折腾:
期间,已经:
接着要去搞清楚:
对于pdf文件,srt字幕文本文件,mp3音频文件,如何存储到mongodb中。
mongodb 保存音频文件
MongoDB结合Spring存储文件(图片、音频等等)_数据库技术_Linux公社-Linux系统门户网站
说是超过16M的才是用GridFS存
而此处很多音频,pdf等文件,没有超过16M,有的超过了:
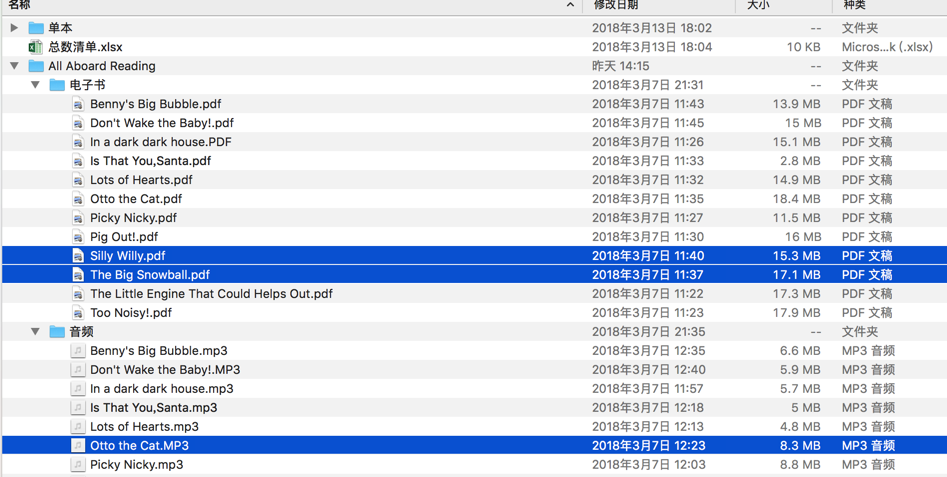
且希望用统一的方式存储
Mongodb与GridFS – 深入一点,你会更加快乐 – ITeye博客
GridFS – Mongodb 教程 – 极客学院Wiki
MongoDB篇——Java Maven项目中使用MongoDB GridFS上传音频图片 – CSDN博客
【MongoDB】6.关于MongoDB存储文件的 命令执行+代码执行 – Angel挤一挤 – 博客园
“ GridFS存储文件可超过文件大小限制为16MB的功能。”
第7回 GridFS——在MongoDB中保存大容量文件的方法 | 诗檀学院博客
“能在MongoDB中保存的Document尺寸一般有最大16Mbyte的限制。这对于保存一般的文本文件是非常足够的尺寸,但要保存一些巨大的文本文件以及视频等Binary data时,就会出现超出16Mbyte的情况。想在MongoDB中保存16Mbyte以上的文件时,通过使用GridFS这种接口,可以将数据进行多个分割来进行保存。”
所以看起来是:
此处对于pdf,mp3等,即使小于16MB,为了统一存储方式,也还是都用GridFS吧。
mongodb gridfs 存储文件
GridFS 基于MongoDB的分布式文件存储系统 | 梁桂钊的博客
<code>> show collections testCollection > db.fs.files.findOne() null </code>
还是没有解释,如何用GridFS去保存文件
mongodb gridfs to store file
GridFS – Mongodb 教程 – 极客学院Wiki
通过tab可以看到此处有mongofiles:
<code>➜ ~ mongo mongo mongodump mongofiles mongoperf mongorestore mongostat mongod mongoexport mongoimport mongoreplay mongos mongotop </code>
什么时候才需要去用GridFS去存储文件数据:
文件大小超过16MB
MongoDB本身基于的document是基于BSON的,最大只支持16MB
超过16MB,无法直接高效率的保存
文件所在文件系统对文件个数有限制(比如不能超过1000个之类的)
用GridFS可以存储任意个数的文件
需要读取访问大文件中的某段数据
传统方式:需要加载整个文件到内存中,接着才能读取其中指定的部分数据
GridFS:无需加载整个文件,可以高效的实现,类似于seek去定位,读取某段数据
希望文件和原数据在物理上存储在多个不同地方,且又希望实时保证同步
GridFS支持物理上地分布式存储和自动保持同步
不要,不建议,用GridFS:
去存储那些,每次操作都是针对文件的整个内容的操作
-》否则换用GridFS,并不能提高效率
文件大小小于16MB
直接用MongoDB存即可
用GridFS去保存文件的话有2种方式:
driver
命令行工具:mongofiles
不同系统文件不同
Windows:mongofiles.exe
Linux类系统,包括Mac:mongofiles
which mongofiles
/usr/local/bin/mongofiles
方式:
chunks:存二进制数据块
默认chunk大小255KB
默认用:fs.files
files:存储文件的原数据(描述信息)
默认用:fs.chunks
此处的fs被称为bucket
还是去试试再说
去实际操作试试
结果由于路径问题,无法存入:
<code>➜ 英语资源 mongofiles -d gridfs put "/Users/crifan/dev/dev_root/company/xxx/数据/xx/英语资源/All\ Aboard\ Reading/音频/Otto\ the\ Cat.MP3" 2018-03-28T14:25:01.763+0800 connected to: localhost 2018-03-28T14:25:01.765+0800 Failed: error while opening local file '/Users/crifan/dev/dev_root/company/xxx/数据/xxx/英语资源/All\ Aboard\ Reading/音频/Otto\ the\ Cat.MP3' : open /Users/crifan/dev/dev_root/company/xx/数据/xx/英语资源/All\ Aboard\ Reading/音频/Otto\ the\ Cat.MP3: no such file or directory </code>
mongofiles no such file or directory
通过ll发现:
<code>➜ 英语资源 ll All\ Aboard\ Reading/音频/Otto\ the\ Cat.MP3 -rwxr-xr-x 1 crifan staff 8.0M 3 7 12:23 All Aboard Reading/音频/Otto the Cat.MP3 </code>
把反斜杠去掉即可:
<code>➜ 英语资源 mongofiles -d gridfs put "/Users/crifan/dev/dev_root/company/xx/数据/xx/英语资源/All Aboard Reading/音频/Otto the Cat.MP3" 2018-03-28T14:43:08.463+0800 connected to: localhost added file: /Users/crifan/dev/dev_root/company/xx/数据/xx/英语资源/All Aboard Reading/音频/Otto the Cat.MP3 </code>
然后就可以去搜出来文件了:
<code>
> db.fs.files.find()
{ "_id" : ObjectId("5abb397ca4bc71fc7d71c7bd"), "chunkSize" : 261120, "uploadDate" : ISODate("2018-03-28T06:43:08.613Z"), "length" : 8338105, "md5" : "b7660d833085e9e1a21813e4d74b0cc3", "filename" : "/Users/crifan/dev/dev_root/company/xx/x/英语资源/All Aboard Reading/音频/Otto the Cat.MP3" }
> db.fs.files.find().pretty()
