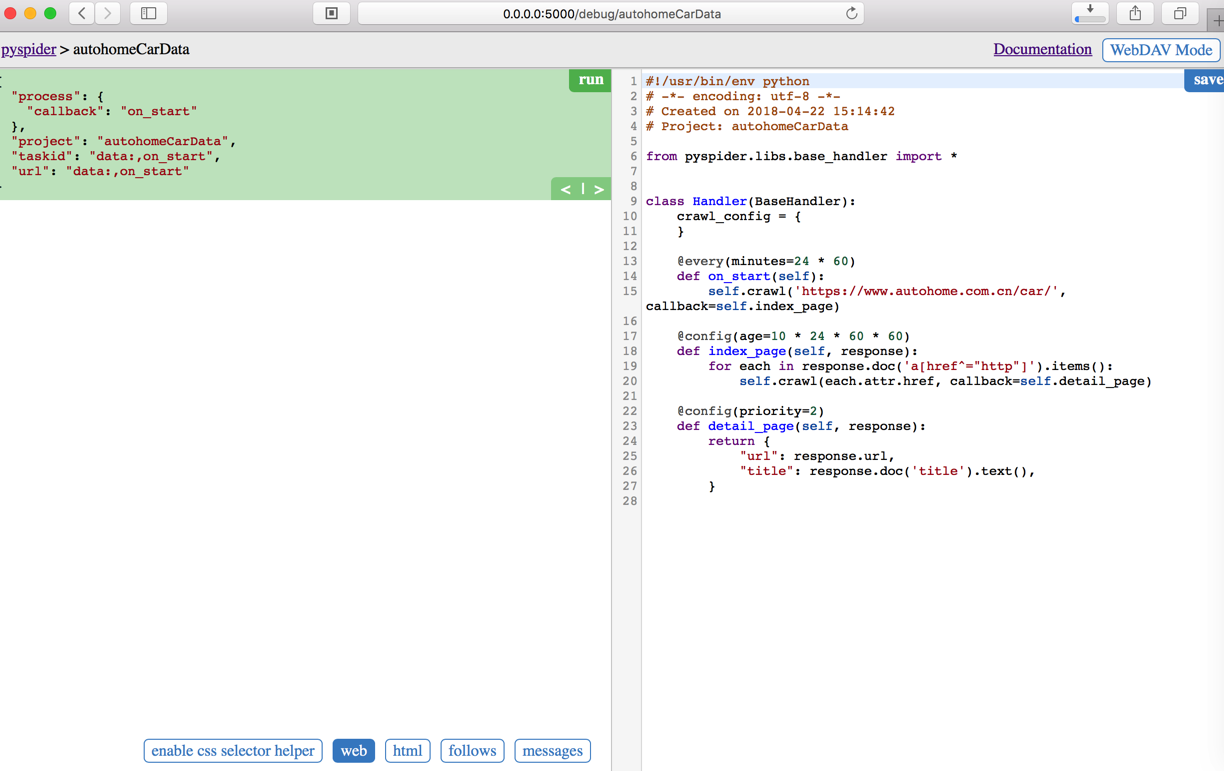
然后点击Run后,再点击detail_page的Run按钮:
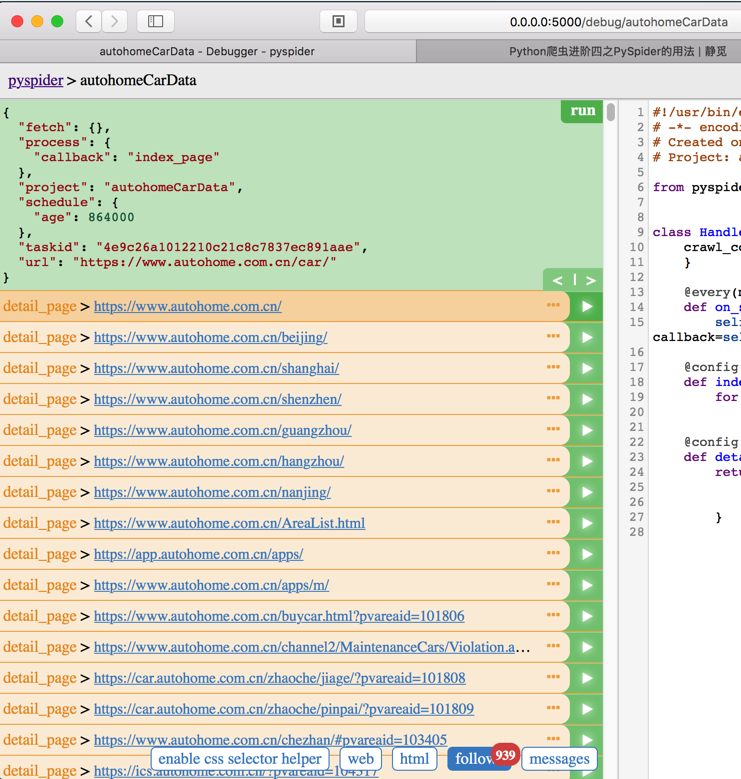
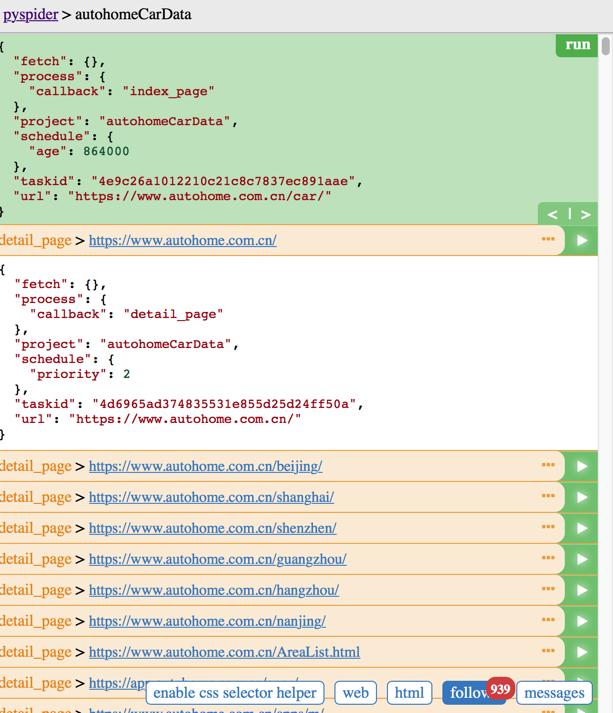
点击web,显示空白啊:
不过点击html,可以看到html:
参考:
继续搞懂
点击回来管理页面:
