在尝试用PySpider去下载:
http://xxx/Prelim
中的mov视频,比如:
{
"fetch": {
"cookies": {},
"save": {
"AgeGroup": 1,
"Awards": null,
"CreateTime": "2018/04/19 11:41:25",
"Id": 53105,
"Mentor": "Landy",
"Name": "黄彦钧",
"Title": "Mr Big Goes to the Park",
"url": "http://xxx/video/56689",
"videoUrl": "http://xxx/ea99c809vodgzp1252879503/44d467167447398155565246907/f0.mov"
}
},
"process": {
"callback": "saveVideoAndJsonCallback"
},
"project": "xxx",
"schedule": {},
"taskid": "360da33cf77d771dc1974bb0bfbe4cb1",
"url": "http://xxxx/ea99c809vodgzp1252879503/44d467167447398155565246907/f0.mov"
}
时出错:
[E 180713 13:47:57 base_handler:203] HTTP 403: Forbidden
Traceback (most recent call last):
File "/Users/crifan/.local/share/virtualenvs/crawler_qupeiyin_child-SW6GVzwk/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task
result = self._run_task(task, response)
File "/Users/crifan/.local/share/virtualenvs/crawler_qupeiyin_child-SW6GVzwk/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task
response.raise_for_status()
File "/Users/crifan/.local/share/virtualenvs/crawler_qupeiyin_child-SW6GVzwk/lib/python3.6/site-packages/pyspider/libs/response.py", line 184, in raise_for_status
raise http_error
requests.exceptions.HTTPError: HTTP 403: Forbidden
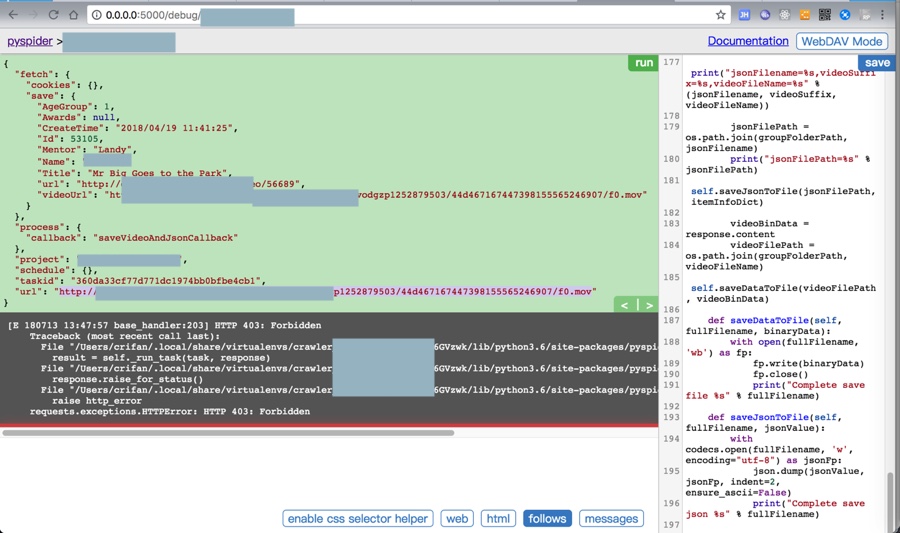
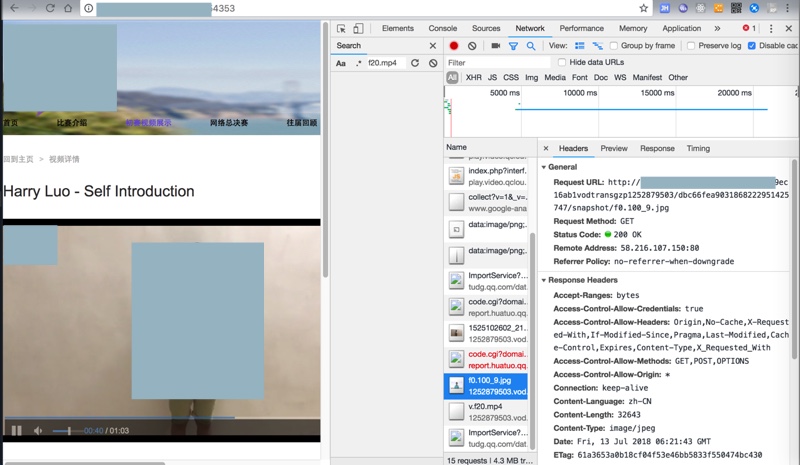
而本身视频是可以在网页中正常播放的:
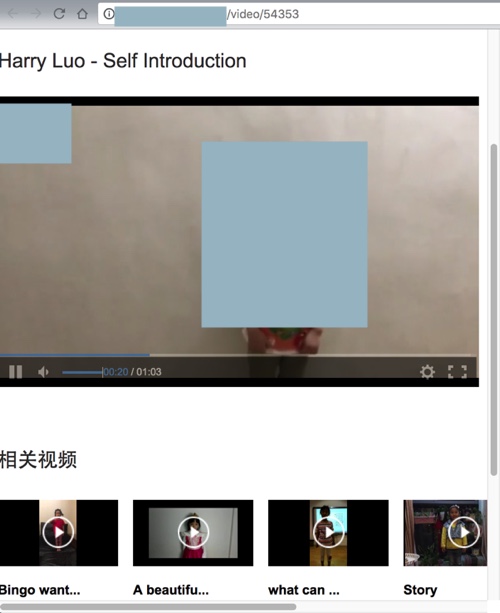
但是的确也发现了,在html中和XHR中,找不到视频的url:
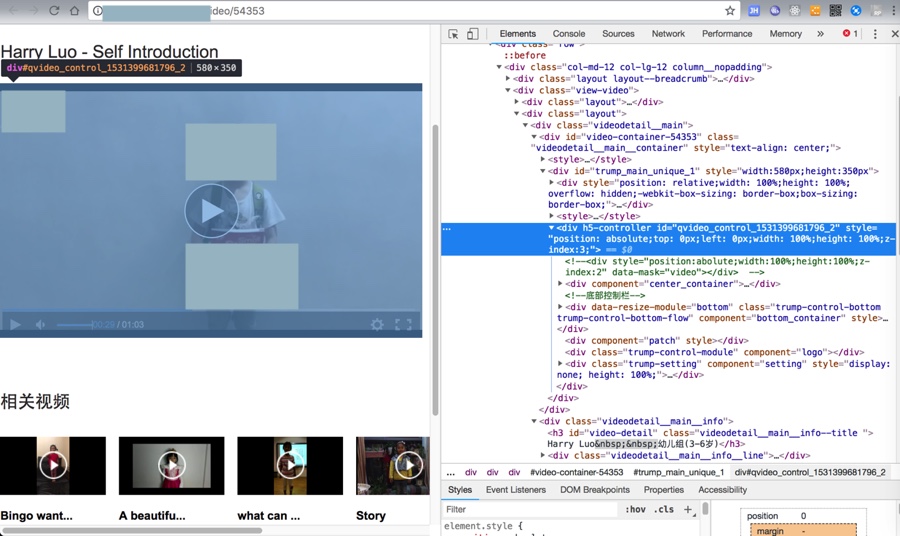
不过调试发现,点击播放后,实际上还有个mp4的视频地址:
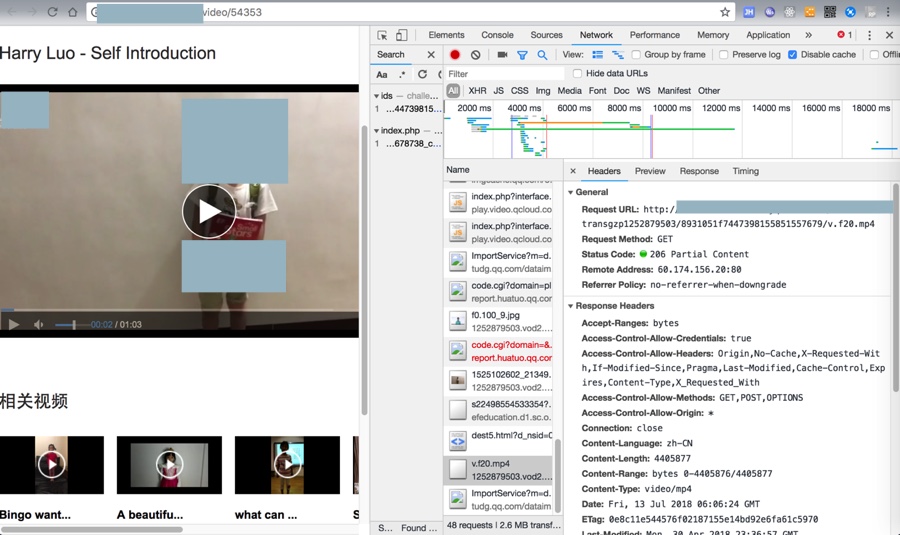
1. Request URL:
http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4
2. Request Method:
GET
3. Status Code:
206 Partial Content
4. Remote Address:
xxx:80
5. Referrer Policy:
no-referrer-when-downgrade
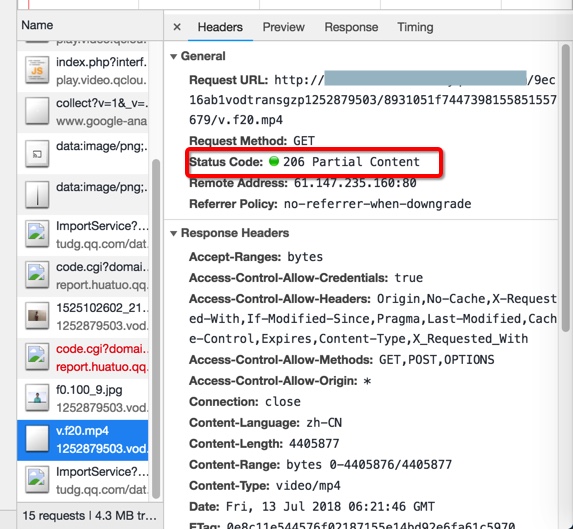
过了会继续加载后续的mp4数据:
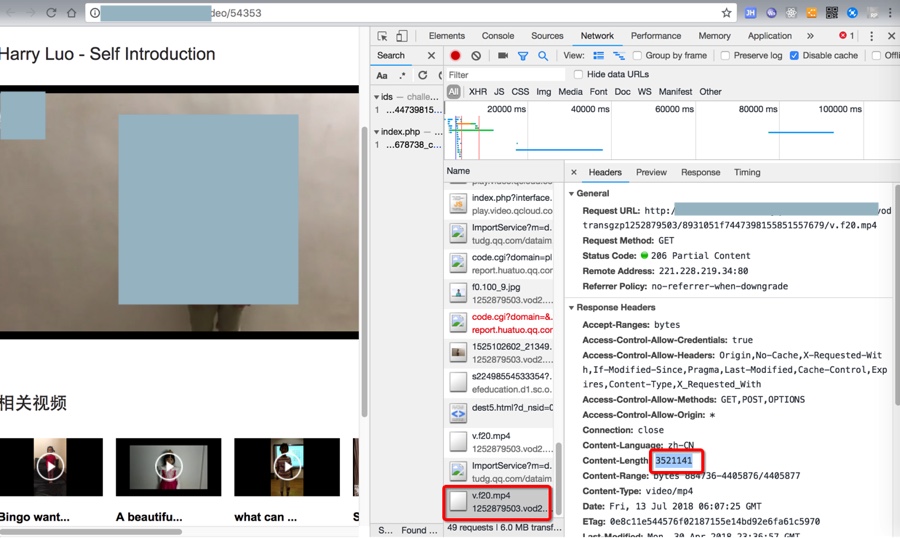
每次都是加载部分partial数据
1. Request URL:
http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4
2. Request Method:
GET
3. Status Code:
206 Partial Content
4. Remote Address:
xxx:80
5. Referrer Policy:
no-referrer-when-downgrade
1. Accept-Ranges:
bytes
2. Access-Control-Allow-Credentials:
true
3. Access-Control-Allow-Headers:
Origin,No-Cache,X-Requested-With,If-Modified-Since,Pragma,Last-Modified,Cache-Control,Expires,Content-Type,X_Requested_With
4. Access-Control-Allow-Methods:
GET,POST,OPTIONS
5. Access-Control-Allow-Origin:
*
6. Connection:
close
7. Content-Language:
zh-CN
8. Content-Length:
3521141
9. Content-Range:
bytes 884736-4405876/4405877
10. Content-Type:
video/mp4
11. Date:
Fri, 13 Jul 2018 06:07:25 GMT
12. ETag:
0e8c11e544576f02187155e14bd92e6fa61c5970
13. Last-Modified:
Mon, 30 Apr 2018 23:36:57 GMT
14. Server:
TencentCOS
15. x-cos-object-type:
normal
16. x-cos-storage-class:
STANDARD
17. X-Daa-Tunnel:
hop_count=1
好像问题转化为:
如何抓取 206 partial content的mp4视频数据
pyspider 206 partial content
Handling Partial Content / 206 · Issue #144 · whatwg/fetch
HTTP 206 Partial Content · Issue #603 · channelcat/sanic
http报 206 Partial Content – CSDN博客
