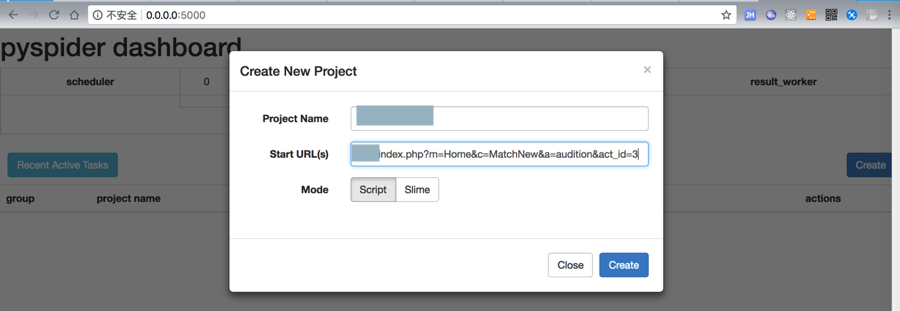
需要去爬取:
xxxxxxxx大赛
http://xxx/index.php?m=Home&c=MatchNew&a=audition&act_id=3
《老鼠xx》xxx大赛开始了!
http:/www/index.php?m=Home&c=MatchNew&a=audition&act_id=4
xxx(全国)xx英语大赛
http://xxx/index.php?m=Home&c=MatchNew&a=audition&act_id=7
中的视频和相关信息。
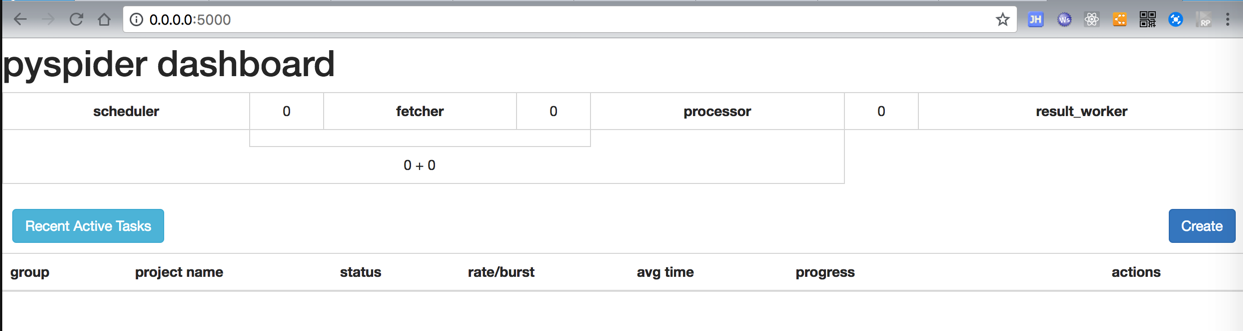
先去本地用虚拟环境工具pipenv创建个虚拟环境,然后去安装搭建PySpider环境
【已解决】pipenv install PySpider卡死在:Locking [packages] dependencies
那就先去开始开发,之后再去操心pipenv的lock卡死的问题。
<code>pyspider </code>
然后去打开:
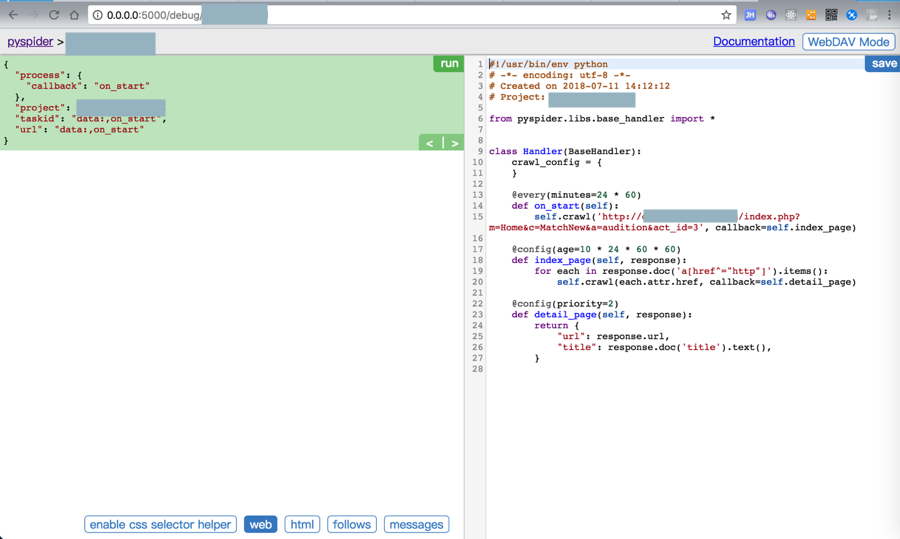
<code>#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-07-11 14:12:12
# Project: xxx
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://xxx/index.php?m=Home&c=MatchNew&a=audition&act_id=3', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
</code>然后就是去研究了:
http://xxx/index.php?m=Home&c=MatchNew&a=audition&act_id=3
页面下拉加载更多后,请求是:
<code>POST http://xxx/index.php?m=home&c=match_new&a=get_shows form data: url-encoded counter=1&order=1&match_type=2&match_name=&act_id=3 counter=2&order=1&match_type=2&match_name=&act_id=3 ... counter=5&order=1&match_type=2&match_name=&act_id=3 </code>
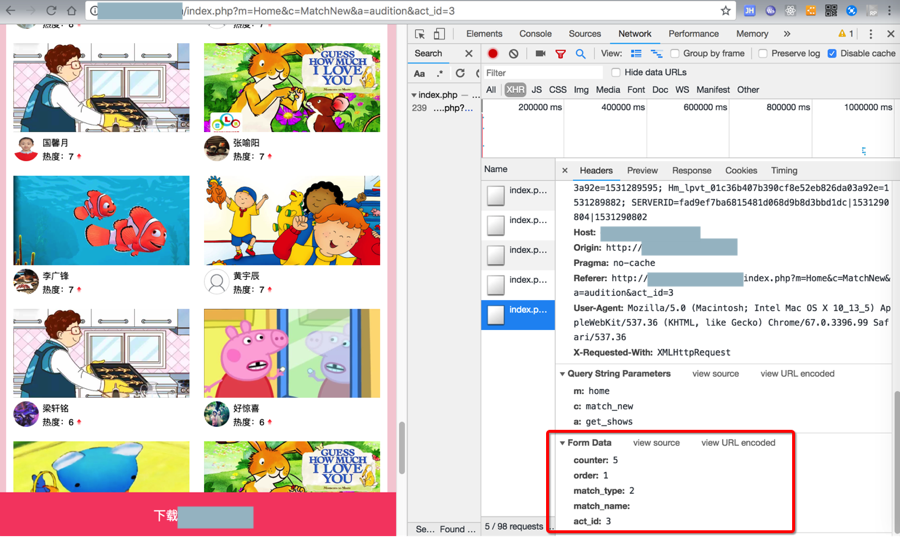
即可返回要的数据:
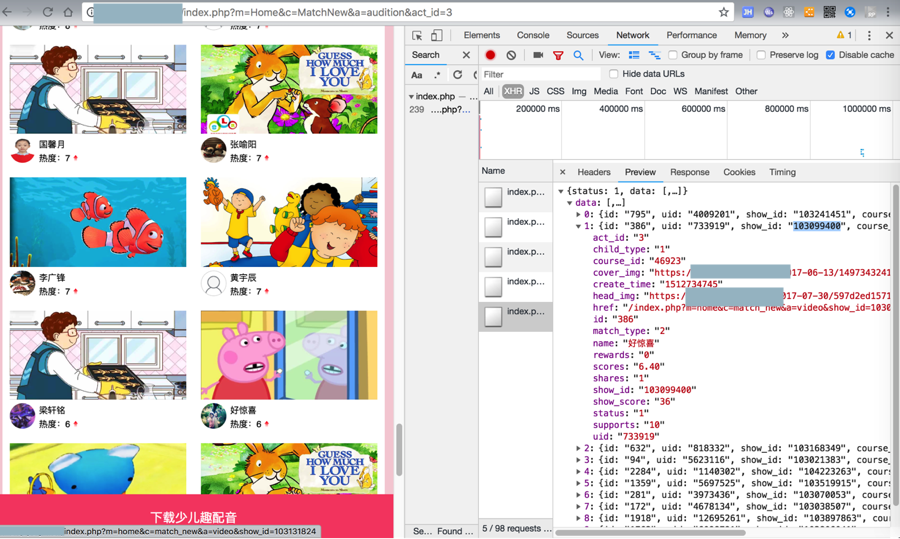
<code>{"status":1,"data":[{"id":"795","uid":"4009201","show_id":"103241451","course_id":"41758","supports":"11","rewards":"0","shares":"0","scores":"6.60","status":"1","match_type":"2","create_time":"1512790165","act_id":"3","child_type":"1","show_score":"0","head_img":"https:\/\/x.x.x\/2017-11-20\/5a129fb13791d.jpg","cover_img":"https:\/\/x.x.x\/2017-03-15\/58c8abf7eafb6.jpg","name":"\u6881\u8f69\u94ed","href":"\/index.php?m=home&c=match_new&a=video&show_id=103241451"},{"id":"386","uid":"733919","show_id":"103099400","course_id":"46923","supports":"10","rewards":"0","shares":"1","scores":"6.40","status":"1","match_type":"2","create_time":"1512734745","act_id":"3","child_type":"1","show_score":"36","head_img":"https:\/\/x.x.x\/2017-07-30\/597d2ed157131.jpg","cover_img":"https:\/\/x.x.x\/2017-06-13\/14973432415241.jpg","name":"\u597d\u60ca\u559c","href":"\/index.php?m=home&c=match_new&a=video