{
"_id" : ObjectId("5abb397ca4bc71fc7d71c7bd"),
"chunkSize" : 261120,
"uploadDate" : ISODate("2018-03-28T06:43:08.613Z"),
"length" : 8338105,
"md5" : "b7660d833085e9e1a21813e4d74b0cc3",
"filename" : "/Users/crifan/dev/dev_root/xxx/英语资源/All Aboard Reading/音频/Otto the Cat.MP3"
}
</code>然后去找chunks:
<code>> db.fs.chunks.find({files_id: "5abb397ca4bc71fc7d71c7bd"})
</code>发现要带上ObjectId才能搜出来:
<code>> db.fs.chunks.find({files_id: ObjectId("5abb397ca4bc71fc7d71c7bd")})
</code>但是:
【已解决】MongoDB的GridFS中只返回file的chunks的个数而不返回chunks.data
再去下载文件:
【已解决】MongoDB的GridFS中基于文件名或id去下载文件
顺带也看到了:
“–type <MIME>¶
Provides the ability to specify a MIME type to describe the file inserted into GridFS storage. mongofiles omits this option in the default operation.
Use only with mongofiles put operations.”
再去试试–type
mongofiles – MongoDB GridFS Utility – Linux Man Pages (1)
“–type <MIME>
Provides the ability to specify a MIME type to describe the file inserted into GridFS storage. mongofiles omits this option in the default operation.
Use only with mongofiles put operations.”
只能用于put操作。
而需要先去找找确定的MIME的写法:
然后就可以去试试,加上MIME了:
<code>➜ 英语资源 mongofiles -d gridfs put "Otto the Cat-withMIME.MP3" --type audio/mpeg --replace --local "/Users/crifan/dev/dev_root/xxx/英语资源/All Aboard Reading/音频/Otto the Cat.MP3" 2018-03-29T09:38:44.765+0800 connected to: localhost 2018-03-29T09:38:44.775+0800 removed all instances of 'Otto the Cat-withMIME.MP3' from GridFS added file: Otto the Cat-withMIME.MP3 </code>
效果:
<code>> db.fs.files.find().pretty()
{
"_id" : ObjectId("5abc43a4a4bc712159a35cd9"),
"chunkSize" : 261120,
"uploadDate" : ISODate("2018-03-29T01:38:44.853Z"),
"length" : 8338105,
"md5" : "b7660d833085e9e1a21813e4d74b0cc3",
"filename" : "Otto the Cat-withMIME.MP3",
"contentType" : "audio/mpeg"
}
</code>再去试试删除文件:
然后再去:
【无法也无须解决】用mongofiles给GridFS中添加文件时添加额外参数属性字段
那就后续折腾API的时候,再去保存额外参数。
然后可以开始去折腾写Python代码,去调用gridfs去保存文件了,且可以同时去保存额外参数了:
【已解决】用Python去连接本地mongoDB去用GridFS保存文件
然后接着要去:
【已解决】python解析excel文件并读取其中的sheet和row和column的值
然后接着就是去调试代码,保存本地的所有的音频文件到本地的mongoDB中了:
metadata数据如下:
有unicode,有list,有None
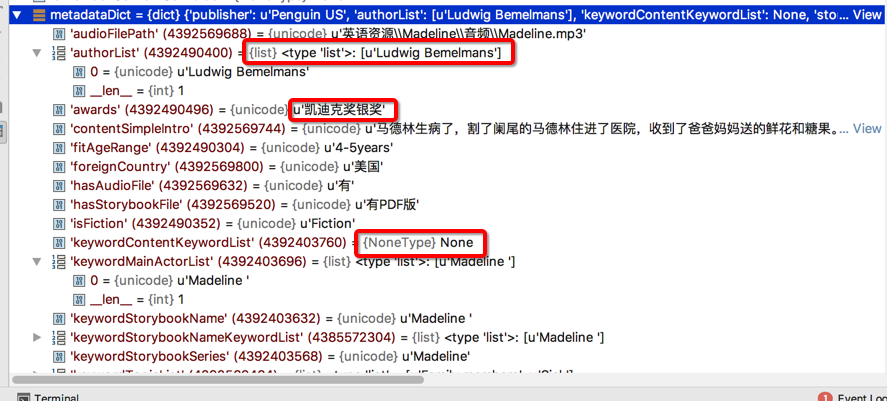
<code>2018/03/30 03:21:30 LINE 230 INFO metadataDict={'publisher': u'Penguin US', 'authorList': [u'Ludwig Bemelmans'], 'keywordContentKeywordList': None, 'storybookSeriesNumber': 1L, 'storybookFilePath': u'\u82f1\u8bed\u8d44\u6e90\\Madeline\\\u7535\u5b50\u4e66\\Madeline.pdf', 'lexileIndex': None, 'keywordStorybookNameKeywordList': [u'Madeline '], 'fitAgeRange': u'4-5years', 'keywordStorybookName': u'Madeline ', 'hasAudioFile': u'\u6709', 'hasStorybookFile': u'\u6709PDF\u7248', 'audioFilePath': u'\u82f1\u8bed\u8d44\u6e90\\Madeline\\\u97f3\u9891\\Madeline.mp3', 'keywordTopicList': [u'Family members', u'Sick'], 'isFiction': u'Fiction', 'foreignCountry': u'\u7f8e\u56fd', 'awards': u'\u51ef\u8fea\u514b\u5956\u94f6\u5956', 'contentSimpleIntro': u'\u9a6c\u5fb7\u6797\u751f\u75c5\u4e86\uff0c\u5272\u4e86\u9611\u5c3e\u7684\u9a6c\u5fb7\u6797\u4f4f\u8fdb\u4e86\u533b\u9662\uff0c\u6536\u5230\u4e86\u7238\u7238\u5988\u5988\u9001\u7684\u9c9c\u82b1\u548c\u7cd6\u679c\u3002\u5176\u4ed6\u59d1\u5a18\u4eec\u770b\u4e86\u9a6c\u5fb7\u6797\u7684\u793c\u7269\u7adf\u7136\u4e5f\u60f3\u5f97\u9611\u5c3e\u708e\u3002\u662f\u4e0d\u662f\u5f88\u6709\u8da3\u3002', 'type': 'storybook', 'keywordMainActorList': [u'Madeline '], 'keywordStorybookSeries': u'Madeline'}