还是先继续去研究,如何获取这个mp4的地址的
搜:
f20.mp4
找到是:
http://xxx/index.php?interface=Vod_Api_GetPlayInfo&1=1&file_id=7447398155851557679&app_id=1252879503&refer=xxx&_=1531461971609&callback=qcvideo_1531461969393_callback1
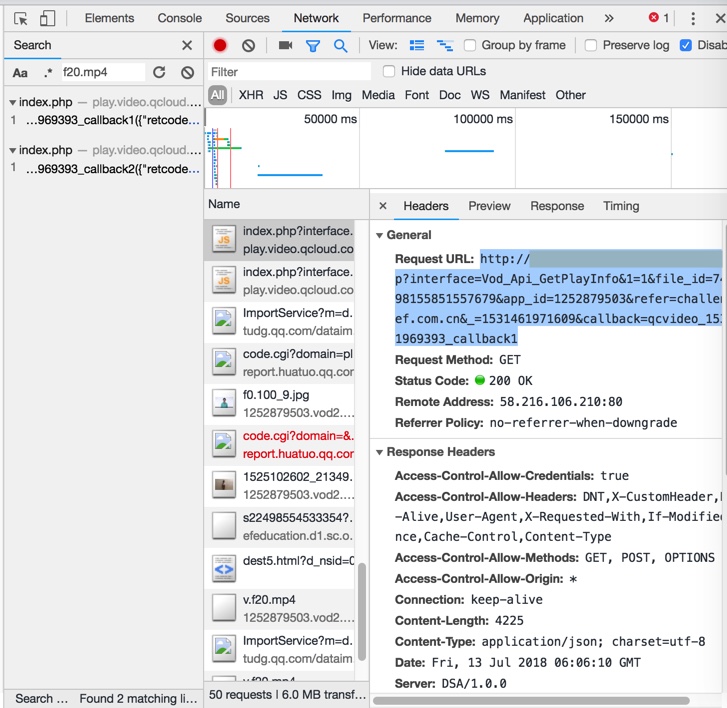
返回的信息中包含mp4的video信息
xxx_1531461969393_callback1({"retcode":0,"errmsg":"succ","data":{"version":{"android":"20150713","flash":"20150713","h5":"20150713","ios":"20150713","swf":{"media":{"mp4":"media_plugin_1124_1.swf"},"skinUrls":{"default_skin":"default_skin_0111.swf"}}},"file_info":{"classification_id":"0","classification_name":"","create_time":"2018-04-30 23:36:39","description":"","duration":"63","err_code":"0","expire_time":"0","id":"7447398155851557679","image_url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_0.jpg","name":"201804301525196827","passwd":null,"player_name":"","size":"9155595","status":"2","tags":[],"type":"mov","update_time":"2018-04-30 23:36:59","vid":"7447398155851557679","wx_status":"0","wx_url":null,"image_video":{"videoUrls":[{"url":"http://xxx/ea99c809vodgzp1252879503/8931051f7447398155851557679/f0.mov","path":"/ea99c809vodgzp1252879503/8931051f7447398155851557679/f0.mov","definition":"0","vbitrate":1096051,"audioBitRate":46876,"vheight":544,"vwidth":960,"format":"","fileSize":9155595,"filename":"","size":"9155595","sha":"","md5":"","fps":29,"rotate":0,"floatDuration":0,"duration":63,"videoCodec":"h264","container":"mov,mp4,m4a,3gp,3g2,mj2","audioCodec":"aac","audioRate":44100},{"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4","path":"/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4","definition":"20","vbitrate":498641,"audioBitRate":48025,"vheight":362,"vwidth":640,"format":"","fileSize":4405877,"filename":"","size":"4405877","sha":"","md5":"14f8bbb59146e01c633bfbbffa3ce62e","fps":24,"rotate":0,"floatDuration":0,"duration":63,"videoCodec":"h264","container":"mov,mp4,m4a,3gp,3g2,mj2","audioCodec":"aac","audioRate":44100}],"imgUrls":[{"id":1,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_0.jpg","vheight":544,"vwidth":960},{"id":2,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_6300.jpg","vheight":544,"vwidth":960},{"id":3,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_12600.jpg","vheight":544,"vwidth":960},{"id":4,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_18900.jpg","vheight":544,"vwidth":960},{"id":5,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_25200.jpg","vheight":544,"vwidth":960},{"id":6,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_31500.jpg","vheight":544,"vwidth":960},{"id":7,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_37800.jpg","vheight":544,"vwidth":960},{"id":8,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_44100.jpg","vheight":544,"vwidth":960},{"id":9,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_50400.jpg","vheight":544,"vwidth":960},{"id":10,"url":"http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_56700.jpg","vheight":544,"vwidth":960}],"duration":63,"