&show_id=103099400"},{"id":"632","uid":"818332","show_id":"103168349","course_id":"17734","supports":"9","rewards":"0","shares":"2","scores":"6.20","status":"1","match_type":"2","create_time":"1512741739","act_id":"3","child_type":"1","show_score":"92","head_img":"https:\/\/x.x.x\/2017-04-06\/58e5d0d774270.jpg","cover_img":"https:\/\/x.x.x\/2018-06-04\/5b14e22b8850a.jpg","name":"\u97e9\u6653\u5915","href":"\/index.php?m=home&c=match_new&a=video&show_id=103168349"},{"id":"94","uid":"5623116","show_id":"103021383","course_id":"22740","supports":"9","rewards":"0","shares":"2","scores":"6.20","status":"1","match_type":"2","create_time":"1512710369","act_id":"3","child_type":"1","show_score":"0","head_img":"http:\/\/q.qlogo.cn\/qqapp\/1104670989\/D3CE41F908B81149927A05914792468D\/100","cover_img":"https:\/\/x.x.x\/2017-12-12\/5a2f790ed12cf.jpg","name":"\u5434\u6850","href":"\/index.php?m=home&c=match_new&a=video&show_id=103021383"},{"id":"2284","uid":"1140302","show_id":"104223263","course_id":"22740","supports":"9","rewards":"0","shares":"1","scores":"5.80","status":"1","match_type":"2","create_time":"1513163554","act_id":"3","child_type":"1","show_score":"0","head_img":"https:\/\/x.x.x\/2016-10-16\/5802ffe1b3419.jpg","cover_img":"https:\/\/x.x.x\/2017-12-12\/5a2f790ed12cf.jpg","name":"\u8d75\u6668\u6c50","href":"\/index.php?m=home&c=match_new&a=video&show_id=104223263"},{"id":"1359","uid":"5697525","show_id":"103519915","course_id":"43716","supports":"9","rewards":"0","shares":"1","scores":"5.80","status":"1","match_type":"2","create_time":"1512879173","act_id":"3","child_type":"1","show_score":"0","head_img":"https:\/\/x.x.x\/2018-06-23\/5b2de55693ad9.jpg","cover_img":"https:\/\/x.x.x\/2017-02-23\/58ae9dec28283.jpg","name":"\u5510\u6615\u73a5","href":"\/index.php?m=home&c=match_new&a=video&show_id=103519915"},{"id":"281","uid":"3973436","show_id":"103070053","course_id":"41758","supports":"8","rewards":"0","shares":"2","scores":"5.60","status":"1","match_type":"2","create_time":"1512731030","act_id":"3","child_type":"1","show_score":"0","head_img":"https:\/\/x.x.x\/2018-07-05\/5b3d677