</code>去保存进去,看看保持后的效果如何:
PyCharm的Mongo插件看到的效果:
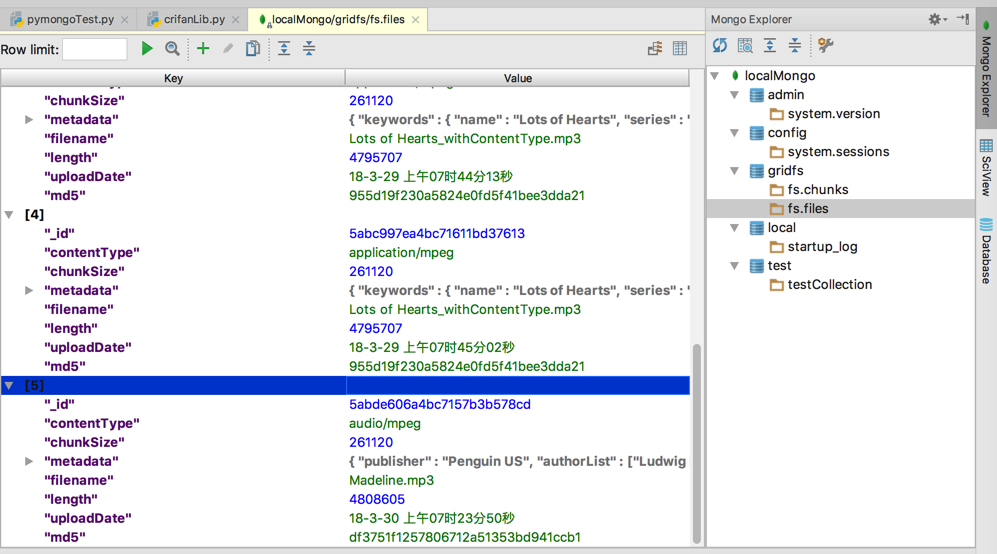
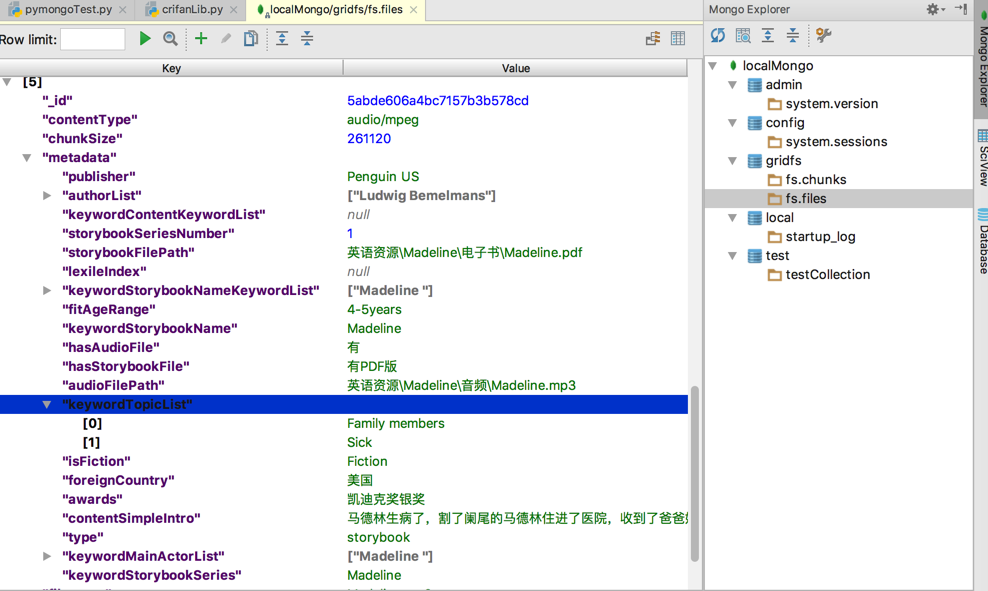
<code>> db.fs.files.find().pretty()
{
"_id" : ObjectId("5abde606a4bc7157b3b578cd"),
"contentType" : "audio/mpeg",
"chunkSize" : 261120,
"metadata" : {
"publisher" : "Penguin US",
"authorList" : [
"Ludwig Bemelmans"
],
"keywordContentKeywordList" : null,
"storybookSeriesNumber" : NumberLong(1),
"storybookFilePath" : "英语资源\\Madeline\\电子书\\Madeline.pdf",
"lexileIndex" : null,
"keywordStorybookNameKeywordList" : [
"Madeline "
],
"fitAgeRange" : "4-5years",
"keywordStorybookName" : "Madeline ",
"hasAudioFile" : "有",
"hasStorybookFile" : "有PDF版",
"audioFilePath" : "英语资源\\Madeline\\音频\\Madeline.mp3",
"keywordTopicList" : [
"Family members",
"Sick"
],
"isFiction" : "Fiction",
"foreignCountry" : "美国",
"awards" : "凯迪克奖银奖",
"contentSimpleIntro" : "马德林生病了,割了阑尾的马德林住进了医院,收到了爸爸妈妈送的鲜花和糖果。其他姑娘们看了马德林的礼物竟然也想得阑尾炎。是不是很有趣。",
"type" : "storybook",
"keywordMainActorList" : [
"Madeline "
],
"keywordStorybookSeries" : "Madeline"
},
"filename" : "Madeline.mp3",
"length" : 4808605,
"uploadDate" : ISODate("2018-03-30T07:23:50.210Z"),
"md5" : "df3751f1257806712a51353bd941ccb1"
}
</code>->
Python中的None,保存后是JSON中的null
另外还有:
excel中的数字1,保存后是:
“storybookSeriesNumber” : NumberLong(1)
总之:还是不错的。
然后代码:
<code># -*- coding: utf-8 -*-
import pymongo
from pymongo import MongoClient
import gridfs
# from pymongo.objectid import ObjectId
# from pymongo import objectid
from bson.objectid import ObjectId
from gridfs import GridFS
# import pprint
import os
import logging
import sys
sys.path.append("libs/crifan")
import crifanLib
import re
import mime
from openpyxl import Workbook, load_workbook
################################################################################
# Global Config/Setting
################################################################################
StorybookSheetTitle = u"绘本"
EnglishStorybookRootPath = u"/Users/crifan/dev/dev_root/xxx"
ExcelFilename = u"英语绘本资源2018.3.28_forDebug.xlsx"
ExcelFullFilename = os.path.join(EnglishStorybookRootPath, ExcelFilename)
AudioFilePathPrefix = EnglishStorybookRootPath
# the real content start row number
realContentRowStartNum = 3
# each column number
StorybookSerieNumColNum = 1
KeywordStorybookSerieColNum = 2
KeywordStorybookNameColNum = 3
KeywordStorybookNameKeywordColNum = 4
KeywordMainActorColNum = 5
KeywordTopicColNum = 6
KeywordContentKeywordColNum = 7
FitAgeRangeColNum = 8
IsFictionColNum = 9
HasStorybookFileColNum = 10
StorybookFilePathColNum = 11
HasAudioFileColNum = 12
AudioFilePathColNum = 13
AuthorColNum = 14
ContentSimpleIntroColNum = 15
PublisherColNum = 16
ForeignCountryColNum = 17
AwardsColNum = 18
LexileIndexColNum = 19
