折腾:
【未解决】php中用正则过滤html中code中多余span标签
期间,印象笔记帖子内容中html有嵌套,所以用之前正则不是很好写,所以考虑用html的lib去解析和处理。
php html lib
【未解决】用php的html库php-html-parser去解析处理印象笔记html源码
再去试试另外的库:
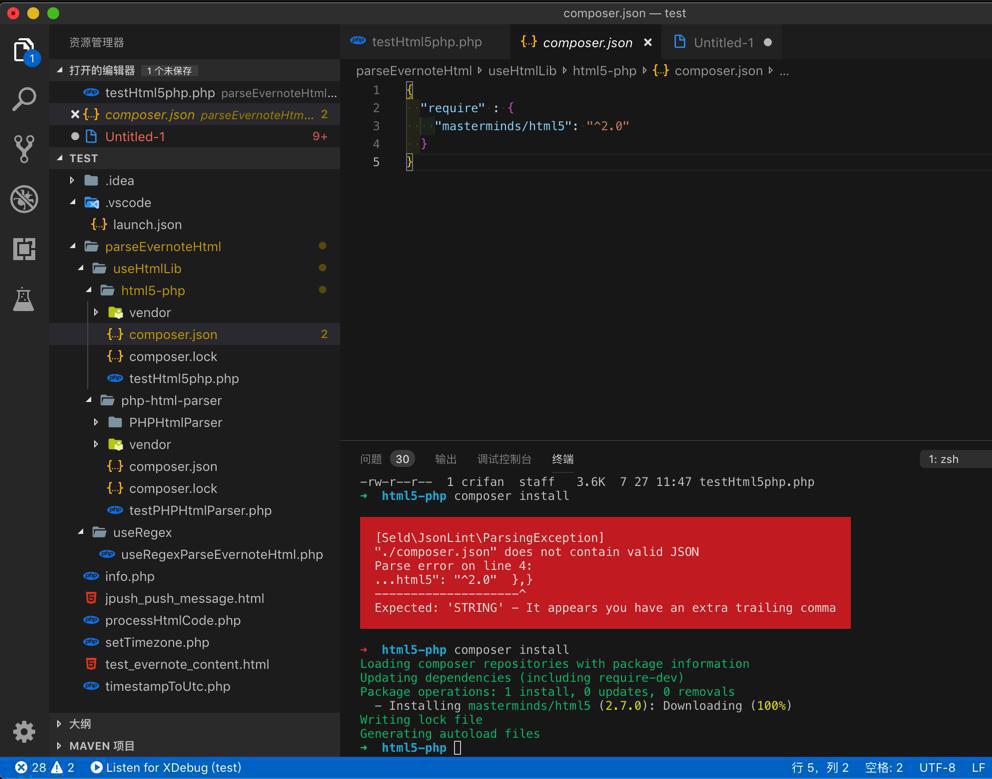
1 2 3 4 5 | { "require" : { "masterminds/html5": "^2.0" }} |
安装:
1 2 3 4 5 6 7 | ➜ html5-php composer installLoading composer repositories with package informationUpdating dependencies (including require-dev)Package operations: 1 install, 0 updates, 0 removals - Installing masterminds/html5 (2.7.0): Downloading (100%) Writing lock fileGenerating autoload files |
但是具体如何使用:
没解释
去看看:
用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | <?php// Assuming you installed from Composer:require "vendor/autoload.php";use