fe90ce.jpg","cover_img":"https:\/\/x.x.x\/2017-03-15\/58c8abf7eafb6.jpg","name":"\u6881\u4e50","href":"\/index.php?m=home&c=match_new&a=video&show_id=103070053"},{"id":"172","uid":"4678134","show_id":"103038507","course_id":"41758","supports":"8","rewards":"0","shares":"2","scores":"5.60","status":"1","match_type":"2","create_time":"1512725033","act_id":"3","child_type":"1","show_score":"94","head_img":"https:\/\/x.x.x\/2018-01-24\/5a68647cd462b.jpg","cover_img":"https:\/\/x.x.x\/2017-03-15\/58c8abf7eafb6.jpg","name":"\u8427\u4fca\u9091","href":"\/index.php?m=home&c=match_new&a=video&show_id=103038507"},{"id":"1918","uid":"12695261","show_id":"103897863","course_id":"43713","supports":"9","rewards":"0","shares":"0","scores":"5.40","status":"1","match_type":"2","create_time":"1512997970","act_id":"3","child_type":"1","show_score":"88","head_img":"https:\/\/x.x.x\/Public\/static\/avatar_default.png","cover_img":"https:\/\/x.x.x\/2017-02-23\/58ae9e49a1353.jpg","name":"\u8c22\u80e4\u9e92","href":"\/index.php?m=home&c=match_new&a=video&show_id=103897863"},{"id":"1762","uid":"6098791","show_id":"103806041","course_id":"43718","supports":"9","rewards":"0","shares":"0","scores":"5.40","status":"1","match_type":"2","create_time":"1512990207","act_id":"3","child_type":"1","show_score":"95","head_img":"https:\/\/x.x.x\/1526815032729.jpg","cover_img":"https:\/\/x.x.x\/2017-02-23\/58ae9ef2e9b20.jpg","name":"\u8bfa\u8bfa\uff5e\u80d6\u80d6","href":"\/index.php?m=home&c=match_new&a=video&show_id=103806041"}]}
</code>然后就是去看看PySpider中,如何实现POST,且传递url-encoded的form data了。
【已解决】PySpider中如何发送POST请求且传递格式为application/x-www-form-urlencoded的form data参数
然后就是去生成多个url了。
然后接着去:
然后经过后续调试,可以通过:
<code>#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2018-07-11 14:12:12
# Project: xxx
# Author: Crifan Li
# Updated: 20180712
from pyspider.libs.base_handler import *
import re
import os
import codecs
import json
from datetime import datetime,timedelta
xxxUrlRoot = "http://xxx"
OutputFullPath = "/Users/crifan/dev/xxx/output"
MatchInfoDict = {
# act_id -> title,
"3" : {
"title": "xxx大赛",