code":0,"message":0}},"player_info":{"player_id":"61505","resolution_type":"1","share_button":"0","share_pic":"0","dsc":"","face":"经典","logo_location":"1","logo_pic":"","logo_url":"http://","name":"初始播放器","patch_0_rurl":"","patch_1_rurl":"","patch_2_rurl":"","patch_info":[{"location_type":0,"patch_redirect_url":"","patch_type":"0","patch_url":""},{"location_type":1,"patch_redirect_url":"","patch_type":"0","patch_url":""},{"location_type":2,"patch_redirect_url":"","patch_type":"0","patch_url":""}]}}})
粘贴到Chrome的JSON Handler插件中,看看效果:
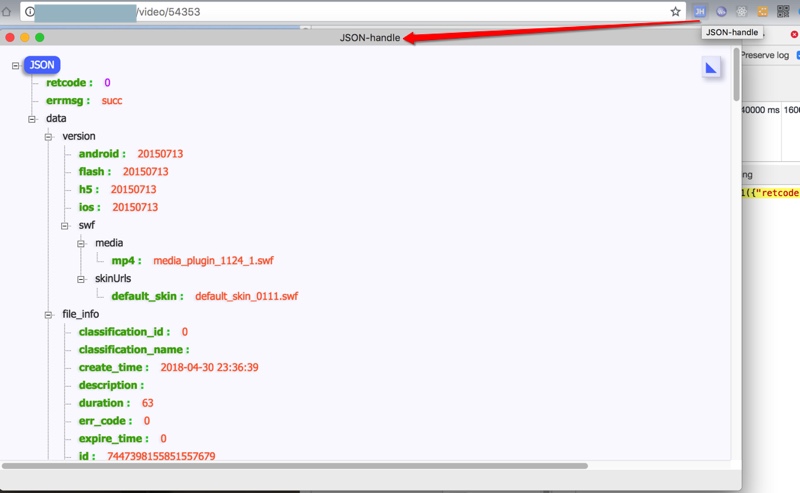
然后看了看,发现duration都是63秒,都是完整的时长,但是两个视频格式不同,一个是mp4,一个是mov
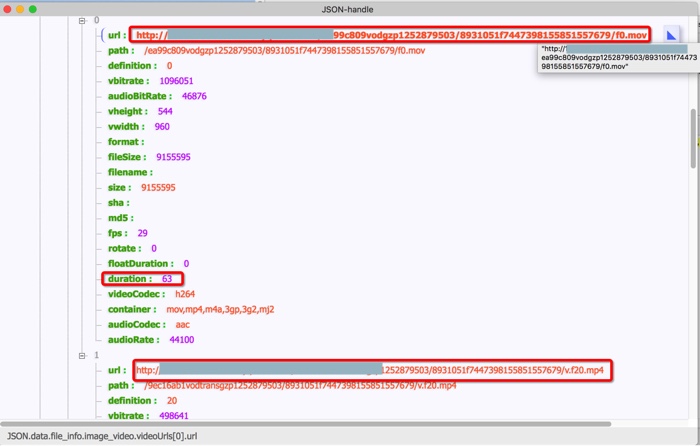
直接打开是会出错的:
http://xxx/ea99c809vodgzp1252879503/8931051f7447398155851557679/f0.mov


重新调试发现:
在点击播放视频之后,就只访问了1次的mp4地址:
但是却依旧是:
1. Status Code:206 Partial Content
先去试试先访问:
http://xxx/index.php
然后把之前cookie带上,再去访问mp4或mov视频地址,看看是否还会出现权限问题。
然后继续调试注意到:
有两个callback:
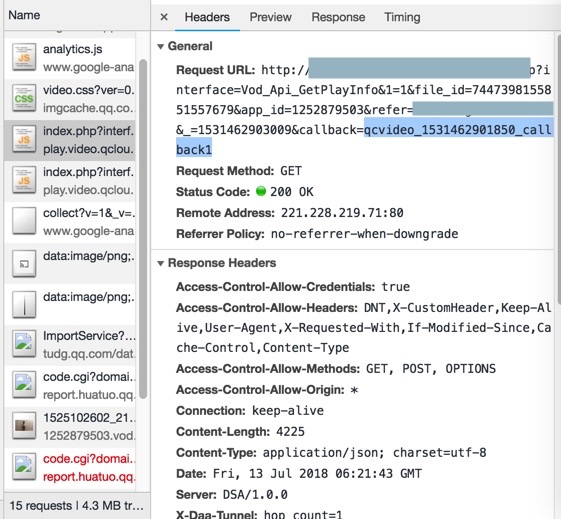
callback1:
http:/xxx/index.php?interface=Vod_Api_GetPlayInfo&1=1&file_id=7447398155851557679&app_id=1252879503&refer=xxx&_=1531462903009&callback=qcvideo_1531462901850_callback1
返回:
xxx_1531462901850_callback1({
"retcode": 0,
"errmsg": "succ",
"data": {
"version": {
"android": "20150713",
"flash": "20150713",
"h5": "20150713",
"ios": "20150713",
"swf": {
"media": {
"mp4": "media_plugin_1124_1.swf"
},
"skinUrls": {
"default_skin": "default_skin_0111.swf"
}
}
},
"file_info": {
"classification_id": "0",
"classification_name": "",
"create_time": "2018-04-30 23:36:39",
"description": "",
"duration": "63",
"err_code": "0",
"expire_time": "0",
"id": "7447398155851557679",
"image_url": "http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_0.jpg",
"name": "201804301525196827",
"passwd": null,
"player_name": "",
"size": "9155595",
"status": "2",
"tags": [],
"type": "mov",
"update_time": "2018-04-30 23:36:59",
"vid": "7447398155851557679",
"wx_status": "0",
"wx_url": null,
"image_video": {
"videoUrls": [{
"url": "http://xxx/ea99c809vodgzp1252879503/8931051f7447398155851557679/f0.mov",
"path": "/ea99c809vodgzp1252879503/8931051f7447398155851557679/f0.mov",
"definition": "0",
"vbitrate": 1096051,
"audioBitRate": 46876,
"vheight": 544,
"vwidth": 960,
"format": "",
"fileSize": 9155595,
"filename": "",
"size": "9155595",
"sha": "",
"md5": "",
"fps": 29,
"rotate": 0,
"floatDuration": 0,
"duration": 63,
"videoCodec": "h264",
"container": "mov,mp4,m4a,3gp,3g2,mj2",
"audioCodec": "aac",
"audioRate": 44100
}, {
"url": "http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4",
"path": "/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/v.f20.mp4",
"definition": "20",
"vbitrate": 498641,
"audioBitRate": 48025,
"vheight": 362,
"vwidth": 640,
"format": "",
"fileSize": 4405877,
"filename": "",
"size": "4405877",
"sha": "",
"md5": "14f8bbb59146e01c633bfbbffa3ce62e",
"fps": 24,
"rotate": 0,
"floatDuration": 0,
"duration": 63,
"videoCodec": "h264",
"container": "mov,mp4,m4a,3gp,3g2,mj2",
"audioCodec": "aac",