################################################################################
# Global Value
################################################################################
gSummaryDict = {
"totalCostTime": 0,
"savedFile": {
"totalCount": 0,
"idNameList": []
}
}
################################################################################
# Local Function
################################################################################
def initLogging():
"""
init logging
:return: log file name
"""
global gCfg
# init logging
filenameNoSufx = crifanLib.getInputFileBasenameNoSuffix()
logFilename = filenameNoSufx + ".log"
crifanLib.loggingInit(logFilename)
return logFilename
def strToList(inputStr, seperatorChar=","):
"""
convert string to list by using seperator char
example:
u'Family members,Sick'
->
[u'Family members', u'Sick']
:param seperatorChar: the seperator char
:return: converted list
"""
convertedList = None
if inputStr:
convertedList = inputStr.split(seperatorChar) #<type 'list'>: [u'Family members', u'Sick']
return convertedList
def testGridfsDeleteFile(fsCollection):
# test file delete
# fileIdToDelete = "5abc96dfa4bc715f473f0297"
# fileIdToDelete = "5abc9525a4bc715e187c6d6d"
# fileIdToDelete = "ObjectId('5abc96dfa4bc715f473f0297')"
# fileIdToDelete = 'ObjectId("5abc8d77a4bc71563222d455")'
# fileIdToDelete = '5abc8d77a4bc71563222d455'
# logging.info("fileIdToDelete=%s", fileIdToDelete)
# foundFile = fsCollection.find_one({"_id": fileIdToDelete})
# foundFile = fsCollection.find_one()
# logging.info("foundFile=%s", foundFile)
# fileIdToDelete = foundFile._id
# logging.info("fileIdToDelete=%s", fileIdToDelete)
curNum = 0
for curIdx, eachFile in enumerate(fsCollection.find()):
curNum = curIdx + 1
# fileIdToDelete = eachFile._id
# fileObjectIdToDelete = ObjectId(fileIdToDelete)
fileObjectIdToDelete = eachFile._id
logging.info("fileObjectIdToDelete=%s", fileObjectIdToDelete)
# if fsCollection.exists(fileObjectIdToDelete):
fsCollection.delete(fileObjectIdToDelete)
logging.info("delete [%d] ok for file object id=%s", curNum, fileObjectIdToDelete)
# else:
# logging.warning("Can not find file to delete for id=%s", fileIdToDelete)
logging.info("Total deleted [%d] files", curNum)
################################################################################
# Main Part
################################################################################
initLogging()
# parse excel file
wb = load_workbook(ExcelFullFilename)
logging.info("wb=%s", wb)
# sheetNameList = wb.get_sheet_names()
# logging.info("sheetNameList=%s", sheetNameList)
ws = wb[StorybookSheetTitle]
logging.info("ws=%s", ws)
# init mongodb
mongoClient = MongoClient()
logging.info("mongoClient=%s", mongoClient)
# gridfsDb = mongoClient.gridfs
gridfsDb = mongoClient.gridfs
logging.info("gridfsDb=%s", gridfsDb)
# collectionNames = gridfsDb.collection_names(include_system_collections=False)
# logging.info("collectionNames=%s", collectionNames)
# fsCollection = gridfsDb.fs
# fsCollection = gridfsDb["fs"]
fsCollection = GridFS(gridfsDb)
logging.info("fsCollection=%s", fsCollection)