# para for http://xxx/index.php?m=home&c=match_new&a=get_shows POST
"match_type": "2",
"order": [
"1", # 亲子组
"2" # 好友组
]
},
"4" : {
"title": "xxx2大赛",
# para for http://xxx/index.php?m=home&c=match_new&a=get_shows POST
"match_type": "1",
"order": [
"create_time", # 最新配音
"scores", # 热度总榜
]
},
"7" : {
"title": "yyy赛",
# para for http://xxx?m=home&c=match_new&a=get_shows POST
"match_type": "2",
"order": [
"1", # 学前组
"2" #小学组
]
},
}
class Handler(BaseHandler):
crawl_config = {
}
# @every(minutes=24 * 60)
def on_start(self):
# actIdList = ["3", "4", "7"]
# for debug
actIdList = ["4", "7", "3"]
for curActId in actIdList:
curUrl = "http://xxx/index.php?m=Home&c=MatchNew&a=audition&act_id=%s" % curActId
self.crawl(curUrl, callback=self.indexPageCallback, save=curActId)
# @config(age=10 * 24 * 60 * 60)
def indexPageCallback(self, response):
curActId = response.save
print("curActId=%s" % curActId)
# <ul class="list-user list-user-1" id="list-user-1">
for each in response.doc('ul[id^="list-user"] li a[href^="http"]').items():
self.crawl(each.attr.href, callback=self.showVideoCallback, save=curActId)
# <ul class="list-user list-user-1" id="list-user-1">
# <ul class="list-user list-user-2" id="list-user-2">
curPageNum = 1
curMatchOrderList = MatchInfoDict[curActId]["order"]
match_type = MatchInfoDict[curActId]["match_type"]
print("curMatchOrderList=%s,match_type=%s" % (curMatchOrderList, match_type))
for curOrder in curMatchOrderList:
print("curOrder=%s" % curOrder)
getShowsParaDict = {
"counter": curPageNum,
"order": curOrder,
"match_type": match_type,
"match_name": "",
"act_id": curActId
}
self.getNextPageShow(response, getShowsParaDict)
def getNextPageShow(self, response, getShowsParaDict):
"""
recursively get next page shows until fail
"""
print("getNextPageShow: getShowsParaDict=%s" % getShowsParaDict)
getShowsUrl = "http://xxx/index.php?m=home&c=match_new&a=get_shows"
headerDict = {
"Content-Type": "application/x-www-form-urlencoded"
}
timestampStr = datetime.now().strftime("%Y%m%d_%H%M%S_%f")
getShowsUrlWithHash = getShowsUrl + "#" + timestampStr
#20180712_154134_660436_1_2_4
fakeItagForceRecrawl = "%s_%s_%s_%s" % (
