折腾:
已经完成了,语音合成到Flask中了。
接着去考虑在前端页面中,支持调用参数给后端,传递到微软的Azure的tts语音合成中。
方便前端测试不同人声的语音合成的效果。
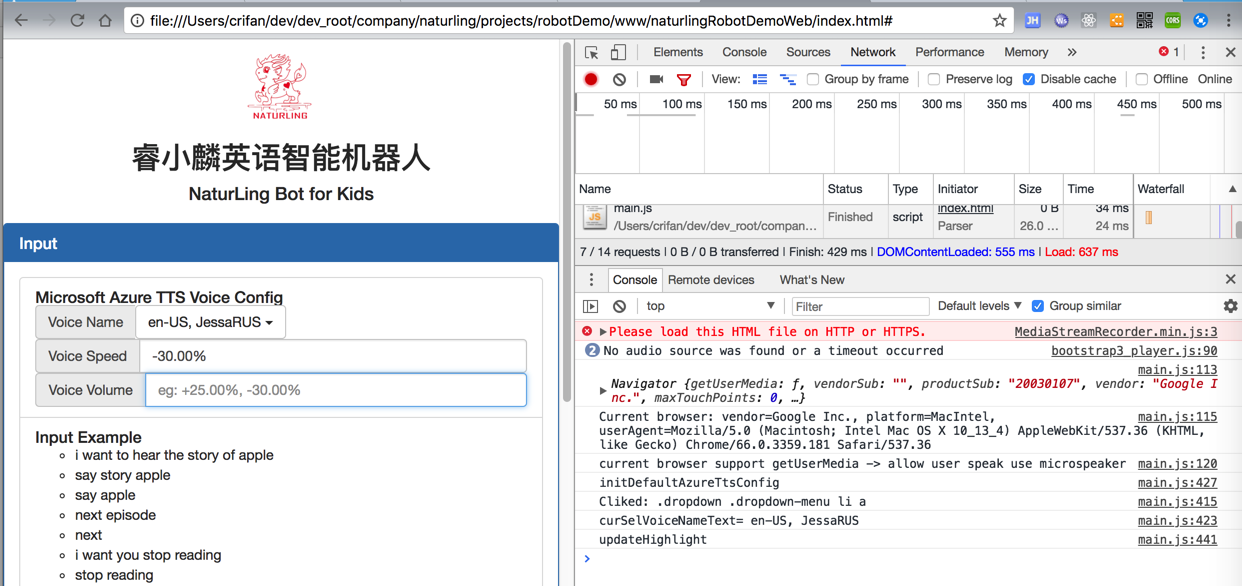
去前端页面中加配置
之前用的bootstrap,找找里面的列表选择控件:
【已解决】Bootstrap中实现列表选择默认值和获取当前选中的值
再去加上其他的配置,比如🔊音量大小和语音速度
<code> <div class="row"> <div class="col-lg-4 col-md-4 col-sm-6 col-xs-12 "> <div class="input-group"> <span class="input-group-addon">Voice Speed</span> <input type="text" class="form-control" placeholder="eg: -40.00%, +20.00%" id="voiceRate" value="-30.00%"> </div> </div> </div> <div class="row"> <div class="col-lg-4 col-md-4 col-sm-6 col-xs-12 "> <div class="input-group"> <span class="input-group-addon">Voice Volume</span> <input type="text" class="form-control" placeholder="eg: +25.00%, -30.00%" id="voiceVolume" value="+40.00%"> </div> </div> </div> </code>
界面效果:
然后再去写更新后台代码,加上ms的azure的tts的参数设置
<code># def doAudioSynthesis(unicodeText):
def doAudioSynthesis(unicodeText,
voiceName=MS_TTS_VOICE_NAME,
voiceRate=MS_TTS_VOICE_RATE,
voiceVolume=MS_TTS_VOICE_VOLUME):
"""
do audio synthesis from unicode text
if failed for token invalid/expired, will refresh token to do one more retry
"""
# global app, log, gCurBaiduRespDict
global app, log
isOk = False
audioBinData = None
errMsg = ""
# # for debug
# gCurBaiduRespDict["access_token"] = "99.569b3b5b470938a522ce60d2e2ea2506.2592000.1528015602.282335-11192483"
log.info("doAudioSynthesis: unicodeText=%s", unicodeText)
# isOk, audioBinData, errNo, errMsg = baiduText2Audio(unicodeText)
isOk, audioBinData, errNo, errMsg = msTTS(unicodeText, voiceName, voiceRate, voiceVolume)
log.info("isOk=%s, errNo=%d, errMsg=%s", isOk, errNo, errMsg)
def msTTS(unicodeText,
voiceName=MS_TTS_VOICE_NAME,
voiceRate=MS_TTS_VOICE_RATE,
voiceVolume=MS_TTS_VOICE_VOLUME):
"""call ms azure tts to generate audio(mp3/wav/...) from text"""
global app, log, gMsToken
log.info("msTTS: unicodeText=%s", unicodeText)
isOk = False
audioBinData = None
errNo = 0
errMsg = "Unknown error"
msTtsUrl = app.config["MS_TTS_URL"]
log.info("msTtsUrl=%s", msTtsUrl)
reqHeaders = {
"Content-Type": "application/ssml+xml",
"X-Microsoft-OutputFormat": MS_TTS_OUTPUT_FORMAT,
"Ocp-Apim-Subscription-Key": app.config["MS_TTS_SECRET_KEY"],
"Authorization": "Bear " + gMsToken
}
log.info("reqHeaders=%s", reqHeaders)
# # for debug
# MS_TTS_VOICE_NAME = "zhang san"
ssmlDataStr = """
<speak version='1.0' xmlns="http://www.w3.org/2001/10/synthesis" xml:lang='en-US'>
<voice name='%s'>
<prosody rate='%s' volume='%s'>
%s
</prosody>
</voice>