testGridfsDeleteFile(fsCollection)
crifanLib.calcTimeStart("saveAllAudioFile")
# process each row in excel
for curRowNum in range(realContentRowStartNum, ws.max_row + 1):
logging.info("-"*30 + " row[%d] " + "-"*30, curRowNum)
hasAudioFileColNumCellValue = ws.cell(row=curRowNum, column=HasAudioFileColNum).value
logging.info("col[%d] hasAudioFileColNumCellValue=%s", HasAudioFileColNum, hasAudioFileColNumCellValue)
audioFilePathColNumCellValue = ws.cell(row=curRowNum, column=AudioFilePathColNum).value
logging.info("col[%d] audioFilePathColNumCellValue=%s", AudioFilePathColNum, audioFilePathColNumCellValue)
if not ((hasAudioFileColNumCellValue == u"有") and audioFilePathColNumCellValue and (audioFilePathColNumCellValue != u"")):
logging.warning("not found valid audio file for row=%d", curRowNum)
continue
logging.info("will save audio file %s", audioFilePathColNumCellValue)
# extract all column value
storybookSerieNumCellValue = ws.cell(row=curRowNum, column=StorybookSerieNumColNum).value
logging.info("col[%d] storybookSerieNumCellValue=%s", StorybookSerieNumColNum, storybookSerieNumCellValue)
keywordStorybookSerieCellValue = ws.cell(row=curRowNum, column=KeywordStorybookSerieColNum).value
logging.info("col[%d] keywordStorybookSerieCellValue=%s", KeywordStorybookSerieColNum, keywordStorybookSerieCellValue)
keywordStorybookNameColNumCellValue = ws.cell(row=curRowNum, column=KeywordStorybookNameColNum).value
logging.info("col[%d] keywordStorybookNameColNumCellValue=%s", KeywordStorybookNameColNum, keywordStorybookNameColNumCellValue)
keywordStorybookNameKeywordCellValue = ws.cell(row=curRowNum, column=KeywordStorybookNameKeywordColNum).value
logging.info("col[%d] keywordStorybookNameKeywordCellValue=%s", KeywordStorybookNameKeywordColNum, keywordStorybookNameKeywordCellValue)
keywordMainActorColNumCellValue = ws.cell(row=curRowNum, column=KeywordMainActorColNum).value
logging.info("col[%d] keywordMainActorColNumCellValue=%s", KeywordMainActorColNum, keywordMainActorColNumCellValue)
keywordTopicColNumCellValue = ws.cell(row=curRowNum, column=KeywordTopicColNum).value
logging.info("col[%d] keywordTopicColNumCellValue=%s", KeywordTopicColNum, keywordTopicColNumCellValue)
keywordContentKeywordColNumCellValue = ws.cell(row=curRowNum, column=KeywordContentKeywordColNum).value
logging.info("col[%d] keywordContentKeywordColNumCellValue=%s", KeywordContentKeywordColNum, keywordContentKeywordColNumCellValue)
fitAgeRangeColNumCellValue = ws.cell(row=curRowNum, column=FitAgeRangeColNum).value
logging.info("col[%d] fitAgeRangeColNumCellValue=%s", FitAgeRangeColNum, fitAgeRangeColNumCellValue)
isFictionColNumCellValue = ws.cell(row=curRowNum, column=IsFictionColNum).value
logging.info("col[%d] isFictionColNumCellValue=%s", IsFictionColNum, isFictionColNumCellValue)
hasStorybookFileColNumCellValue = ws.cell(row=curRowNum, column=HasStorybookFileColNum).value
logging.info("col[%d] hasStorybookFileColNumCellValue=%s", HasStorybookFileColNum, hasStorybookFileColNumCellValue)
storybookFilePathColNumCellValue = ws.cell(row=curRowNum, column=StorybookFilePathColNum).value