timestampStr,
getShowsParaDict["counter"],
getShowsParaDict["order"],
getShowsParaDict["act_id"]
)
self.crawl(
getShowsUrlWithHash,
itag=fakeItagForceRecrawl, # To force re-crawl for next page
method="POST",
headers=headerDict,
data=getShowsParaDict,
cookies=response.cookies,
callback=self.parseGetShowsCallback,
save=getShowsParaDict
)
def parseGetShowsCallback(self, response):
print("parseGetShowsCallback: self=%s, response=%s"%(self, response))
respJson = response.json
prevPageParaDict = response.save
print("prevPageParaDict=%s, respJson=%s" % (prevPageParaDict, respJson))
if respJson["status"] == 1:
respData = respJson["data"]
# recursively try get next page shows
prevPageParaDict["counter"] = prevPageParaDict["counter"] + 1
self.getNextPageShow(response, prevPageParaDict)
for eachData in respData:
# print("type(eachData)=" % type(eachData))
showId = eachData["show_id"]
href = eachData["href"]
fullUrl = xxxUrlRoot + href
print("[%s] fullUrl=%s" % (showId, fullUrl))
curShowInfoDict = eachData
self.crawl(
fullUrl,
callback=self.showVideoCallback,
save=curShowInfoDict)
else:
print("!!! Fail to get shows json from %s" % response.url)
# @config(priority=2)
def showVideoCallback(self, response):
print("showVideoCallback: response.url=%s" % (response.url))
curShowInfoDictOrActId = response.save
print("curShowInfoDictOrActId=%s" % curShowInfoDictOrActId)
act_id = ""
curShowInfoDict = None
if isinstance(curShowInfoDictOrActId, str):
act_id = curShowInfoDictOrActId
print("para is curActId")
elif isinstance(curShowInfoDictOrActId, dict):
curShowInfoDict = curShowInfoDictOrActId
print("para is curShowInfoDict")
else:
print("!!! can not recognize parameter for showVideoCallback")
title = response.doc('span[class="video-title"]').text()
show_id = ""
name = ""
scores = "" # 热度
supports = "" # 点赞数
shares = "" # 被分享数
# <video controls="" class="video-box" poster="https://xxx/2017-02-23/58ae9dec28283.jpg" id="myVideo">
# <source src="https://xxx/2017-12-15/id1513344895u878964.mp4" type="video/mp4"> 您的浏览器不支持Video标签。
# </video>
# videoUrl = response.doc('video source[src$=".mp4"]')
videoUrl = response.doc('video source[src^="http"]').attr("src")
