折腾:
期间,需要先去参考官网资料,用api测试工具,不如postman,先去测试是否能正常调用api。
回到:
https://azure.microsoft.com/zh-cn/services/cognitive-services/speech/
-》
https://azure.microsoft.com/zh-cn/try/cognitive-services/?api=speech-api
https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/
中的例子:
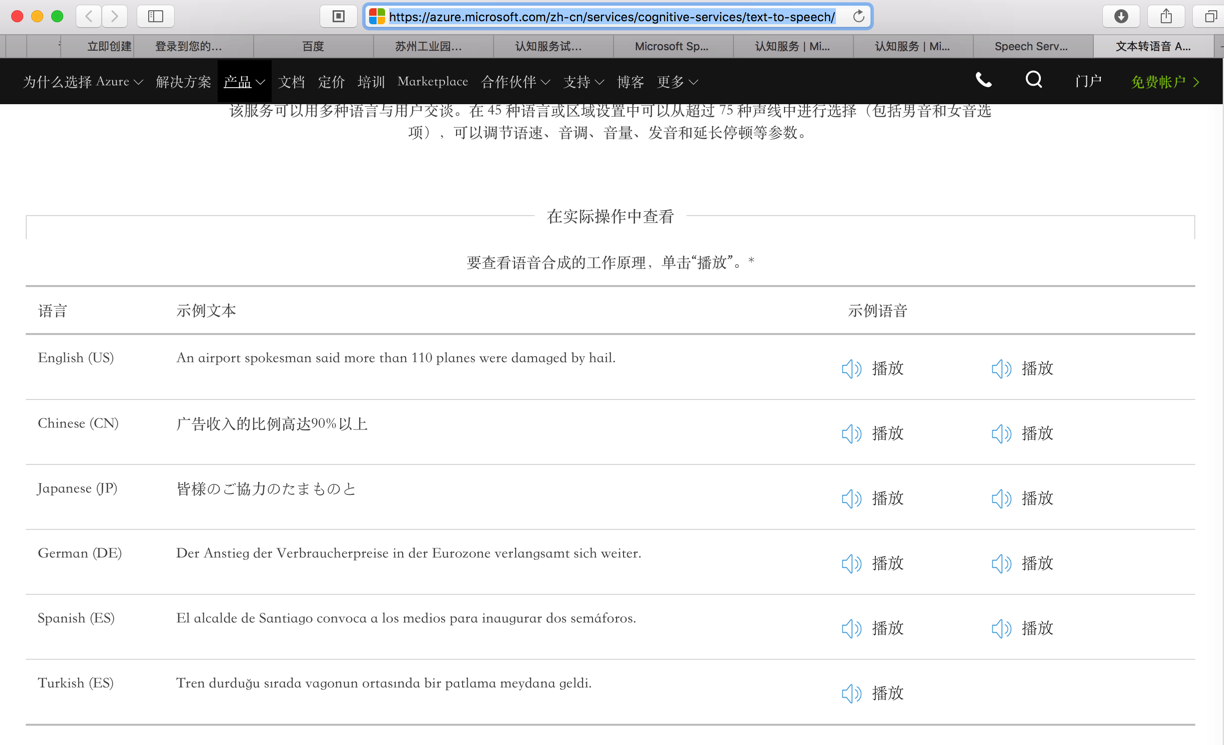
听起来,还凑合
大概搞懂了,那就先去试试:
语音服务 预览版
的
Use Text to Speech using Speech services – Microsoft Cognitive Services | Microsoft Docs
用接口,调用参数,需要使用SSML:
The Speech Synthesis Markup Language – Microsoft Cognitive Services | Microsoft Docs
也还要认证:
subscription key or a token
api选:
https://eastasia.tts.speech.microsoft.com/cognitiveservices/v1
去这里找支持的语言:
去这里看,如何获取验证:
Speech service REST APIs | Microsoft Docs
去访问:
https://eastasia.api.cognitive.microsoft.com/sts/v1.0/issueToken
虽然试了试一个密钥,结果出错:
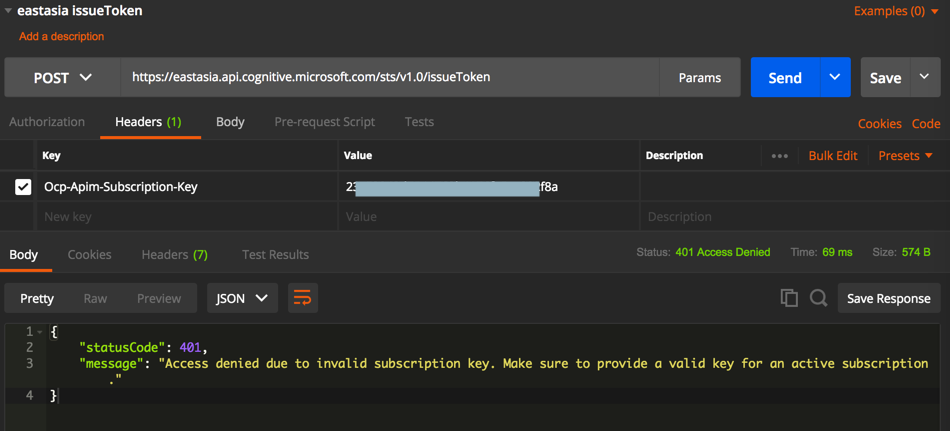
然后才注意到:
系统免费分配的api是westus的:

所以去换api的url
终结点: https://westus.api.cognitive.microsoft.com/sts/v1.0