然后去研究如何使用:
二是又发现另外的问题:
【已解决】pyspider中如何加载汽车之家页面中的更多内容
后来换了Chrome浏览器,继续抓取页面,点击web,就可以看到页面了:
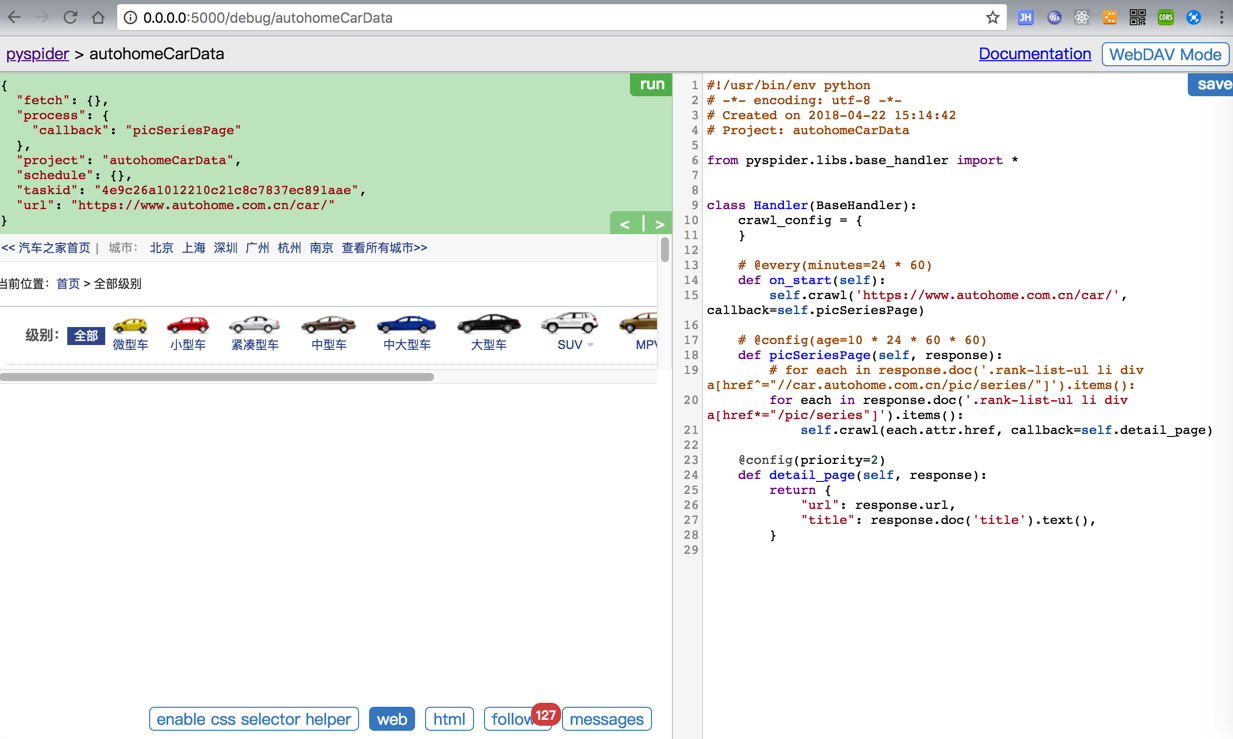
但是很明显和正常的内容相比:
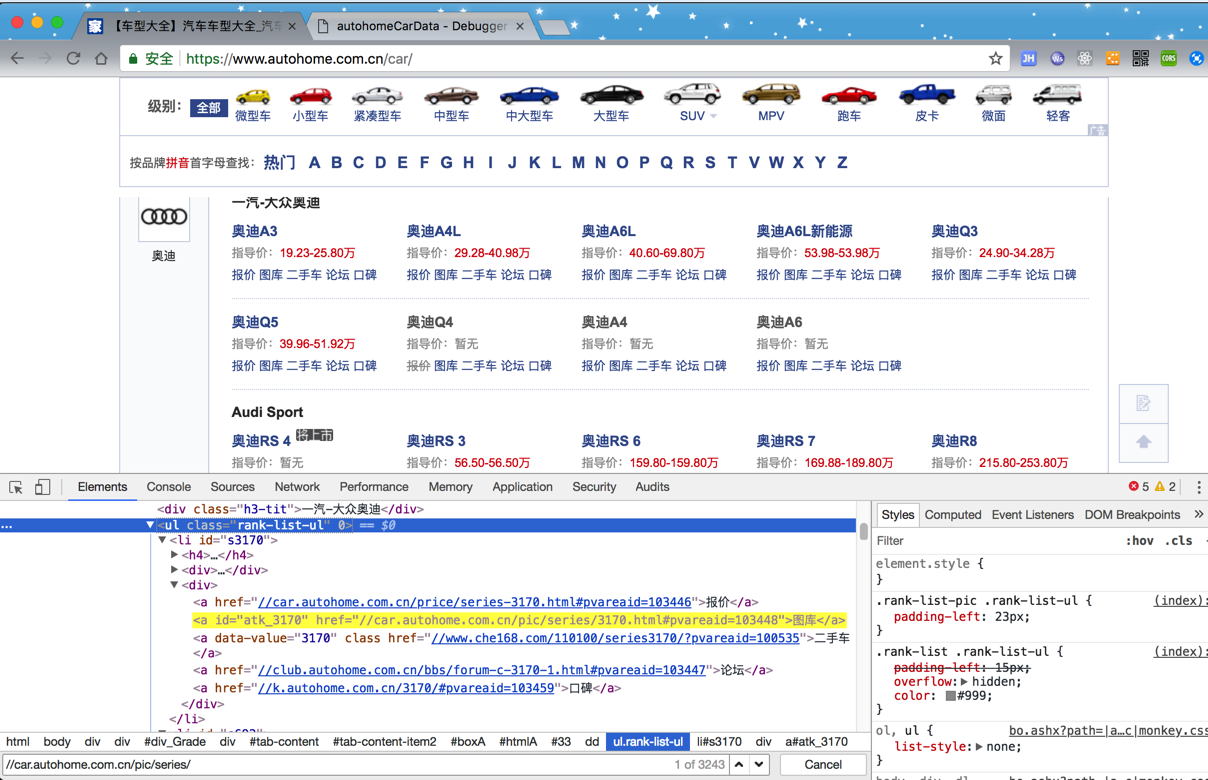
还是缺少了内容
-》估计是js没有加载?