"audioRate": 44100
}],
"imgUrls": [{
"id": 1,
"url": "http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_0.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 2,
"url": "http://xxx/9ec16ab1vodtransgzp1252879503/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_6300.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 3,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_12600.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 4,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_18900.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 5,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_25200.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 6,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_31500.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 7,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_37800.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 8,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_44100.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 9,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_50400.jpg",
"vheight": 544,
"vwidth": 960
}, {
"id": 10,
"url": "http://yyy/8931051f7447398155851557679/snapshot/1525102602_2134908634.100_56700.jpg",
"vheight": 544,
"vwidth": 960
}],
"duration": 63,
"code": 0,
"message": 0
}
},
"player_info": {
"player_id": "61505",
"resolution_type": "1",
"share_button": "0",
"share_pic": "0",
"dsc": "",
"face": "经典",
"logo_location": "1",
"logo_pic": "",
"logo_url": "http://",
"name": "初始播放器",
"patch_0_rurl": "",
"patch_1_rurl": "",
"patch_2_rurl": "",
"patch_info": [{
"location_type": 0,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}, {
"location_type": 1,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}, {
"location_type": 2,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}]
}
}
})
而callback2:
http://xxx/index.php?interface=Vod_Api_GetPlayInfo&1=1&file_id=9031868222951425747&app_id=1252879503&refer=xxx&_=1531462903017&callback=qcvideo_1531462901850_callback2
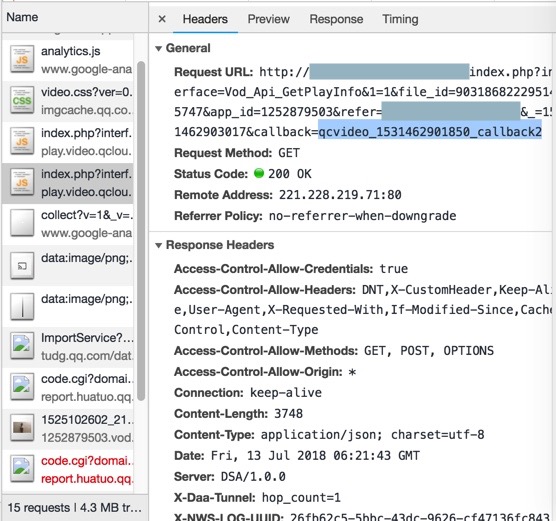
返回:
xxx_1531462901850_callback2({
"retcode": 0,
"errmsg": "succ",
"data": {
"version": {
"android": "20150713",
"flash": "20150713",
"h5": "20150713",
"ios": "20150713",
"swf": {
"media": {
"mp4": "media_plugin_1124_1.swf"
},
"skinUrls": {
"default_skin": "default_skin_0111.swf"
}
}
},
"file_info": {
"classification_id": "371072",
"classification_name": "",
"create_time": "2017-05-25 14:00:02",
"description": "-",
"duration": "194",
"err_code": "0",
"expire_time": "0",
"id": "9031868222951425747",
"image_url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_9.jpg",
"name": "葛彦言",
"passwd": null,
"player_name": "",
"size": "27933967",
"status": "2",
"tags": [],
"type": "mp4",
"update_time": "2017-12-19 10:21:40",
"vid": "9031868222951425747",
"wx_status": "0",
"wx_url": null,
"image_video": {
"videoUrls": [{
"url": "http://1252879503.vod2.myqcloud.com/ea99c809vodgzp1252879503/dbc66fea9031868222951425747/f0.mp4",