</speak>
""" % (voiceName, voiceRate, voiceVolume, unicodeText)
log.info("ssmlDataStr=%s", ssmlDataStr)
resp = requests.post(msTtsUrl, headers=reqHeaders, data=ssmlDataStr)
log.info("resp=%s", resp)
statusCode = resp.status_code
log.info("statusCode=%s", statusCode)
if statusCode == 200:
# respContentType = resp.headers["Content-Type"] # 'audio/x-wav', 'audio/mpeg'
# log.info("respContentType=%s", respContentType)
# if re.match("audio/.*", respContentType):
audioBinData = resp.content
log.info("resp content is audio binary data, length=%d", len(audioBinData))
isOk = True
errMsg = ""
else:
isOk = False
errNo = resp.status_code
errMsg = resp.reason
log.error("resp errNo=%d, errMsg=%s", errNo, errMsg)
# errNo=400, errMsg=Voice zhang san not supported
# errNo=401, errMsg=Unauthorized
# errNo=413, errMsg=Content length exceeded the allowed limit of 1024 characters.
return isOk, audioBinData, errNo, errMsg
class RobotQaAPI(Resource):
def processResponse(self,
respDict,
voiceName=MS_TTS_VOICE_NAME,
voiceRate=MS_TTS_VOICE_RATE,
voiceVolume=MS_TTS_VOICE_VOLUME):
"""
process response dict before return
generate audio for response text part
"""
global log, gTempAudioFolder
unicodeText = respDict["data"]["response"]["text"]
log.info("unicodeText=%s")
if not unicodeText:
log.info("No response text to do audio synthesis")
return jsonify(respDict)
isOk, audioBinData, errMsg = doAudioSynthesis(unicodeText, voiceName, voiceRate, voiceVolume)
if isOk:
# 1. save audio binary data into tmp file
tempFilename = saveAudioDataToTmpFile(audioBinData)
# 2. use celery to delay delete tmp file
delayTimeToDelete = app.config["CELERY_DELETE_TMP_AUDIO_FILE_DELAY"]
deleteTmpAudioFile.apply_async([tempFilename], countdown=delayTimeToDelete)
log.info("Delay %s seconds to delete %s", delayTimeToDelete, tempFilename)
# 3. generate temp audio file url
tmpAudioUrl = "http://%s:%d/tmp/audio/%s" % (
app.config["FILE_URL_HOST"],
app.config["FLASK_PORT"],
tempFilename)
log.info("tmpAudioUrl=%s", tmpAudioUrl)
respDict["data"]["response"]["audioUrl"] = tmpAudioUrl
else:
log.warning("Fail to get synthesis audio for errMsg=%s", errMsg)
log.info("respDict=%s", respDict)
return jsonify(respDict)
def get(self):
respDict = {
"code": 200,
"message": "generate response ok",
"data": {
"input": "",
"response": {
"text": "",
"audioUrl": ""
},
"control": "",
"audio": {}
}
}
parser = reqparse.RequestParser()
# i want to hear the story of Baby Sister Says No
parser.add_argument('input', type=str, help="input words")