后来好像加载web页面内容也是正常的了。
继续调试
现在已经用代码:
<code>#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-04-22 15:14:42
# Project: autohomeCarData
from pyspider.libs.base_handler import *
import string
class Handler(BaseHandler):
crawl_config = {
}
# @every(minutes=24 * 60)
def on_start(self):
for eachLetter in list(string.ascii_lowercase):
self.crawl("https://www.autohome.com.cn/grade/carhtml/%s.html" % eachLetter, callback=self.gradCarHtmlPage)
def gradCarHtmlPage(self, response):
picSeriesItemList = response.doc('.rank-list-ul li div a[href*="/pic/series"]').items()
# print("len(picSeriesItemList)=%s"%(len(picSeriesItemList)))
for each in picSeriesItemList:
self.crawl(each.attr.href, callback=self.detail_page)
# @config(age=10 * 24 * 60 * 60)
def picSeriesPage(self, response):
# for each in response.doc('.rank-list-ul li div a[href^="//car.autohome.com.cn/pic/series/"]').items():
for each in response.doc('.rank-list-ul li div a[href*="/pic/series"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
# <a href="/pic/series-t/66.html">查看停产车型&nbsp;&gt;</a>
# <a class="ckmore" href="/pic/series/588.html">查看在售车型&nbsp;&gt;</a>
# <span class="fn-right">&nbsp;</span>
fnRightPicSeries = response.doc('.search-pic-tbar .fn-right a[href*="/pic/series"]')
print("fnRightPicSeries=", fnRightPicSeries)
if fnRightPicSeries:
# hrefValue = fnRightPicSeries.attr.href
# print("hrefValue=", hrefValue)
# fullPicSeriesUrl = "https://car.autohome.com.cn" + hrefValue
fullPicSeriesUrl = fnRightPicSeries.attr.href
print("fullPicSeriesUrl=", fullPicSeriesUrl)
self.crawl(fullPicSeriesUrl, callback=self.detail_page)
# contine parse brand data
aDictList = []
# for eachA in response.doc('.breadnav a[href^="/"]').items():
for eachA in response.doc('.breadnav a[href*="/pic/"]').items():
eachADict = {
"text" : eachA.text(),
"href": eachA.attr.href
}
print("eachADict=", eachADict)
aDictList.append(eachADict)
print("aDictList=", aDictList)
mainBrandDict = aDictList[-1]
subBrandDict = aDictList[-2]
brandSerieDict = aDictList[-3]
print("mainBrandDict=%s, subBrandDict=%s, brandSerieDict=%s"%(mainBrandDict, subBrandDict, brandSerieDict))