print("title=%s" % title)
if curShowInfoDict:
act_id = curShowInfoDict["act_id"]
print("inside curShowInfoDict: set act_id to %s" % act_id)
show_id = curShowInfoDict["show_id"]
name = curShowInfoDict["name"]
scores = curShowInfoDict["scores"]
supports = curShowInfoDict["supports"]
shares = curShowInfoDict["shares"]
else:
#<a href="javascript:;" class="sign-btn" id="redirect_show" sid="104728193" onclick="pauseVid()">投票传送门</a>
show_id = response.doc('a[id="redirect_show"]').attr("sid")
# <div class="v-user">
# <span class="v-user-name">徐欣蕊</span>
# <span>热度:65.00</span>
name = response.doc('span[class="v-user-name"]').text()
scoresText = response.doc('div[class="v-user"] span:nth-child(2)').text()
print("scoresText=%s" % scoresText)
scoresMatch = re.search("热度:(?P<scoresFloatText>[\d\.]+)", scoresText)
print("scoresMatch=%s" % scoresMatch)
if scoresMatch:
scores = scoresMatch.group("scoresFloatText")
print("scores=%s" % scores)
# <ul>
# <li class="li-1">
# <img src="https://x.x.x/Home/images/dubbing/icon6.png?201806116141">
# <span>107次</span>
# </li>
# <li class="li-2">
# <img src="https://x.x.x/Home/images/dubbing/icon8.png?201806116141">
# <span>2次</span>
# </li>
# </ul>
supportsText = response.doc('ul li[class="li-1"] span').text()
supportsMatch = re.search("(?P<supportIntText>\d+)次", supportsText)
print("supportsMatch=%s" % supportsMatch)
if supportsMatch:
supports = supportsMatch.group("supportIntText")
print("supports=%s" % supports)
sharesText = response.doc('ul li[class="li-2"] span').text()
sharesMatch = re.search("(?P<sharesIntText>\d+)次", sharesText)
print("sharesMatch=%s" % sharesMatch)
if sharesMatch:
shares = sharesMatch.group("sharesIntText")
print("shares=%s" % shares)
respDict = {
"url": response.url,
"act_id": act_id,
"title": title,
"show_id": show_id,
"name": name,
"scores": scores,
"supports": supports,
"shares": shares,
"videoUrl": videoUrl
}
self.crawl(
videoUrl,
callback=self.saveVideoAndJsonCallback,
save=respDict)
return respDict
def saveVideoAndJsonCallback(self, response):
itemUrl = response.url
