折腾:
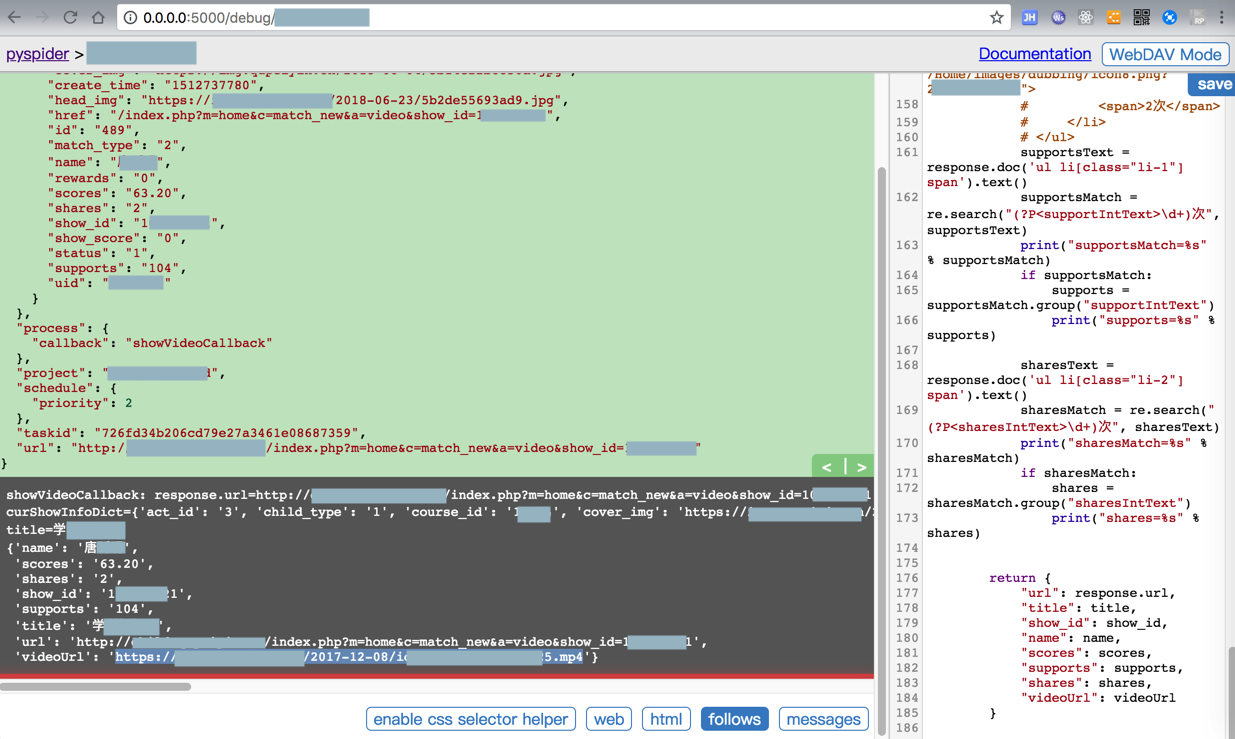
期间,此处已经抓取到mp4视频地址了:
showVideoCallback: response.url=http://xx.xx?m=home&c=match_new&a=video&show_id=1xxx1
curShowInfoDict={‘act_id’: ‘3’, ‘child_type’: ‘1’, ‘course_id’: ‘xx’, ‘cover_img’: ‘https://xx.xx/2018-06-04/5b14e22b8850a.jpg’, ‘create_time’: ‘1512737780’, ‘head_img’: ‘https://xx.xx/2018-06-23/5b2de55693ad9.jpg’, ‘href’: ‘/index.php?m=home&c=match_new&a=video&show_id=1xxx1’, ‘id’: ‘489’, ‘match_type’: ‘2’, ‘name’: ‘唐xx’, ‘rewards’: ‘0’, ‘scores’: ‘63.20’, ‘shares’: ‘2’, ‘show_id’: ‘1xx1’, ‘show_score’: ‘0’, ‘status’: ‘1’, ‘supports’: ‘104’, ‘uid’: ‘5xx’}
title=学学xx
{‘name’: ‘唐xx’,
‘scores’: ‘63.20’,
‘shares’: ‘2’,
‘show_id’: ‘1xxx1’,
‘supports’: ‘104’,
‘title’: ‘学学xx’,
‘url’: ‘http://xx.xx?m=home&c=match_new&a=video&show_id=1xxx1’,
‘videoUrl’: ‘https://xx.xx/2017-12-08/id15xxxuxx.mp4’}
然后就需要去搞清楚:
PySpider中如何下载文件
目前能想到的是:
难道要用requests第三方库去直接下载和保存文件?