dtTextList = []
for eachDt in response.doc("dl.search-pic-cardl dt").items():
dtTextList.append(eachDt.text())
print("dtTextList=", dtTextList)
groupCount = len(dtTextList)
print("groupCount=", groupCount)
for eachDt in response.doc("dl.search-pic-cardl dt").items():
dtTextList.append(eachDt.text())
ddUlEltList = []
for eachDdUlElt in response.doc("dl.search-pic-cardl dd ul").items():
ddUlEltList.append(eachDdUlElt)
print("ddUlEltList=", ddUlEltList)
fullModelNameList = []
for curIdx in range(groupCount):
curGroupTitle = dtTextList[curIdx]
print("------[%d] %s" % (curIdx, curGroupTitle))
for eachLiAElt in ddUlEltList[curIdx].items("li a"):
# curModelName = eachLiAElt.text()
curModelName = eachLiAElt.contents()[0]
print("curModelName=", curModelName)
curFullModelName = curGroupTitle + " " + curModelName
print("curFullModelName=", curFullModelName)
fullModelNameList.append(curFullModelName)
print("fullModelNameList=", fullModelNameList)
allSerieDictList = []
for eachFullModelName in fullModelNameList:
curSerieDict = {
"品牌": mainBrandDict["text"],
"子品牌": subBrandDict["text"],
"车系": brandSerieDict["text"],
"车型": eachFullModelName
}
allSerieDictList.append(curSerieDict)
print("allSerieDictList=", allSerieDictList)
return allSerieDictList
</code>能返回所需要的json对象了:
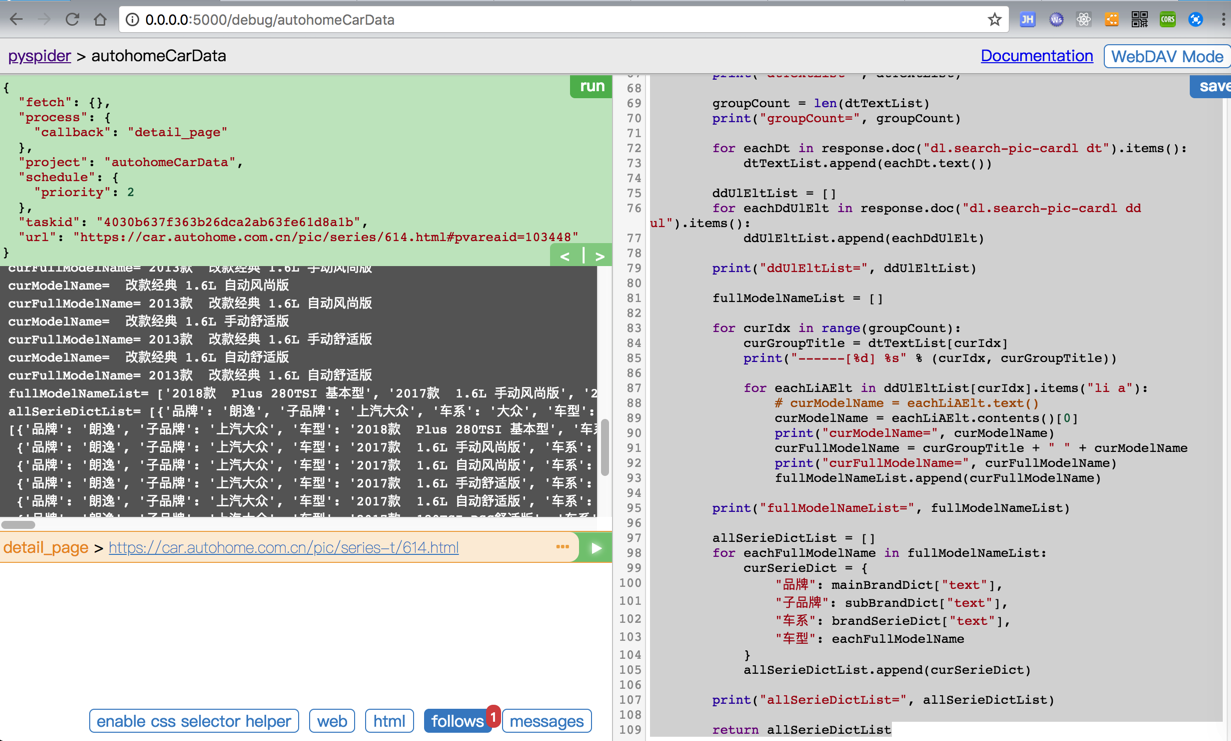
接着就是去:
如何把结果保存为csv或excel
【已解决】PySpider如何把json结果数据保存到csv或excel文件中
【已解决】PySpider中如何清空之前运行的数据和正在运行的任务
然后刚才由于用了debug模式,还真的是:
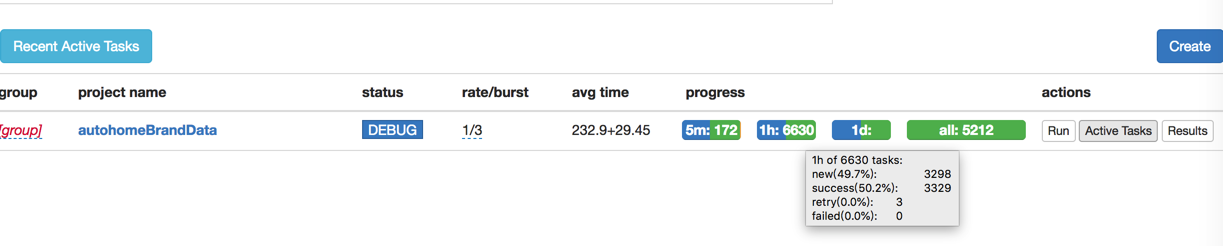
对于遇到一个出错的:
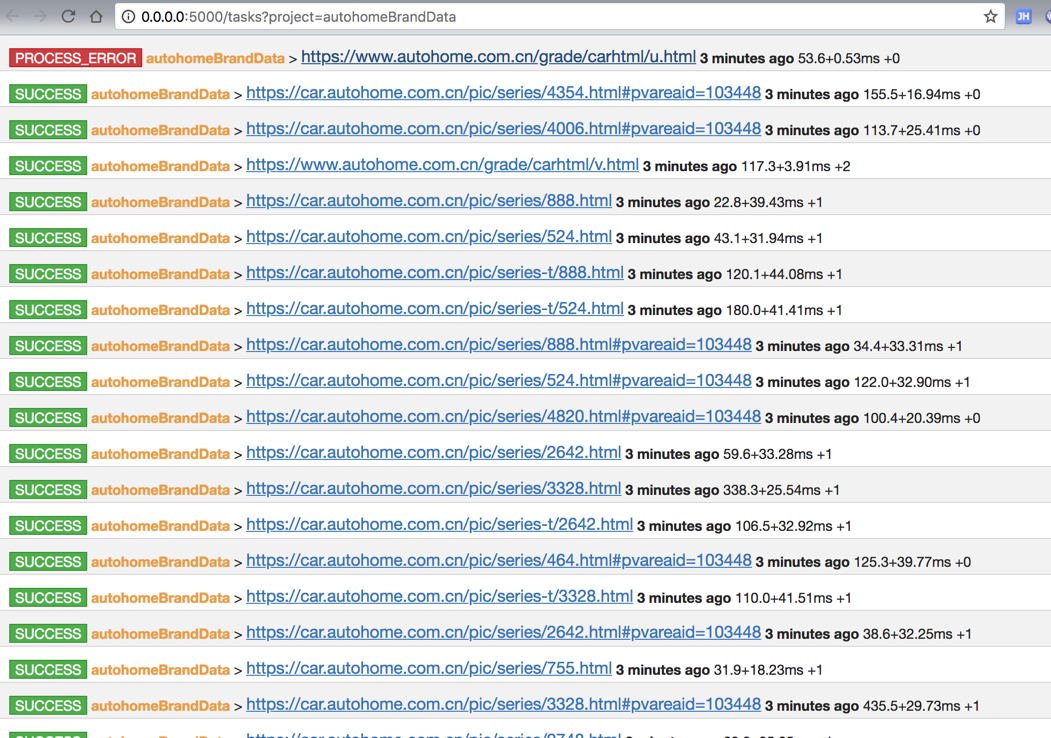
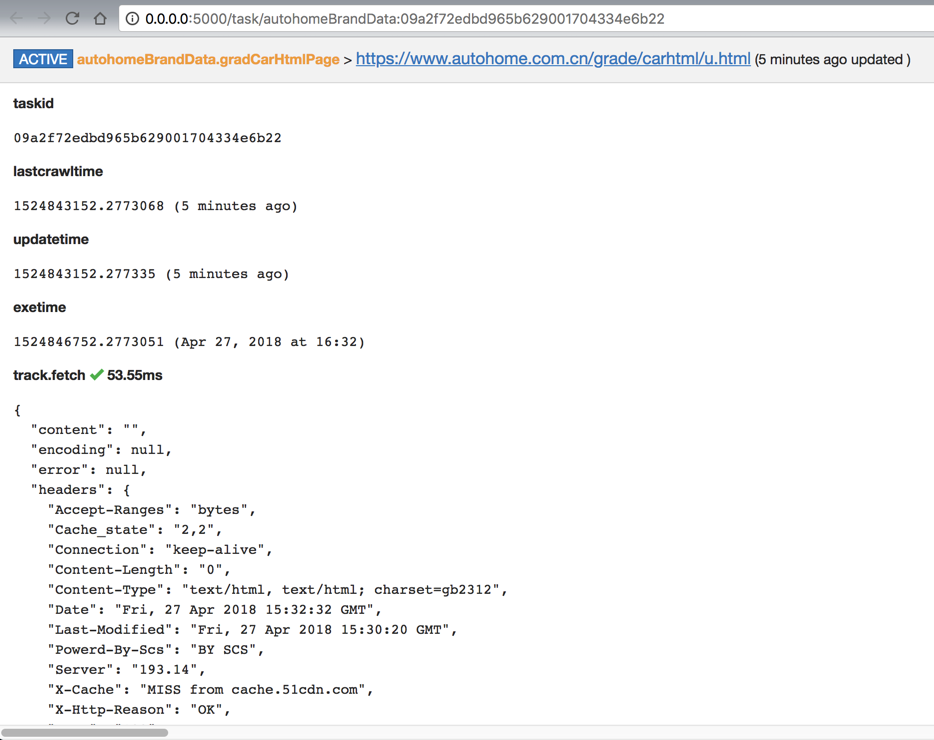
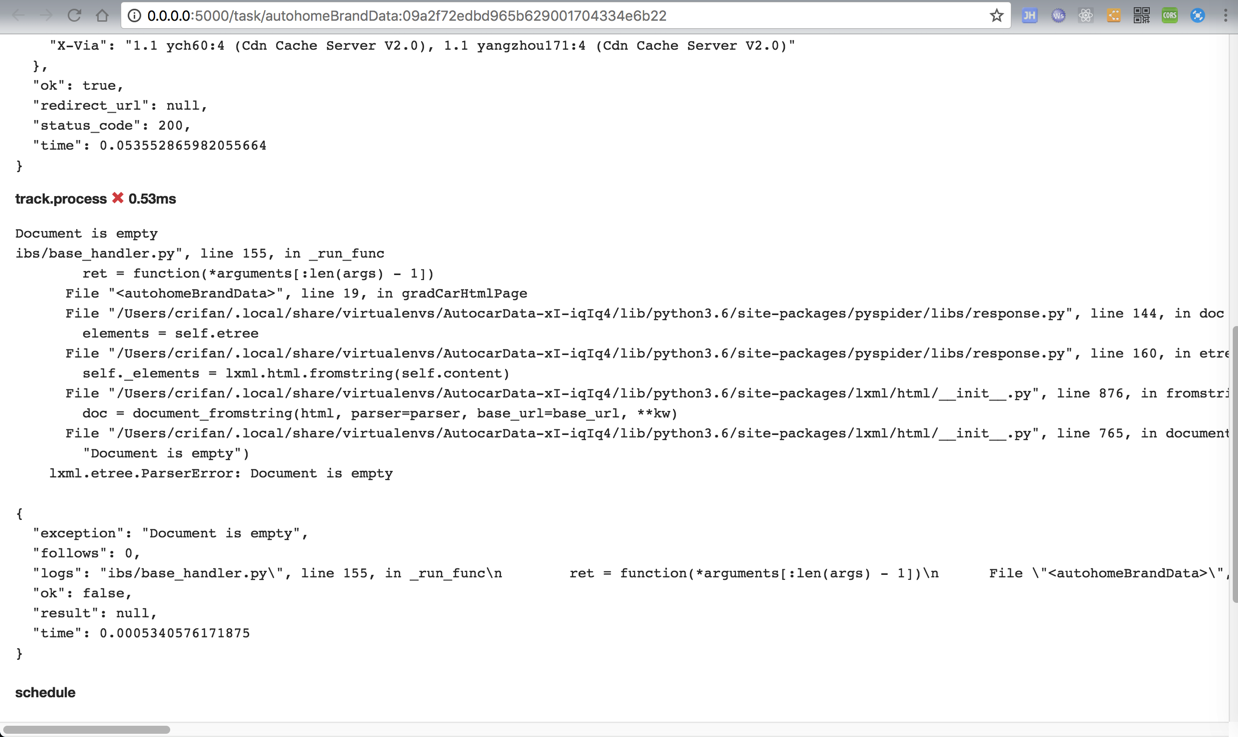
很明显,出错了:
<code>track.process 0.53ms
Document is empty ibs/base_handler.py", line 155, in _run_func ret = function(*arguments[:len(args) - 1]) File "<autohomeBrandData>", line 19, in gradCarHtmlPage File "/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/pyspider/libs/response.py", line 144, in doc elements = self.etree File "/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/pyspider/libs/response.py", line 