"path": "/ea99c809vodgzp1252879503/dbc66fea9031868222951425747/f0.mp4",
"definition": "0",
"vbitrate": 0,
"audioBitRate": 0,
"vheight": 0,
"vwidth": 0,
"format": "",
"fileSize": 27933967,
"filename": "",
"size": "27933967",
"sha": "",
"md5": "",
"fps": 0,
"rotate": 0,
"floatDuration": 0,
"duration": 0,
"videoCodec": "",
"container": "",
"audioCodec": "",
"audioRate": 0
}, {
"url": "http://zzz/dbc66fea9031868222951425747/f0.f20.mp4",
"path": "/9ec16ab1vodtransgzp1252879503/dbc66fea9031868222951425747/f0.f20.mp4",
"definition": "20",
"vbitrate": 501660,
"audioBitRate": 0,
"vheight": 360,
"vwidth": 640,
"format": "",
"fileSize": 27933967,
"filename": "",
"size": "27933967",
"sha": "",
"md5": "4af6f1464da924a11d7f15ebd9fd7002",
"fps": 24,
"rotate": 0,
"floatDuration": 0,
"duration": 0,
"videoCodec": "",
"container": "",
"audioCodec": "",
"audioRate": 0
}],
"imgUrls": [{
"id": 1,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_0.jpg"
}, {
"id": 2,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_1.jpg"
}, {
"id": 3,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_2.jpg"
}, {
"id": 4,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_3.jpg"
}, {
"id": 5,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_4.jpg"
}, {
"id": 6,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_5.jpg"
}, {
"id": 7,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_6.jpg"
}, {
"id": 8,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_7.jpg"
}, {
"id": 9,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_8.jpg"
}, {
"id": 10,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_9.jpg"
}, {
"id": 11,
"url": "http://zzz/dbc66fea9031868222951425747/snapshot/f0.100_10.jpg"
}],
"code": 0,
"message": 0
}
},
"player_info": {
"player_id": "61505",
"resolution_type": "1",
"share_button": "0",
"share_pic": "0",
"dsc": "",
"face": "经典",
"logo_location": "1",
"logo_pic": "",
"logo_url": "http://",
"name": "初始播放器",
"patch_0_rurl": "",
"patch_1_rurl": "",
"patch_2_rurl": "",
"patch_info": [{
"location_type": 0,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}, {
"location_type": 1,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}, {
"location_type": 2,
"patch_redirect_url": "",
"patch_type": "0",
"patch_url": ""
}]
}
}
})
而点击播放视频所加载的视频地址是:
只有callback1中才有
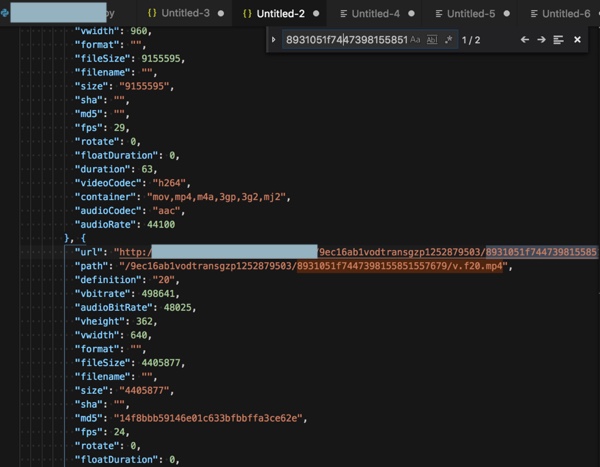
所以去写代码模拟出来:
期间参数用到带毫秒的时间戳,所以去:
然后继续调试:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-07-12 19:59:12
# Project: pprrjj
# Author: Crifan Li
# Updated: 20180713
from pyspider.libs.base_handler import *
import re
import os
import codecs
import json
from datetime import datetime,timedelta
import time
OutputFullPath = "/Users/crifan/dev/dev_root/xxx/output"
AllGroupInfoDict = {
1 : {
"groupName": "幼儿组(3-6岁)",
"totalPageNum": 265,
},
2 : {
"groupName": "小学组(7-12岁)",
"totalPageNum": 365,
},
3 : {
"groupName": "中学组(13-18岁)",
"totalPageNum": 22,
}
}
class Handler(BaseHandler):
crawl_config = {
}
# @every(minutes=24 * 60)
def on_start(self):