pyspider 下载文件
pyspider示例代码七:自动登陆并获得PDF文件下载地址 – microman – 博客园
pyspider – pysipder下载文件超时 – SegmentFault 思否
用的是:urllib2.urlopen去下载文件的
[python]使用pyspider下载meizitu的图片 – 简书
结果 – pyspider中文文档 – pyspider中文网
[python]使用pyspider下载meizitu的图片 – 简书
倒是可以考虑借用PySpider的自带response,把content保存到本地文件中去的。
pyspider—爬取下载图片 – silianpan – 博客园
【总结】
PySpider中用:
import re
import os
import codecs
import json
OutputFullPath = "/Users/crifan/dev/dev_root/xxx/output"
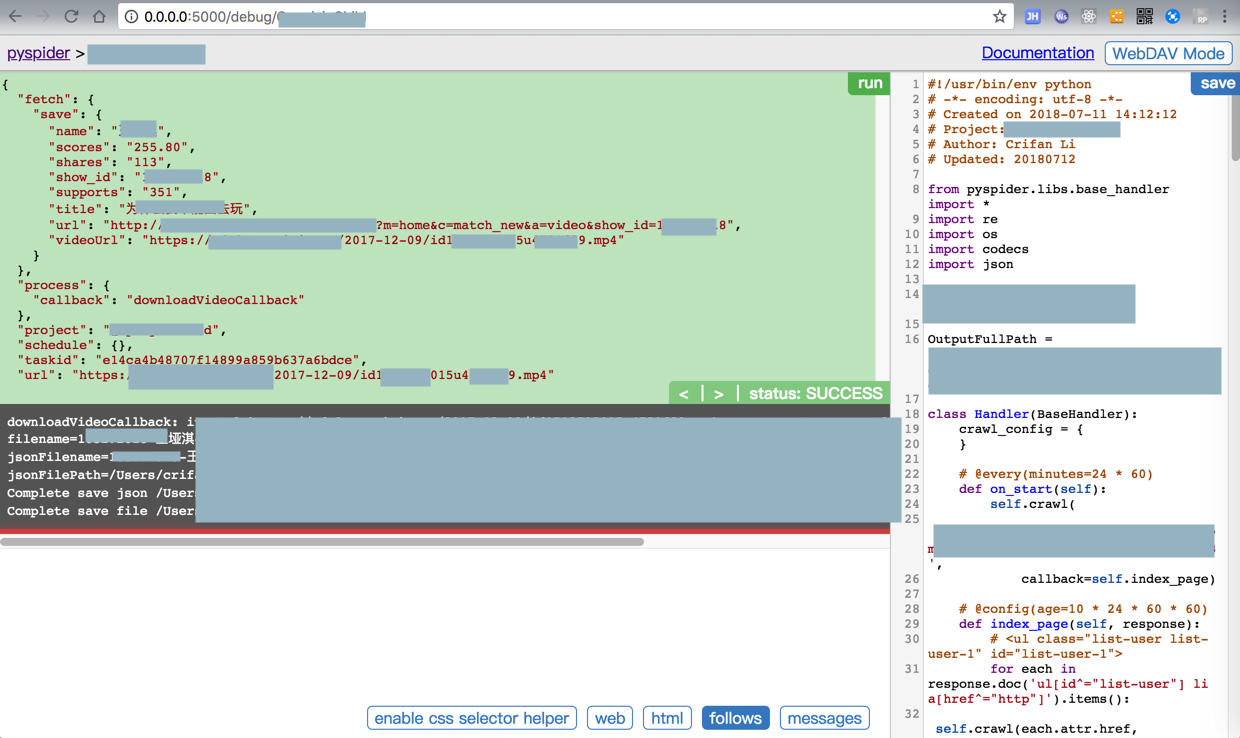
def downloadVideoCallback(self, response):
itemUrl = response.url
print("downloadVideoCallback: itemUrl=%s,response=%s" % (itemUrl, response))
if not os.path.exists(OutputFullPath):
os.makedirs(OutputFullPath)
print("Ok to create folder %s" % OutputFullPath)
itemInfoDict = response.save
filename = "%s-%s-%s" % (
itemInfoDict["show_id"],
itemInfoDict["name"],
itemInfoDict["title"])
print("filename=%s" % filename)
jsonFilename = filename + ".json"
videoSuffix = itemUrl.split(".")[-1]
videoFileName = filename + "." + videoSuffix
print("jsonFilename=%s,videoSuffix=%s,videoFileName=%s" % (jsonFilename, videoSuffix, videoFileName))
# http://xx.xx/index.php?m=home&c=match_new&a=video&show_id=xxx4
# "梁x"
# "57.20"
# "2"
# "1xx34"
# "94"
# "跟xx心"
# "http://xx.x.x/index.php?m=home&c=match_new&a=video&show_id=xx4"
# "https://xx.x.x./2017-12-08/15126857208283977349.mp4"
jsonFilePath = os.path.join(OutputFullPath, jsonFilename)
print("jsonFilePath=%s" % jsonFilePath)
self.saveJsonToFile(jsonFilePath, itemInfoDict)
videoBinData = response.content
videoFilePath = os.path.join(OutputFullPath, videoFileName)