160, in etree self._elements = lxml.html.fromstring(self.content) File "/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/lxml/html/__init__.py", line 876, in fromstring doc = document_fromstring(html, parser=parser, base_url=base_url, **kw) File "/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/lxml/html/__init__.py", line 765, in document_fromstring "Document is empty") lxml.etree.ParserError: Document is empty { "exception": "Document is empty", "follows": 0, "logs": "ibs/base_handler.py\", line 155, in _run_func\n ret = function(*arguments[:len(args) - 1])\n File \"<autohomeBrandData>\", line 19, in gradCarHtmlPage\n File \"/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/pyspider/libs/response.py\", line 144, in doc\n elements = self.etree\n File \"/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/pyspider/libs/response.py\", line 160, in etree\n self._elements = lxml.html.fromstring(self.content)\n File \"/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/lxml/html/__init__.py\", line 876, in fromstring\n doc = document_fromstring(html, parser=parser, base_url=base_url, **kw)\n File \"/Users/crifan/.local/share/virtualenvs/AutocarData-xI-iqIq4/lib/python3.6/site-packages/lxml/html/__init__.py\", line 765, in document_fromstring\n \"Document is empty\")\n lxml.etree.ParserError: Document is empty\n", "ok": false, "result": null, "time": 0.0005340576171875 }
</code>此处debug模式,导致后续不继续运行了。
后来又去调试了代码,用如下代码:
<code>#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-04-27 21:53:02
# Project: autohomeBrandData
from pyspider.libs.base_handler import *
import string
import re
class Handler(BaseHandler):
crawl_config = {
}
# @every(minutes=24 * 60)
def on_start(self):
for eachLetter in list(string.ascii_lowercase):
self.crawl("https://www.autohome.com.cn/grade/carhtml/%s.html" % eachLetter, callback=self.gradCarHtmlPage)
@catch_status_code_error
def gradCarHtmlPage(self, response):
print("gradCarHtmlPage: response=", response)
picSeriesItemList = response.doc('.rank-list-ul li div a[href*="/pic/series"]').items()