logging.info("col[%d] storybookFilePathColNumCellValue=%s", StorybookFilePathColNum, storybookFilePathColNumCellValue)
authorColNumCellValue = ws.cell(row=curRowNum, column=AuthorColNum).value
logging.info("col[%d] authorColNumCellValue=%s", AuthorColNum, authorColNumCellValue)
contentSimpleIntroColNumCellValue = ws.cell(row=curRowNum, column=ContentSimpleIntroColNum).value
logging.info("col[%d] contentSimpleIntroColNumCellValue=%s", ContentSimpleIntroColNum, contentSimpleIntroColNumCellValue)
publisherColNumCellValue = ws.cell(row=curRowNum, column=PublisherColNum).value
logging.info("col[%d] publisherColNumCellValue=%s", PublisherColNum, publisherColNumCellValue)
foreignCountryColNumCellValue = ws.cell(row=curRowNum, column=ForeignCountryColNum).value
logging.info("col[%d] foreignCountryColNumCellValue=%s", ForeignCountryColNum, foreignCountryColNumCellValue)
awardsColNumCellValue = ws.cell(row=curRowNum, column=AwardsColNum).value
logging.info("col[%d] awardsColNumCellValue=%s", AwardsColNum, awardsColNumCellValue)
lexileIndexColNumCellValue = ws.cell(row=curRowNum, column=LexileIndexColNum).value
logging.info("col[%d] lexileIndexColNumCellValue=%s", LexileIndexColNum, lexileIndexColNumCellValue)
# test read existed file info
# someFile = fsCollection.files.find_one()
# someFile = fsCollection.find_one()
# logging.info("someFile=%s", someFile)
# # ottoTheCatFile = fsCollection.files.find_one({"filename": "Otto the Cat-withMIME.MP3"})
# ottoTheCatFile = fsCollection.find_one({"filename": "Otto the Cat-withMIME.MP3"})
# logging.info("ottoTheCatFile=%s", ottoTheCatFile)
# put/save local file to mongodb
# curAudioFilename = "英语资源\All Aboard Reading\音频\Lots of Hearts.mp3"
# curAudioFilenameFiltered = re.sub(r"\\", "/", curAudioFilename) #'英语资源/All Aboard Reading/音频/Lots of Hearts.mp3'
curAudioFilenameFiltered = re.sub(r"\\", "/", audioFilePathColNumCellValue) # u'英语资源/Madeline/音频/Madeline.mp3'
# curAudioFullFilename = "/Users/crifan/dev/dev_root/xxx/" + curAudioFilename
curAudioFullFilename = os.path.join(AudioFilePathPrefix, curAudioFilenameFiltered) #u'/Users/crifan/dev/dev_root/xxx/音频/Madeline.mp3'
if not os.path.isfile(curAudioFullFilename):
logging.error("Can not find file: %s", curAudioFullFilename)
continue
curFilename = crifanLib.getBasename(curAudioFullFilename) #u'Madeline.mp3'
logging.info("curFilename=%s", curFilename)
# extarct MIME
# fileMimeType = mime.MIMETypes.load_from_file(curFilename)
# fileMimeType = mime.MimeType.fromName(curFilename)
fileMimeType = mime.Types.of(curFilename)[0].content_type
logging.info("fileMimeType=%s", fileMimeType) #'audio/mpeg'
metadataDict = {
"type": "storybook",
"storybookSeriesNumber": storybookSerieNumCellValue,
"keywordStorybookSeries": keywordStorybookSerieCellValue,
"keywordStorybookName": keywordStorybookNameColNumCellValue,
"keywordStorybookNameKeywordList": strToList(keywordStorybookNameKeywordCellValue),
"keywordMainActorList": strToList(keywordMainActorColNumCellValue),
"keywordTopicList": strToList(keywordTopicColNumCellValue),