self.saveDataToFile(videoFilePath, videoBinData)
def saveDataToFile(self, fullFilename, binaryData):
with open(fullFilename, ‘wb’) as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
def saveJsonToFile(self, fullFilename, jsonValue):
with codecs.open(fullFilename, ‘w’, encoding="utf-8") as jsonFp:
json.dump(jsonValue, jsonFp, indent=2, ensure_ascii=False)
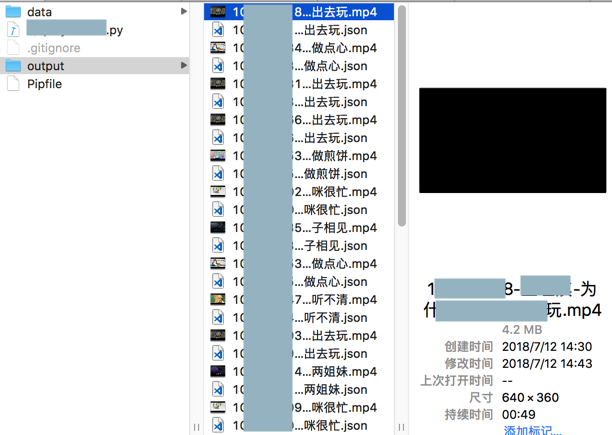
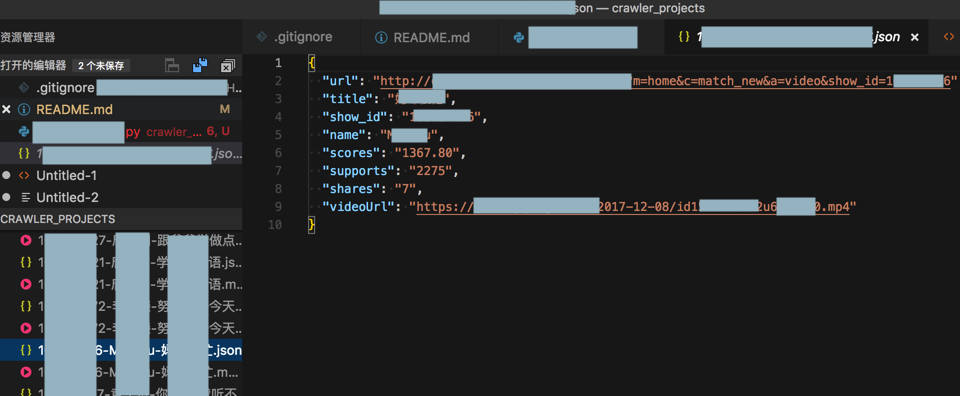
print("Complete save json %s" % fullFilename)实现了保存文件到对应目录:
【后记20190411】
后来整理出下载二进制文件的函数:
def saveDataToFile(fullFilename, binaryData):
"""save binary data info file"""
with open(fullFilename, 'wb') as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
class Handler(BaseHandler):
def downloadFileCallback(self, response):
fileInfo = response.save
print("fileInfo=%s" % fileInfo)
binData = response.content
fileFullPath = os.path.join(fileInfo["saveFolder"], fileInfo["filename"])
print("fileFullPath=%s" % fileFullPath)
saveDataToFile(fileFullPath, binData)
def downloadFile(self, fileInfo):
urlToDownload = fileInfo["fileUrl"]
print("urlToDownload=%s" % urlToDownload)
self.crawl(urlToDownload,
callback=self.downloadFileCallback,
save=fileInfo)调用举例:
# download audio file
# "path": "Audio/1808/20180911222516379.mp3",
audioFileUrlTail = singleAudioDict["path"]
print("audioFileUrlTail=%s" % audioFileUrlTail)
if audioFileUrlTail:
audioFileInfo = {
"fileUrl": gResourcesRoot + "/" + audioFileUrlTail,
"filename": ("Aduios_%s_" % audioId) + audioFileUrlTail.replace("/", "_"),
"saveFolder": curSingleAudioFolder,
}
self.downloadFile(audioFileInfo)转载请注明:在路上 » 【已解决】PySpider中如何下载mp4视频文件到本地