print("picSeriesItemList=", picSeriesItemList)
# print("len(picSeriesItemList)=%s"%(len(picSeriesItemList)))
for each in picSeriesItemList:
self.crawl(each.attr.href, callback=self.picSeriesPage)
@config(priority=2)
def picSeriesPage(self, response):
# <a href="/pic/series-t/66.html">查看停产车型&nbsp;&gt;</a>
# <a class="ckmore" href="/pic/series/588.html">查看在售车型&nbsp;&gt;</a>
# <span class="fn-right">&nbsp;</span>
fnRightPicSeries = response.doc('.search-pic-tbar .fn-right a[href*="/pic/series"]')
print("fnRightPicSeries=", fnRightPicSeries)
if fnRightPicSeries:
# hrefValue = fnRightPicSeries.attr.href
# print("hrefValue=", hrefValue)
# fullPicSeriesUrl = "https://car.autohome.com.cn" + hrefValue
fullPicSeriesUrl = fnRightPicSeries.attr.href
print("fullPicSeriesUrl=", fullPicSeriesUrl)
self.crawl(fullPicSeriesUrl, callback=self.picSeriesPage)
# contine parse brand data
aDictList = []
# for eachA in response.doc('.breadnav a[href^="/"]').items():
for eachA in response.doc('.breadnav a[href*="/pic/"]').items():
eachADict = {
"text" : eachA.text(),
"href": eachA.attr.href
}
print("eachADict=", eachADict)
aDictList.append(eachADict)
print("aDictList=", aDictList)
mainBrandDict = aDictList[-3]
subBrandDict = aDictList[-2]
brandSerieDict = aDictList[-1]
print("mainBrandDict=%s, subBrandDict=%s, brandSerieDict=%s"%(mainBrandDict, subBrandDict, brandSerieDict))
dtTextList = []
for eachDt in response.doc("dl.search-pic-cardl dt").items():
dtTextList.append(eachDt.text())
print("dtTextList=", dtTextList)
groupCount = len(dtTextList)
print("groupCount=", groupCount)
for eachDt in response.doc("dl.search-pic-cardl dt").items():
dtTextList.append(eachDt.text())
ddUlEltList = []
for eachDdUlElt in response.doc("dl.search-pic-cardl dd ul").items():
ddUlEltList.append(eachDdUlElt)
print("ddUlEltList=", ddUlEltList)
modelDetailDictList = []
for curIdx in range(groupCount):
curGroupTitle = dtTextList[curIdx]
print("------[%d] %s" % (curIdx, curGroupTitle))
for eachLiAElt in ddUlEltList[curIdx].items("li a"):
# 1. model name
# curModelName = eachLiAElt.text()
curModelName = eachLiAElt.contents()[0]