"keywordContentKeywordList": strToList(keywordContentKeywordColNumCellValue),
"fitAgeRange": fitAgeRangeColNumCellValue,
"isFiction": isFictionColNumCellValue,
"hasStorybookFile": hasStorybookFileColNumCellValue,
"storybookFilePath": storybookFilePathColNumCellValue,
"hasAudioFile": hasAudioFileColNumCellValue,
"audioFilePath": audioFilePathColNumCellValue,
"authorList": strToList(authorColNumCellValue),
"contentSimpleIntro": contentSimpleIntroColNumCellValue,
"publisher": publisherColNumCellValue,
"foreignCountry": foreignCountryColNumCellValue,
"awards": awardsColNumCellValue,
"lexileIndex": lexileIndexColNumCellValue
}
logging.info("metadataDict=%s", metadataDict)
with open(curAudioFullFilename) as audioFp:
audioFileObjectId = fsCollection.put(
audioFp,
filename=curFilename,
content_type=fileMimeType,
metadata=metadataDict)
logging.info("audioFileObjectId=%s", audioFileObjectId)
# readOutAudioFile = fsCollection.get(audioFileObjectId)
# logging.info("readOutAudioFile=%s", readOutAudioFile)
# audioFileMedata = readOutAudioFile.metadata
# logging.info("audioFileMedata=%s", audioFileMedata)
audioFileIdStr = str(audioFileObjectId)
gSummaryDict["savedFile"]["totalCount"] += 1
idNameDict = {
"fileId": audioFileIdStr,
"fileName": curFilename
}
gSummaryDict["savedFile"]["idNameList"].append(idNameDict)
gSummaryDict["totalCostTime"] = crifanLib.calcTimeEnd("saveAllAudioFile")
logging.info("="*30 + " Summary Info " + "="*30)
logging.info("gSummaryDict=%s", gSummaryDict)
logging.info("%s", crifanLib.jsonToPrettyStr(gSummaryDict))
</code>输出log日志:
<code>2018/03/30 04:37:07 LINE 146 INFO wb=<openpyxl.workbook.workbook.Workbook object at 0x108ee0cd0> 2018/03/30 04:37:07 LINE 150 INFO ws=<Worksheet "\u7ed8\u672c"> 2018/03/30 04:37:07 LINE 155 INFO mongoClient=MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True) 2018/03/30 04:37:07 LINE 159 INFO gridfsDb=Database(MongoClient(host=['localhost:27017'], document_class=dict, tz_aware=False, connect=True), u'gridfs') 2018/03/30 04:37:07 LINE 167 INFO fsCollection=<gridfs.GridFS object at 0x108ef0bd0> 2018/03/30 04:37:07 LINE 128 INFO fileObjectIdToDelete=5abdf644a4bc71664b89fcec </code>
2018/03/30 04:37:11 LINE 175 INFO —————————— row[42] ——————————
2018/03/30 04:37:11 LINE 178 INFO col[12] hasAudioFileColNumCellValue=有
2018/03/30 04:37:11 LINE 180 INFO col[13] audioFilePathColNumCellValue=英语资源\Madeline\音频\Madeline.mp3
2018/03/30 04:37:11 LINE 186 INFO will save audio file 英语资源\Madeline\音频\Madeline.mp3
2018/03/30 04:37:11 LINE 190 INFO col[1] storybookSerieNumCellValue=1
2018/03/30 04:37:11 LINE 192 INFO col[2] keywordStorybookSerieCellValue=Madeline
2018/03/30 04:37:11 LINE 194 INFO col[3] keywordStorybookNameColNumCellValue=Madeline
2018/03/30 04:37:11 LINE 196 INFO col[4] keywordStorybookNameKeywordCellValue=Madeline
2018/03/30 04:37:11 LINE 198 INFO col[5] keywordMainActorColNumCellValue=Madeline
2018/03/30 04:37:11 LINE 200 INFO col[6] keywordTopicColNumCellValue=Family members,Sick
2018/03/30 04:37:11 LINE 202 INFO col[7] keywordContentKeywordColNumCellValue=None