Masterminds\HTML5;$originEvernoteHtml = 'xxx';// $originEvernoteHtml = "<div>" . $originEvernoteHtml . "</div>";$originEvernoteHtml = "<html><head><title>parse evernote html</title></head><body>" . $originEvernoteHtml . "</body></html>";// Parse the document. $dom is a DOMDocument.$html5 = new HTML5();$dom = $html5->loadHTML($originEvernoteHtml);// Render it as HTML5:$htmlStr = $html5->saveHTML($dom);print $htmlStr;// $codeBlockHtml = $dom->find('div')[0];// echo("codeBlockHtml=".$codeBlockHtml);// error_log($codeBlockHtml);?> |
是可以输出html:
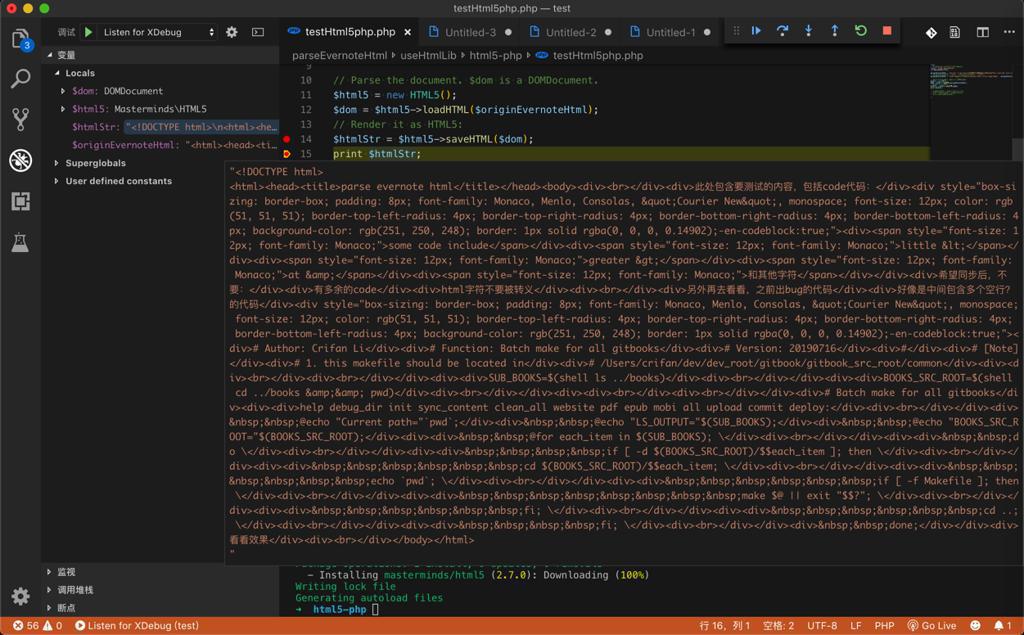
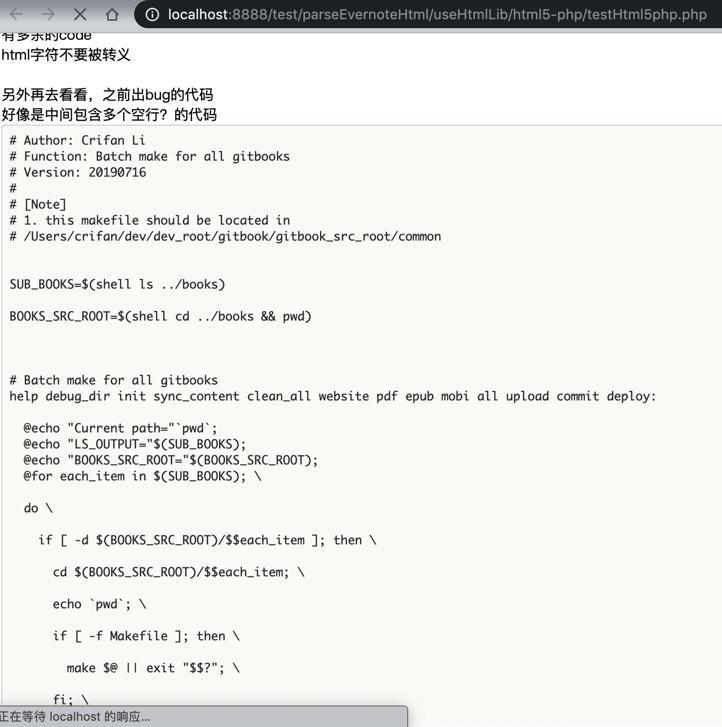
但是却不支持解析
那去换别的库:
【未解决】用php的html解析库simplehtmldom解析印象笔记帖子的html源码
转载请注明:在路上 » 【未解决】php中用html解析库去解析处理印象笔记的html源码