parser.add_argument('voiceName', type=str, default=MS_TTS_VOICE_NAME, help="voice name/speaker")
parser.add_argument('voiceRate', type=str, default=MS_TTS_VOICE_RATE, help="voice rate/speed")
parser.add_argument('voiceVolume', type=str, default=MS_TTS_VOICE_VOLUME, help="voice volume")
log.info("parser=%s", parser)
parsedArgs = parser.parse_args()
log.info("parsedArgs=%s", parsedArgs)
if not parsedArgs:
respDict["data"]["response"]["text"] = "Can not recognize input"
return self.processResponse(respDict)
inputStr = parsedArgs["input"]
voiceName = parsedArgs["voiceName"]
voiceRate = parsedArgs["voiceRate"]
voiceVolume = parsedArgs["voiceVolume"]
log.info("inputStr=%s, voiceName=%s, voiceRate=%s, voiceVolume=%s",
inputStr, voiceName, voiceRate, voiceVolume)
if not inputStr:
respDict["data"]["response"]["text"] = "Can not recognize parameter input"
return self.processResponse(respDict, voiceName, voiceRate, voiceVolume)
respDict["data"]["input"] = inputStr
aiResult = QueryAnalyse(inputStr, aiContext)
log.info("aiResult=%s", aiResult)
if aiResult["response"]:
respDict["data"]["response"]["text"] = aiResult["response"]
if aiResult["control"]:
respDict["data"]["control"] = aiResult["control"]
log.info('respDict["data"]=%s', respDict["data"])
audioFileIdStr = aiResult["mediaId"]
log.info("audioFileIdStr=%s", audioFileIdStr)
if audioFileIdStr:
audioFileObjectId = ObjectId(audioFileIdStr)
log.info("audioFileObjectId=%s", audioFileObjectId)
if fsCollection.exists(audioFileObjectId):
audioFileObj = fsCollection.get(audioFileObjectId)
log.info("audioFileObj=%s", audioFileObj)
encodedFilename = quote(audioFileObj.filename)
log.info("encodedFilename=%s", encodedFilename)
respDict["data"]["audio"] = {
"contentType": audioFileObj.contentType,
"name": audioFileObj.filename,
"size": audioFileObj.length,
"url": "http://%s:%d/files/%s/%s" %
(app.config["FILE_URL_HOST"],
app.config["FLASK_PORT"],
audioFileObj._id,
encodedFilename)
}
log.info("respDict=%s", respDict)
return self.processResponse(respDict, voiceName, voiceRate, voiceVolume)
else:
log.info("Can not find file from id %s", audioFileIdStr)
respDict["data"]["audio"] = {}
return self.processResponse(respDict, voiceName, voiceRate, voiceVolume)
else:
log.info("Not response file id")
respDict["data"]["audio"] = {}
return self.processResponse(respDict, voiceName, voiceRate, voiceVolume)
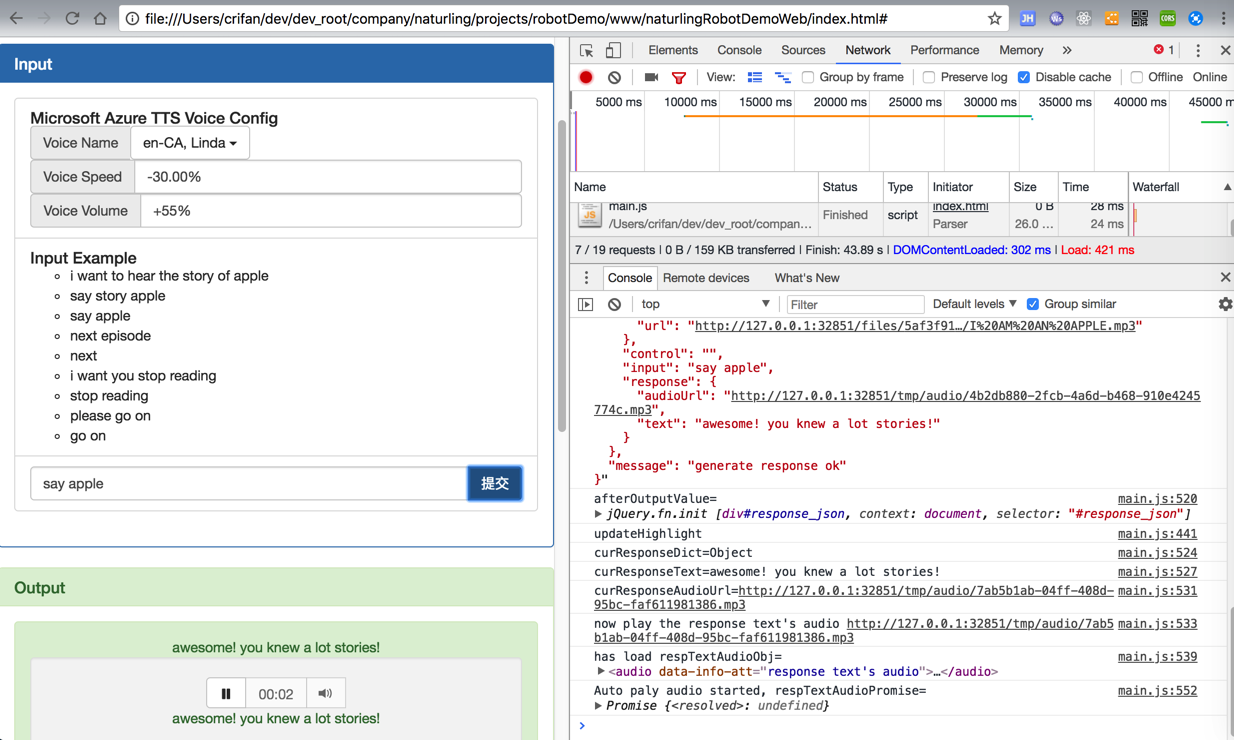
</code>效果:
是可以实现,设置不同参数,输出对应合成的语音的:
然后再去部署代码到服务器上即可。