然后是可以获取到token的:
POST https://westus.api.cognitive.microsoft.com/sts/v1.0/issueToken
Ocp-Apim-Subscription-Key:23xxxf8a
eyJ0eXAixxxxgx2s8U
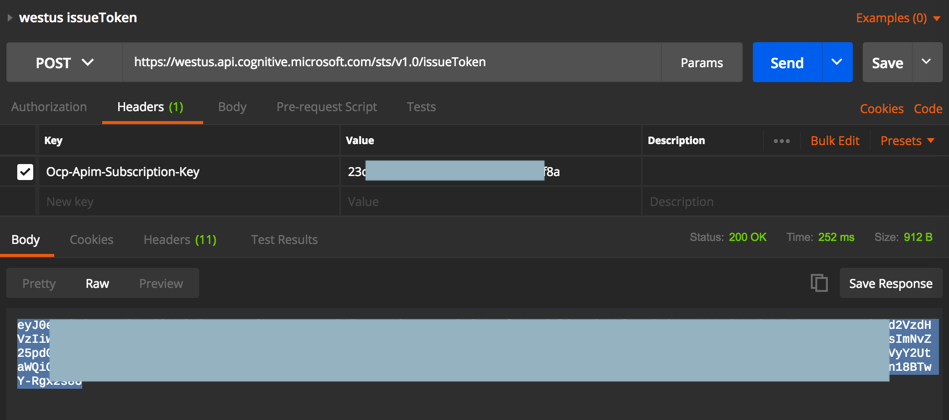
上述返回的就是:
Java Web Token (JWT) format
JWT密钥
后续使用此JWT密钥是:
Authorization: Bearer xxx
去试试
结果返回空的:
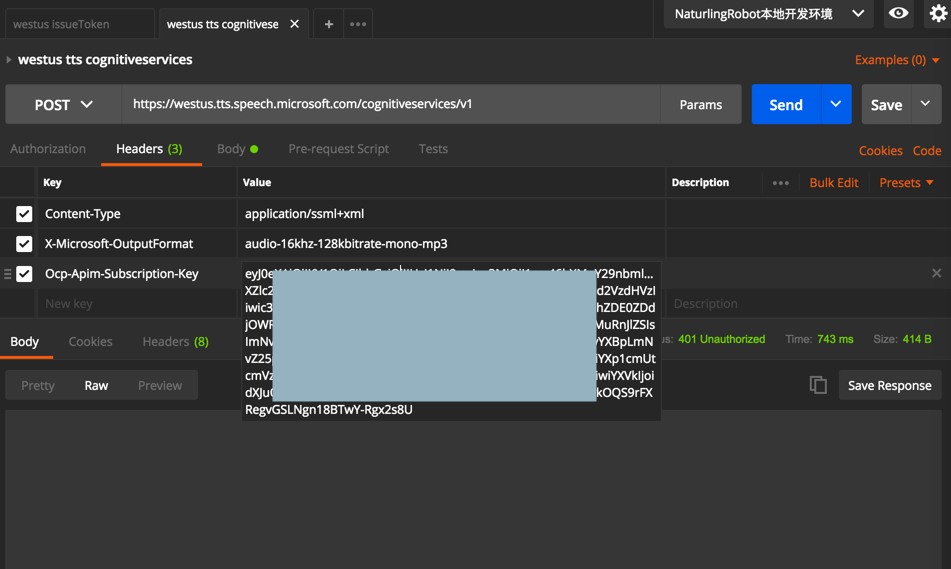
也没报错
加了user-agent后,
看到了,是401
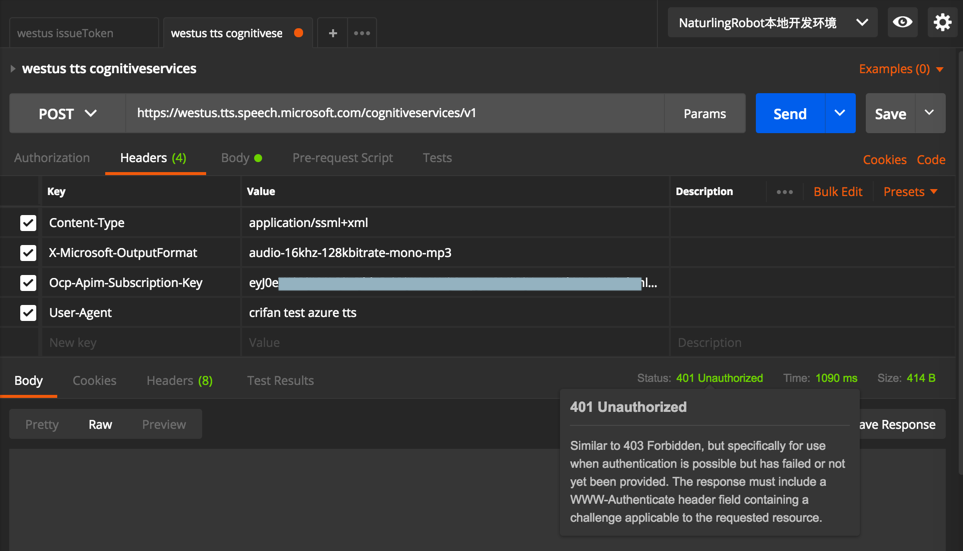
最后终于可以了:
westus tts cognitiveservices
POST https://westus.tts.speech.microsoft.com/cognitiveservices/v1
Content-Type: application/ssml+xml
X-Microsoft-OutputFormat: audio-16khz-128kbitrate-mono-mp3
Ocp-Apim-Subscription-Key: 23cxxxf8a
Authorization: Bearer exxx9.eyxxxJ9.OxxxQ-xxxU
Body:
<speak version=’1.0′ xmlns="http://www.w3.org/2001/10/synthesis" xml:lang=’en-US’>
<voice name=’Microsoft Server Speech Text to Speech Voice (en-US, Jessa24kRUS)’>
<prosody rate="-30.00%" volume="+20.00%">