2018/03/30 04:37:11 LINE 204 INFO col[8] fitAgeRangeColNumCellValue=4-5years
2018/03/30 04:37:11 LINE 206 INFO col[9] isFictionColNumCellValue=Fiction
2018/03/30 04:37:11 LINE 208 INFO col[10] hasStorybookFileColNumCellValue=有PDF版
2018/03/30 04:37:11 LINE 210 INFO col[11] storybookFilePathColNumCellValue=英语资源\Madeline\电子书\Madeline.pdf
2018/03/30 04:37:11 LINE 213 INFO col[14] authorColNumCellValue=Ludwig Bemelmans
2018/03/30 04:37:11 LINE 215 INFO col[15] contentSimpleIntroColNumCellValue=马德林生病了,割了阑尾的马德林住进了医院,收到了爸爸妈妈送的鲜花和糖果。其他姑娘们看了马德林的礼物竟然也想得阑尾炎。是不是很有趣。
2018/03/30 04:37:11 LINE 217 INFO col[16] publisherColNumCellValue=Penguin US
2018/03/30 04:37:11 LINE 219 INFO col[17] foreignCountryColNumCellValue=美国
2018/03/30 04:37:11 LINE 221 INFO col[18] awardsColNumCellValue=凯迪克奖银奖
2018/03/30 04:37:11 LINE 223 INFO col[19] lexileIndexColNumCellValue=None
2018/03/30 04:37:11 LINE 245 INFO curFilename=Madeline.mp3
2018/03/30 04:37:11 LINE 251 INFO fileMimeType=audio/mpeg
2018/03/30 04:37:11 LINE 276 INFO metadataDict={‘publisher’: u’Penguin US’, ‘authorList’: [u’Ludwig Bemelmans’], ‘keywordContentKeywordList’: None, ‘storybookSeriesNumber’: 1L, ‘storybookFilePath’: u’\u82f1\u8bed\u8d44\u6e90\\Madeline\\\u7535\u5b50\u4e66\\Madeline.pdf’, ‘lexileIndex’: None, ‘keywordStorybookNameKeywordList’: [u’Madeline ‘], ‘fitAgeRange’: u’4-5years’, ‘keywordStorybookName’: u’Madeline ‘, ‘hasAudioFile’: u’\u6709′, ‘hasStorybookFile’: u’\u6709PDF\u7248′, ‘audioFilePath’: u’\u82f1\u8bed\u8d44\u6e90\\Madeline\\\u97f3\u9891\\Madeline.mp3′, ‘keywordTopicList’: [u’Family members’, u’Sick’], ‘isFiction’: u’Fiction’, ‘foreignCountry’: u’\u7f8e\u56fd’, ‘awards’: u’\u51ef\u8fea\u514b\u5956\u94f6\u5956′, ‘contentSimpleIntro’: u’\u9a6c\u5fb7\u6797\u751f\u75c5\u4e86\uff0c\u5272\u4e86\u9611\u5c3e\u7684\u9a6c\u5fb7\u6797\u4f4f\u8fdb\u4e86\u533b\u9662\uff0c\u6536\u5230\u4e86\u7238\u7238\u5988\u5988\u9001\u7684\u9c9c\u82b1\u548c\u7cd6\u679c\u3002\u5176\u4ed6\u59d1\u5a18\u4eec\u770b\u4e86\u9a6c\u5fb7\u6797\u7684\u793c\u7269\u7adf\u7136\u4e5f\u60f3\u5f97\u9611\u5c3e\u708e\u3002\u662f\u4e0d\u662f\u5f88\u6709\u8da3\u3002′, ‘type’: ‘storybook’, ‘keywordMainActorList’: [u’Madeline ‘], ‘keywordStorybookSeries’: u’Madeline’}
2018/03/30 04:37:11 LINE 284 INFO audioFileObjectId=5abdf737a4bc71672b98881e
2018/03/30 04:37:24 LINE 302 INFO ============================== Summary Info ==============================
2018/03/30 04:37:24 LINE 304 INFO {
“totalCostTime”: 13.567419052124023,
“savedFile”: {
“totalCount”: 171,
“idNameList”: [
{
“fileName”: “Madeline.mp3”,
“fileId”: “5abdf737a4bc71672b98881e”
},
{
“fileName”: “Madeline and the Bad Hat.mp3”,
“fileId”: “5abdf737a4bc71672b988832”
},
{
“fileName”: “Pirate Pat.mp3”,
“fileId”: “5abdf737a4bc71672b98884c”
},
保存的文件的结果:
fs.files
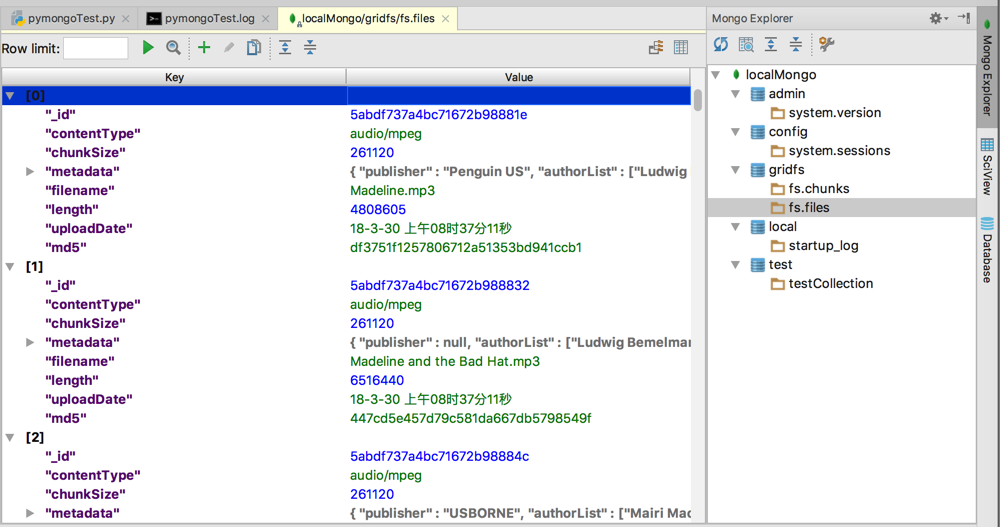
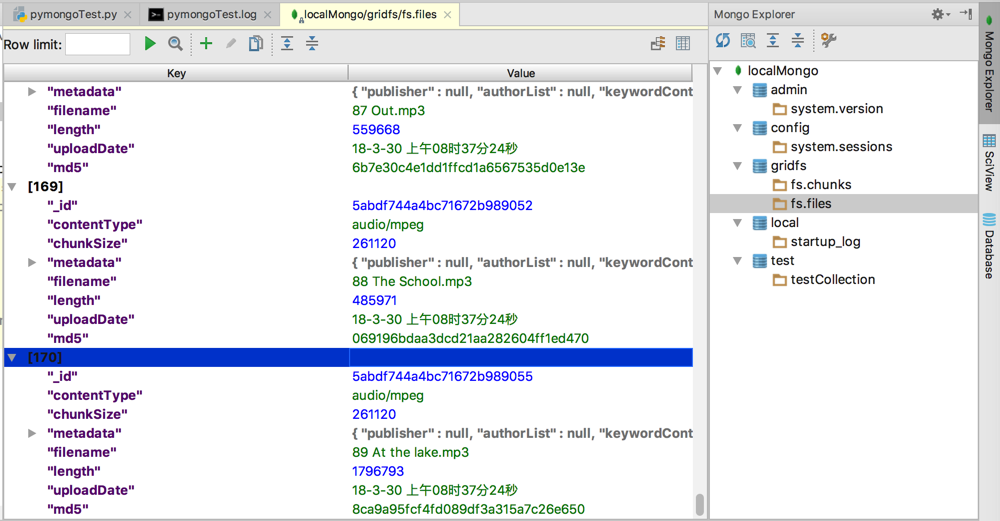
fs.chunks
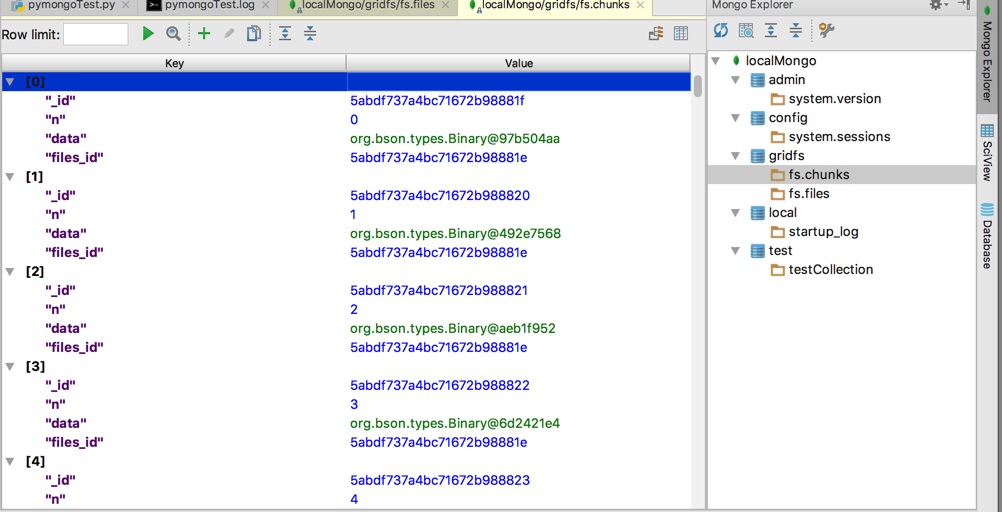
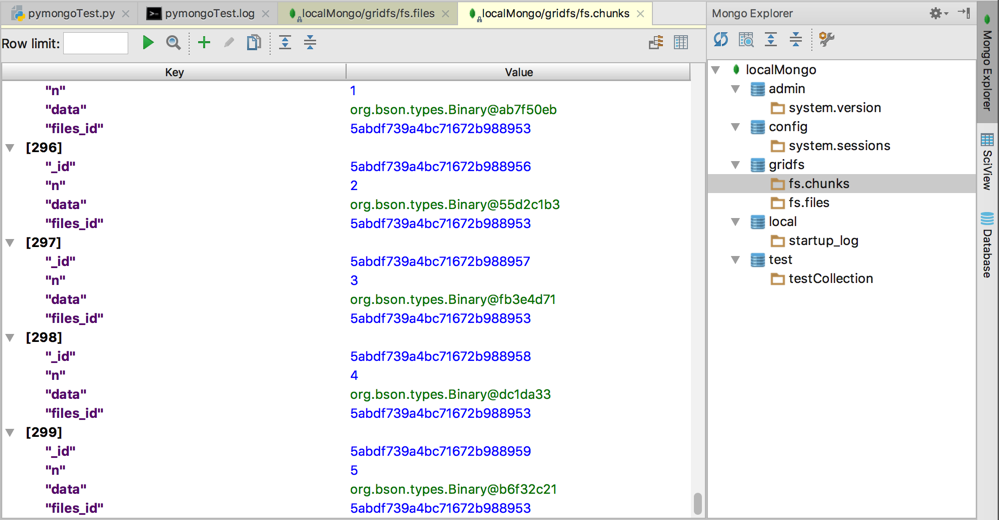
此处:
171个文件
300个chunk文件块
然后此处希望去:
知道了,此处171个音频,存到GridFS中,大小共700多MB。
转载请注明:在路上 » 【已解决】把本地的音频字幕等数据存储到本地MongoDB数据库中