curModelName = curModelName.strip()
print("curModelName=", curModelName)
curFullModelName = curGroupTitle + " " + curModelName
print("curFullModelName=", curFullModelName)
# 2. model id + carSeriesId + spec url
curModelId = ""
curSeriesId = ""
curModelSpecUrl = ""
modelSpecUrlTemplate = "https://www.autohome.com.cn/spec/%s/#pvareaid=2042128"
curModelPicUrl = eachLiAElt.attr.href
print("curModelPicUrl=", curModelPicUrl)
#https://car.autohome.com.cn/pic/series-s32708/3457.html#pvareaid=2042220
foundModelSeriesId = re.search("pic/series-s(?P<curModelId>\d+)/(?P<curSeriesId>\d+)\.html", curModelPicUrl)
print("foundModelSeriesId=", foundModelSeriesId)
if foundModelSeriesId:
curModelId = foundModelSeriesId.group("curModelId")
curSeriesId = foundModelSeriesId.group("curSeriesId")
print("curModelId=%s, curSeriesId=%s", curModelId, curSeriesId)
curModelSpecUrl = (modelSpecUrlTemplate) % (curModelId)
print("curModelSpecUrl=", curModelSpecUrl)
# 3. model status
modelStatus = "在售"
foundStopSale = eachLiAElt.find('i[class*="icon-stopsale"]')
if foundStopSale:
modelStatus = "停售"
else:
foundWseason = eachLiAElt.find('i[class*="icon-wseason"]')
if foundWseason:
modelStatus = "未上市"
modelDetailDictList.append({
"url": curModelSpecUrl,
"车系ID": curSeriesId,
"车型ID": curModelId,
"车型": curFullModelName,
"状态": modelStatus
})
print("modelDetailDictList=", modelDetailDictList)
allSerieDictList = []
for curIdx, eachModelDetailDict in enumerate(modelDetailDictList):
curSerieDict = {
"品牌": mainBrandDict["text"],
"子品牌": subBrandDict["text"],
"车系": brandSerieDict["text"],
"车系ID": eachModelDetailDict["车系ID"],
"车型": eachModelDetailDict["车型"],
"车型ID": eachModelDetailDict["车型ID"],
"状态": eachModelDetailDict["状态"]
}
allSerieDictList.append(curSerieDict)
# print("before send_message: [%d] curSerieDict=%s" % (curIdx, curSerieDict))
# self.send_message(self.project_name, curSerieDict, url=eachModelDetailDict["url"])
print("[%d] curSerieDict=%s" % (curIdx, curSerieDict))
self.crawl(eachModelDetailDict["url"], callback=self.carModelSpecPage, save=curSerieDict)