print("saveVideoAndJsonCallback: itemUrl=%s,response=%s" % (itemUrl, response))
itemInfoDict = response.save
curActId = itemInfoDict["act_id"]
print("curActId=%s" % curActId)
matchName = MatchInfoDict[curActId]["title"]
print("matchName=%s" % matchName)
matchFolderPath = os.path.join(OutputFullPath, matchName)
print("matchFolderPath=%s" % matchFolderPath)
if not os.path.exists(matchFolderPath):
os.makedirs(matchFolderPath)
print("Ok to create folder %s" % matchFolderPath)
filename = "%s-%s-%s" % (
itemInfoDict["show_id"],
itemInfoDict["name"],
itemInfoDict["title"])
print("filename=%s" % filename)
jsonFilename = filename + ".json"
videoSuffix = itemUrl.split(".")[-1]
videoFileName = filename + "." + videoSuffix
print("jsonFilename=%s,videoSuffix=%s,videoFileName=%s" % (jsonFilename, videoSuffix, videoFileName))
# {
# 'act_id': '7',
# 'name': '李冉月',
# 'scores': '22.50',
# 'shares': '1',
# 'show_id': '138169051',
# 'supports': '44',
# 'title': '【激情】坚持到底不放弃',
# 'url': 'http://x.x.x/index.php?m=home&c=match_new&a=video&show_id=138169051',
# 'videoUrl': 'https://cdnx.x.x/2018-06-03/152798389836832449205.mp4'
# }
jsonFilePath = os.path.join(matchFolderPath, jsonFilename)
print("jsonFilePath=%s" % jsonFilePath)
self.saveJsonToFile(jsonFilePath, itemInfoDict)
videoBinData = response.content
videoFilePath = os.path.join(matchFolderPath, videoFileName)
self.saveDataToFile(videoFilePath, videoBinData)
def saveDataToFile(self, fullFilename, binaryData):
with open(fullFilename, 'wb') as fp:
fp.write(binaryData)
fp.close()
print("Complete save file %s" % fullFilename)
def saveJsonToFile(self, fullFilename, jsonValue):
with codecs.open(fullFilename, 'w', encoding="utf-8") as jsonFp:
json.dump(jsonValue, jsonFp, indent=2, ensure_ascii=False)
print("Complete save json %s" % fullFilename)
</code>去下载mp4视频和json信息到本地了:
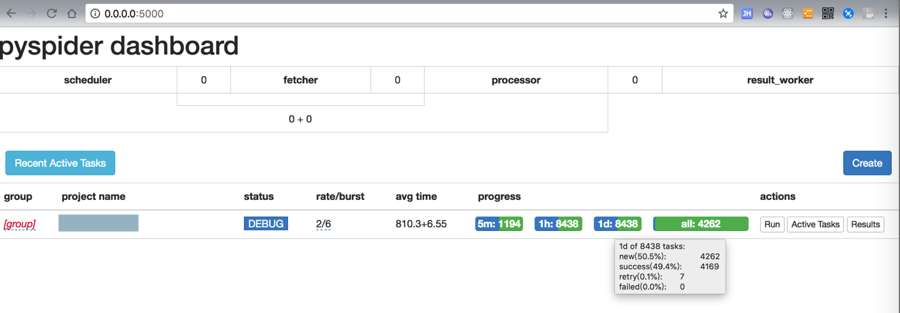
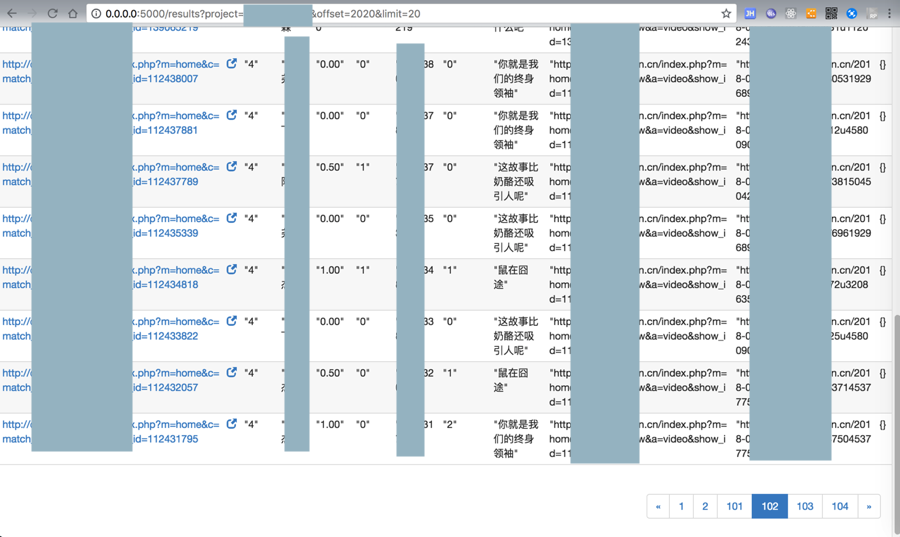
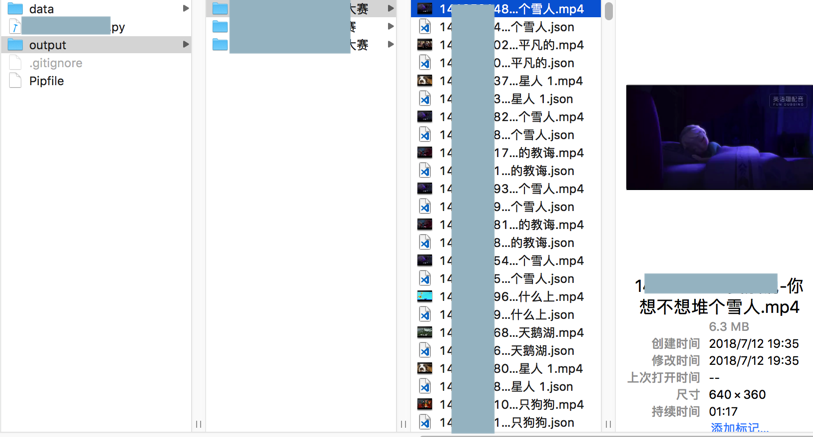
【后记】
【无法解决】PySpider的部署运行而非调试界面上RUN运行
不过经过好几个小时的运行,最后终于爬取完毕了:
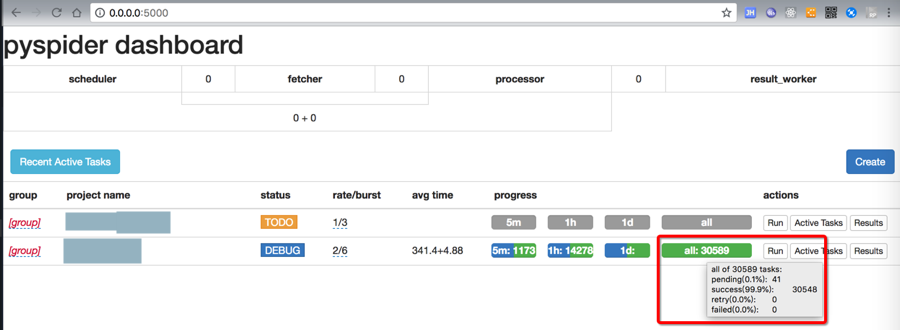
共3万多个,其中一半感觉是(mp4的)url是重复的,所以实际视频只有1万5千个左右。
转载请注明:在路上 » 【已解决】使用PySpider去爬取某网站中的视频