entryUrl = "http://xxx/Prelim"
self.crawl(entryUrl, callback=self.indexPageCallback)
# @config(age=10 * 24 * 60 * 60)
def indexPageCallback(self, response):
for eachGroupAge in AllGroupInfoDict.keys():
print("eachGroupAge=%s" % eachGroupAge)
eachGroupDict = AllGroupInfoDict[eachGroupAge]
print("eachGroupDict=%s" % eachGroupDict)
searchUrl = "http://xxx/Video/search"
for curPageIdx in range(eachGroupDict["totalPageNum"]):
print("curPageIdx=%s" % curPageIdx)
queryParaDict = {
"cityCode": "",
"schoolCode": "",
"ageGroup": eachGroupAge,
"status": 2,
"childNameOrPublicSchool": "",
"childNameOrVideoTitle": "",
"pageIndex": curPageIdx,
"pageSize": 30,
"sortFields": "Id",
"orderAsc": ""
}
self.crawl(
searchUrl,
cookies=response.cookies,
params=queryParaDict,
callback=self.searchCallback
)
def searchCallback(self, response):
print("searchCallback: response=%s" % response)
respJson = response.json
print("respJson=%s" % respJson)
if "Data" in respJson:
respDataList = respJson["Data"]
for eachDataDict in respDataList:
ChildID = eachDataDict["ChildID"]
videoDetailUrl = "http://xxx/%s" % ChildID
itemInfoDict = eachDataDict
self.crawl(
videoDetailUrl,
cookies=response.cookies,
callback=self.videoDetailCallback,
save=itemInfoDict
)
else:
print("!!! Fail to get search result json for %s" % response.url)
def videoDetailCallback(self, response):
print("videoDetailCallback: response=%s" % response)
itemInfoDict = response.save
print("itemInfoDict=%s" % itemInfoDict)
# title = response.doc(‘h3[id="video-title"]’).text()
# print("title=%s" % title)
…
# "CreateTime": "2018/04/30 15:37:57",
# "RejectReason": null,
# "ChildrenInfo": {
… # "AgeGroup": 1,
# "CityName": "石家庄",
# "CityCode": "shijiazhuang",
# "IsEFStudent": true,
# "EFSchoolName": "石家庄 裕华中心",
# "EFSchoolCode": "shijiazhuang_yuhua",
# "PublicSchool": "石家庄外国语小学",
# "LatestVideoID": 54355,
# "CreateTime": "2018/04/30 15:21:52",
…
# "Awards": null,
# "Id": 60612
# },
# "Uploader": null,
# "Id": 54355
# },
respDict = {
"url": response.url,
"videoUrl": itemInfoDict["URL"],
"Title": itemInfoDict["Title"],
"AgeGroup": itemInfoDict["ChildrenInfo"]["AgeGroup"],
"Name": itemInfoDict["ChildrenInfo"]["Name"],
"Mentor": itemInfoDict["Mentor"],
"CreateTime": itemInfoDict["CreateTime"],
"Id": itemInfoDict["Id"],
"Awards": itemInfoDict["ChildrenInfo"]["Awards"],
"ClouldId": itemInfoDict["ClouldId"],
}
…
# _: 1531464292921
# callback: qcvideo_1531464290730_callback1
timestamp13DigitStr = str(self.getCurTimestamp(withMilliseconds=True))
timestamp13DigitStr2 = str(self.getCurTimestamp(withMilliseconds=True))
callbackStr = "qcvideo_%s_callback1" % (timestamp13DigitStr2)
queryParaDict = {
"interface": "Vod_Api_GetPlayInfo",
"1": "1",
"file_id": respDict["ClouldId"],
"app_id": "xxx",
"refer": "xxx",
"_": timestamp13DigitStr,
"callback": callbackStr,
}
print("queryParaDict=%s" % queryParaDict)
self.crawl(
getPlayInfoUrl,
params=queryParaDict,
cookies=response.cookies,
callback=self.getPlayInfoCallback,
save=respDict)