i feel like you gonna love this story.
</prosody>
</voice>
</speak>
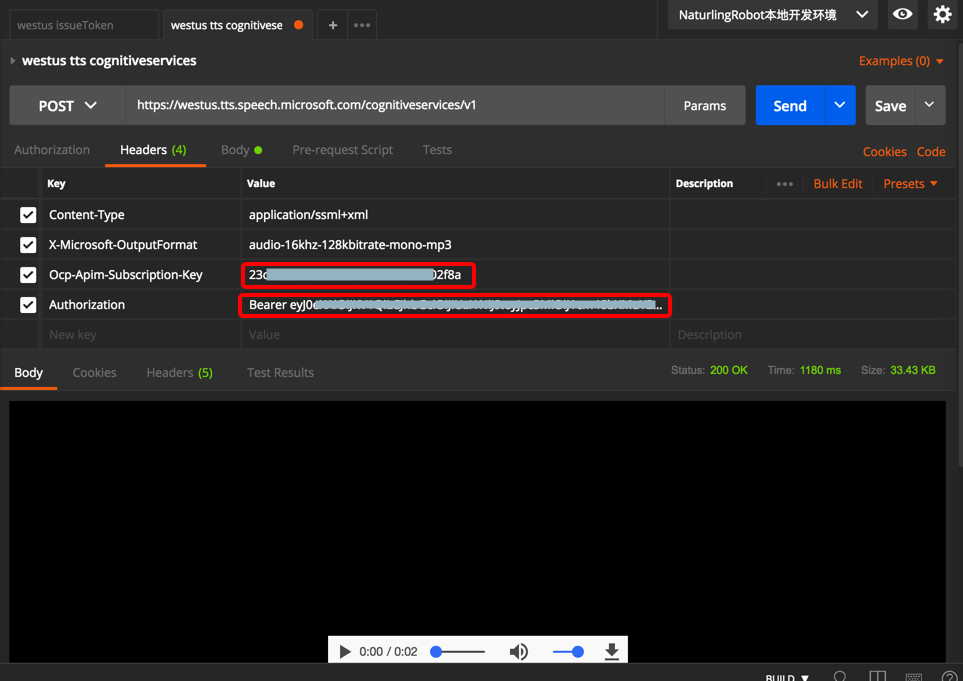
下载下来听了听:
感觉效果还不错
接着去试试别的人声和参数设置
<speak version=’1.0′ xmlns="http://www.w3.org/2001/10/synthesis" xml:lang=’en-US’>
<voice name=’Microsoft Server Speech Text to Speech Voice (en-US, Jessa24kRUS)’>
<prosody rate="-30.00%" volume="+20.00%">
i feel like you gonna love this story.
</prosody>
</voice>
</speak>
提高音量,降低朗读速度
也可以根据:
https://docs.microsoft.com/zh-cn/azure/cognitive-services/speech-service/supported-languages
去换成别的朗读人,比如:
"Microsoft Server Speech Text to Speech Voice (en-GB, Susan, Apollo)"
"Microsoft Server Speech Text to Speech Voice (en-US, ZiraRUS)”
"Microsoft Server Speech Text to Speech Voice (en-US, JessaRUS)"
然后剩下就是怎么集成到自己的Flask程序里了。
【后记】
后来看到:
-》发现SSML
语音合成标记语言(Speech Synthesis Markup Language, SSML)
原来是:
在语音合成领域比较通用的语言
不是微软自己一家的规范。
转载请注明:在路上 » 【已解决】试用微软Azure认知服务中语音服务的接口和效果