# print("allSerieDictList=", allSerieDictList)
# return allSerieDictList
#def on_message(self, project, msg):
# print("on_message: msg=", msg)
# return msg
@catch_status_code_error
def carModelSpecPage(self, response):
print("carModelSpecPage: response=", response)
# https://www.autohome.com.cn/spec/32708/#pvareaid=2042128
curSerieDict = response.save
print("curSerieDict", curSerieDict)
# cityDealerPriceInt = 0
# cityDealerPriceElt = response.doc('.cardetail-infor-price #cityDealerPrice span span[class*="price"]')
# print("cityDealerPriceElt=%s" % cityDealerPriceElt)
# if cityDealerPriceElt:
# cityDealerPriceFloatStr = cityDealerPriceElt.text()
# print("cityDealerPriceFloatStr=", cityDealerPriceFloatStr)
# cityDealerPriceFloat = float(cityDealerPriceFloatStr)
# print("cityDealerPriceFloat=", cityDealerPriceFloat)
# cityDealerPriceInt = int(cityDealerPriceFloat * 10000)
# print("cityDealerPriceInt=", cityDealerPriceInt)
msrpPriceInt = 0
# body > div.content > div.row > div.column.grid-16 > div.cardetail.fn-clear > div.cardetail-infor > div.cardetail-infor-price.fn-clear > ul > li.li-price.fn-clear > span
# 厂商指导价=厂商建议零售价格=MSRP=Manufacturer's suggested retail price
msrpPriceElt = response.doc('.cardetail-infor-price li[class*="li-price"] span[data-price]')
print("msrpPriceElt=", msrpPriceElt)
if msrpPriceElt:
msrpPriceStr = msrpPriceElt.attr("data-price")
print("msrpPriceStr=", msrpPriceStr)
foundMsrpPrice = re.search("(?P<msrpPrice>[\d\.]+)万元", msrpPriceStr)
print("foundMsrpPrice=", foundMsrpPrice)
if foundMsrpPrice:
msrpPrice = foundMsrpPrice.group("msrpPrice")
print("msrpPrice=", msrpPrice)
msrpPriceFloat = float(msrpPrice)
print("msrpPriceFloat=", msrpPriceFloat)
msrpPriceInt = int(msrpPriceFloat * 10000)
print("msrpPriceInt=", msrpPriceInt)
# curSerieDict["经销商参考价"] = cityDealerPriceInt
curSerieDict["厂商指导价"] = msrpPriceInt
return curSerieDict
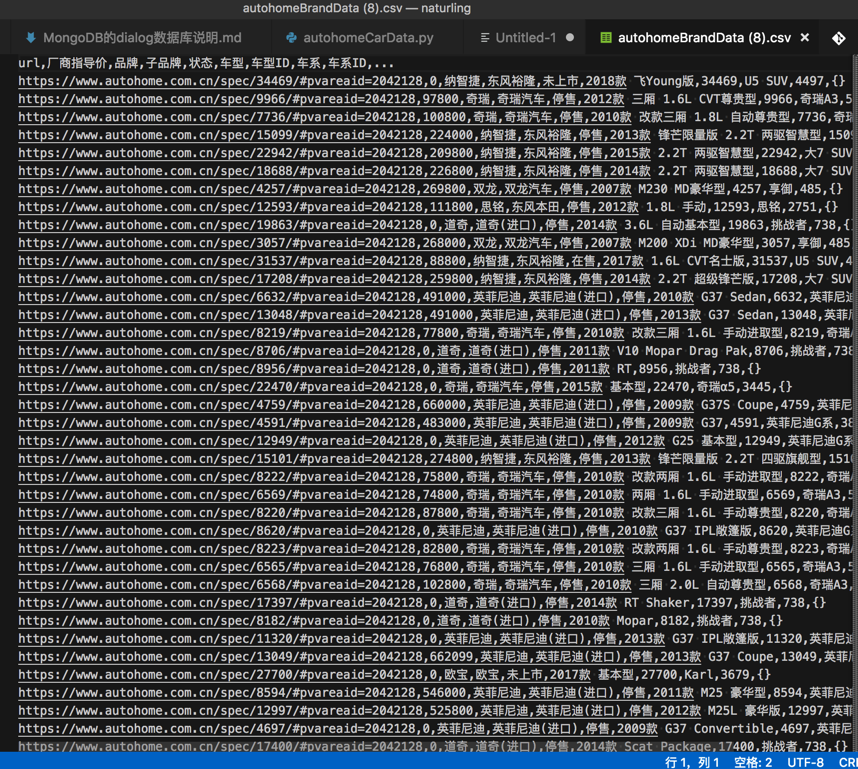
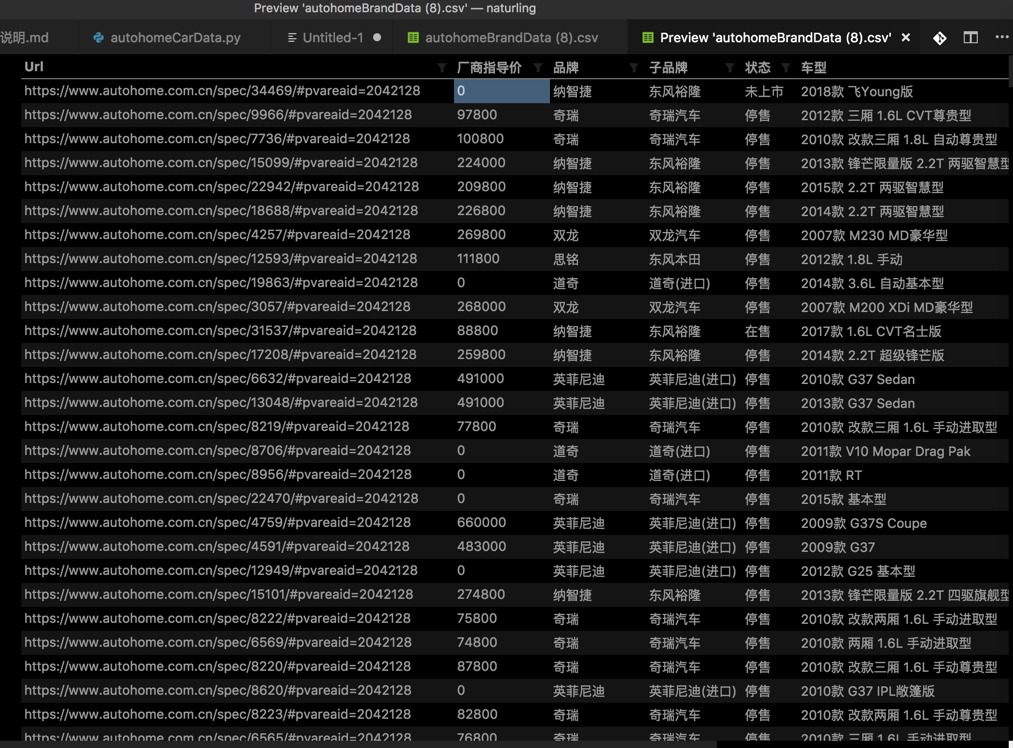
</code>运行后,点击导出的csv:
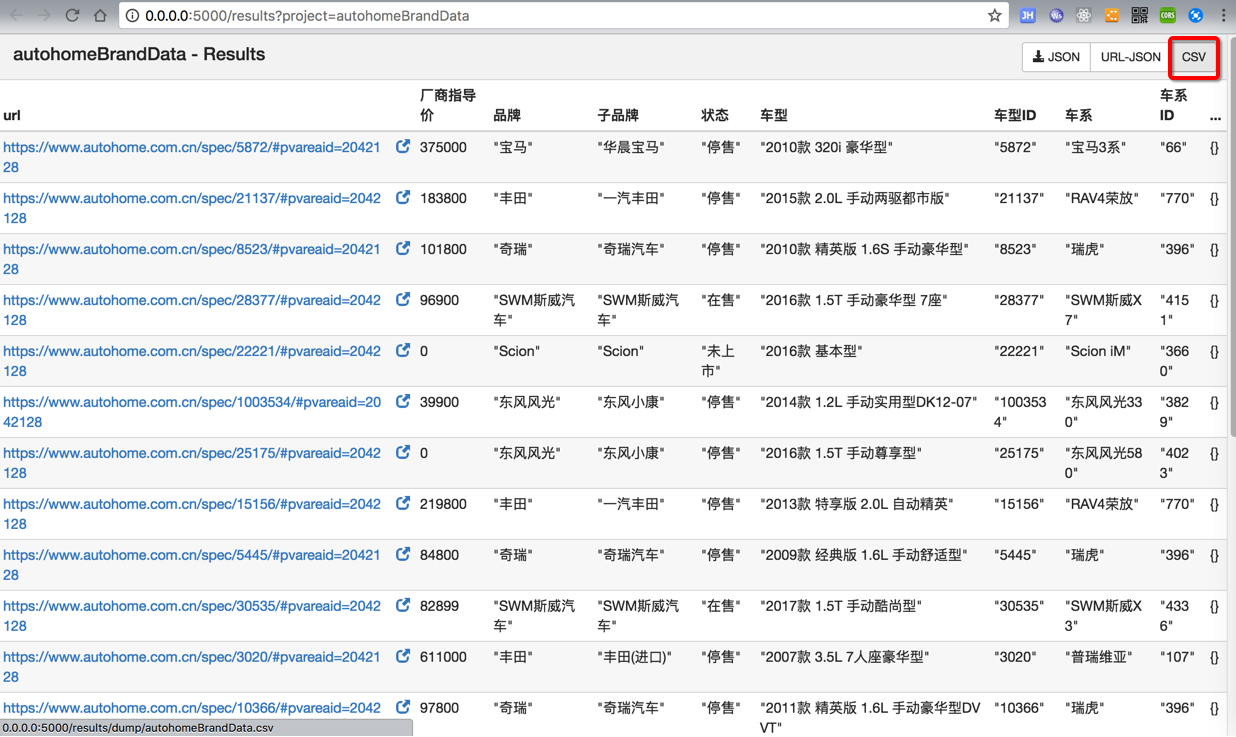
保存出如下结果:
转载请注明:在路上 » 【已解决】写Python爬虫爬取汽车之家品牌车系车型数据