def getPlayInfoCallback(self, response):
print("getPlayInfoCallback: response.url=%s,response=%s" % (response.url, response))
respText = response.text
respDict = response.save
print("respText=%s, respDict=%s" % (respText, respDict))
videoMp4Url = ""
# qcvideo_1531470926786_callback1({"retcode":0,"errmsg":"succ","data":{…..}}})
videoJsonMatch = re.search("^qcvideo_\d+_callback\d+\((?P<respJsonStr>.+)\)$", respText)
print("videoJsonMatch=%s" % videoJsonMatch)
if videoJsonMatch:
respJsonStr = videoJsonMatch.group("respJsonStr")
respnJson = json.loads(respJsonStr)
if (respnJson["retcode"] == 0):
respData = respnJson["data"]
videoUrlList = respData["file_info"]["image_video"]["videoUrls"]
print("videoUrlList=%s" % videoUrlList)
for curVideoUrlDict in videoUrlList:
curUrl = curVideoUrlDict["url"]
curVideoSuffix = curUrl.split(".")[-1]
if curVideoSuffix == "mp4":
videoMp4Url = curUrl
respDict["videoMp4Url"] = videoMp4Url
break
if videoMp4Url:
self.crawl(
videoMp4Url,
cookies=response.cookies,
callback=self.saveVideoAndJsonCallback,
save=respDict)
else:
print("!!! Get play info return error: %s" % respnJson["errmsg"])
return respDict
def saveVideoAndJsonCallback(self, response):
itemUrl = response.url
print("saveVideoAndJsonCallback: itemUrl=%s,response=%s" % (itemUrl, response))
itemInfoDict = response.save
AgeGroup = itemInfoDict["AgeGroup"]
print("AgeGroup=%s" % AgeGroup)
groupName = AllGroupInfoDict[AgeGroup]["groupName"]
print("groupName=%s" % groupName)
groupFolderPath = os.path.join(OutputFullPath, groupName)
print("groupFolderPath=%s" % groupFolderPath)
if not os.path.exists(groupFolderPath):
os.makedirs(groupFolderPath)
print("Ok to create folder %s" % groupFolderPath)
filename = "%s-%s" % (
itemInfoDict["Id"],
itemInfoDict["Title"])
print("filename=%s" % filename)
jsonFilename = filename + ".json"
videoSuffix = itemUrl.split(".")[-1]
videoFileName = filename + "." + videoSuffix
print("jsonFilename=%s,videoSuffix=%s,videoFileName=%s" % (jsonFilename, videoSuffix, videoFileName))
jsonFilePath = os.path.join(groupFolderPath, jsonFilename)
print("jsonFilePath=%s" % jsonFilePath)
self.saveJsonToFile(jsonFilePath, itemInfoDict)
videoBinData = response.content
videoFilePath = os.path.join(groupFolderPath, videoFileName)
self.saveDataToFile(videoFilePath, videoBinData)
def saveDataToFile(self, fullFilename, binaryData):
with open(fullFilename, ‘wb’) as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
def saveJsonToFile(self, fullFilename, jsonValue):
with codecs.open(fullFilename, ‘w’, encoding="utf-8") as jsonFp:
json.dump(jsonValue, jsonFp, indent=2, ensure_ascii=False)
print("Complete save json %s" % fullFilename)
############################################################
# Util Functions
############################################################
def getCurTimestamp(self, withMilliseconds=False):
"""
get current time’s timestamp
(default)not milliseconds -> 10 digits: 1351670162
with milliseconds -> 13 digits: 1531464292921
"""
curDatetime = datetime.now()
return self.datetimeToTimestamp(curDatetime, withMilliseconds)
def datetimeToTimestamp(self, datetimeVal, withMilliseconds=False) :
"""
convert datetime value to timestamp
eg:
"2006-06-01 00:00:00.123" -> 1149091200
if with milliseconds -> 1149091200123
:param datetimeVal:
:return:
"""
timetupleValue = datetimeVal.timetuple()
timestampFloat = time.mktime(timetupleValue) # 1531468736.0 -> 10 digits
timestamp10DigitInt = int(timestampFloat) # 1531468736
timestampInt = timestamp10DigitInt
if withMilliseconds:
microsecondInt = datetimeVal.microsecond # 817762
microsecondFloat = float(microsecondInt)/float(1000000) # 0.817762
timestampFloat = timestampFloat + microsecondFloat # 1531468736.817762
timestampFloat = timestampFloat * 1000 # 1531468736817.7621 -> 13 digits
timestamp13DigitInt = int(timestampFloat) # 1531468736817
timestampInt = timestamp13DigitInt
return timestampInt
结果问题依旧:
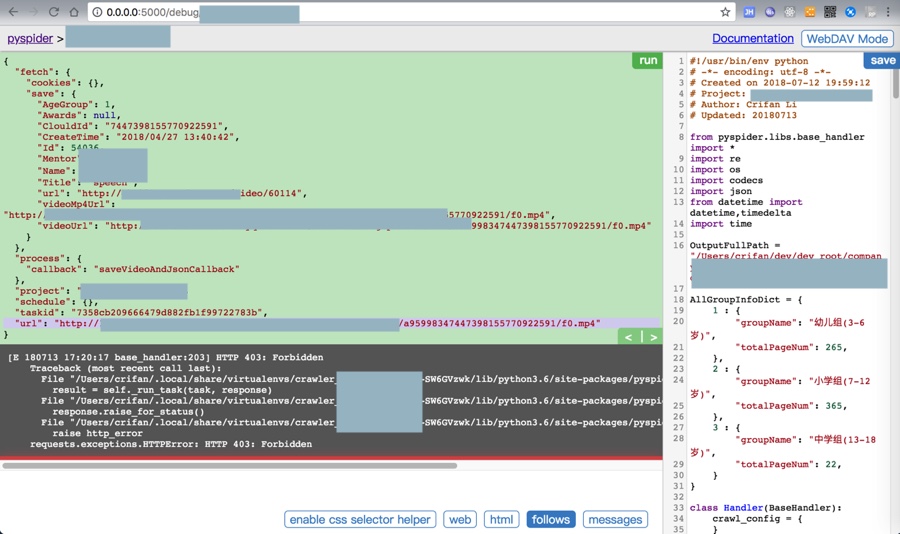
pyspider requests.exceptions.HTTPError HTTP 403 Forbidden
python 爬虫 url error : HTTP 403 Forbidden – CSDN博客
去给PySpider中加上User-Agent试试
同时,加上header:
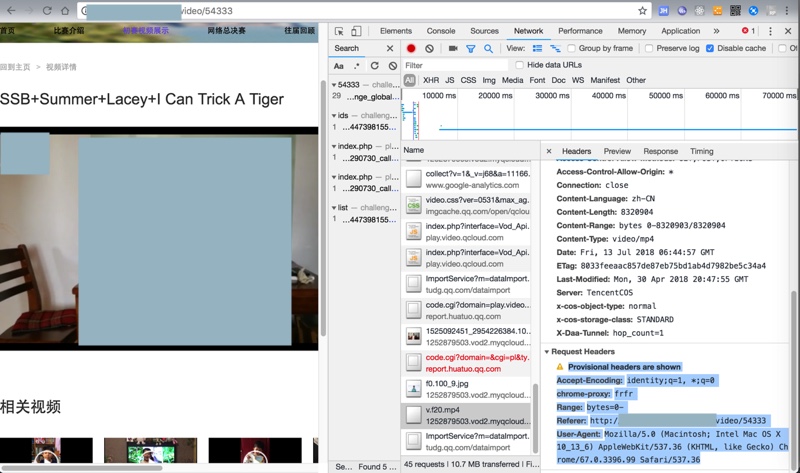
1. Provisional headers are shown
2. Accept-Encoding:
identity;q=1, *;q=0
3. chrome-proxy:
frfr
4. Range:
bytes=0-
5. Referer:
http://xxx/video/54333
6. User-Agent:
Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36
期间还是要去参考:
pyspider HTTPError HTTP 403 Forbidden
pyspider HTTP 403 Forbidden user-agent
HTTP 403: Forbidden · Issue #165 · binux/pyspider
pyspider 爬虫教程(二):AJAX 和 HTTP | Binuxの杂货铺
‘headers’: {‘User-Agent’: ‘xxxx’}
代码:
UserAgentMacChrome = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36’
class Handler(BaseHandler):
crawl_config = {
‘headers’: {
‘User-Agent’: UserAgentMacChrome,
}
}
if videoMp4Url:
headerDict = {
"Accept-Encoding": "identity;q=1, *;q=0",
"chrome-proxy": "frfr",
"Range": "bytes=0-",
"Referer": respDict["url"],
‘User-Agent’: UserAgentMacChrome,
}
print("headerDict=%s" % headerDict)
self.crawl(
videoMp4Url,
headers=headerDict,
cookies=response.cookies,
callback=self.saveVideoAndJsonCallback,
save=respDict)
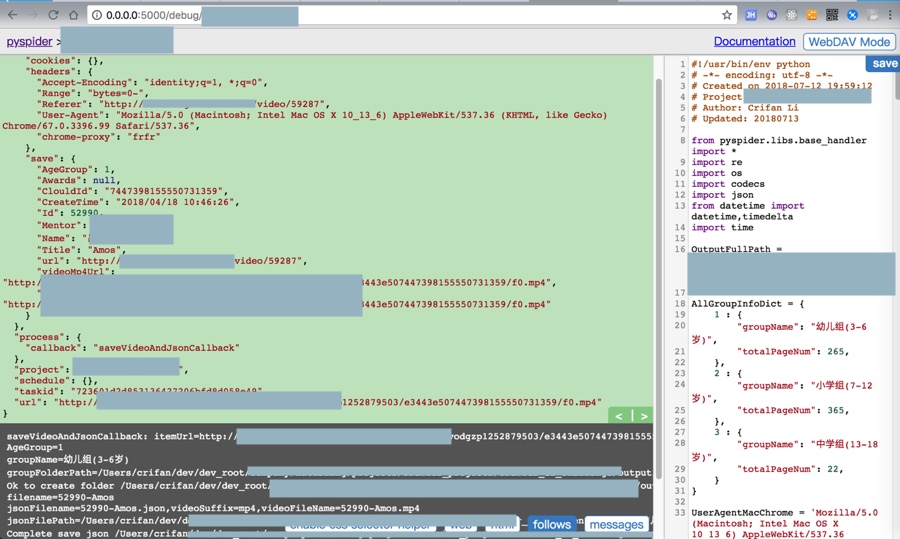
结果:
还真的可以下载了:
【总结】
此处PySpider中,去下载一个mp4视频,出错:
requests.exceptions.HTTPError HTTP 403 Forbidden
原因是:
没有提供对应的参数和header
解决办法:
加上(在调试期间看到的所有的)header:
UserAgentMacChrome = ‘Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36’
class Handler(BaseHandler):
crawl_config = {
‘headers’: {
‘User-Agent’: UserAgentMacChrome,
}
}
def getPlayInfoCallback(self, response):
if videoMp4Url:
headerDict = {
"Accept-Encoding": "identity;q=1, *;q=0",
"chrome-proxy": "frfr",
"Range": "bytes=0-",
"Referer": respDict["url"],
‘User-Agent’: UserAgentMacChrome,
}
print("headerDict=%s" % headerDict)
self.crawl(
videoMp4Url,
headers=headerDict,
cookies=response.cookies,
callback=self.saveVideoAndJsonCallback,
save=respDict)
即可正常下载和爬取。
另外再去搞懂:
【无需解决】Chrome中Request Headers中Provisional headers are shown的含义
转载请注明:在路上 » 【已解决】PySpider中下载mov文件出错:requests.exceptions.HTTPError HTTP 403 Forbidden