对于:
之前已经回复了:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | 又去看了看,目前有点怀疑:你windows的cmd,可能本身是unicode了,所以不会报错。而你VSCode时,内置的终端 默认是GBK,而其中某些字符不支持(因为本身GBK支持的字符就不是足够多,只是GB18030的子集)所以建议:把终端编码改为 BG18030 去看看效果,或许就可以了。把终端输出编码改为GB18030:sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')方式2:sys.stdout.reconfigure(encoding=‘GB18030’)另外,为了调试确认编码的确已改,最好在之前和之后都加上:print(“sys.stdout.encoding=%s” % sys.stdout.encoding)以及:其他查看一些信息import sys, locale, osprint(sys.stdout.encoding)print(sys.stdout.isatty())print(locale.getpreferredencoding())print(sys.getfilesystemencoding())print(os.environ["PYTHONIOENCODING"])-》这样便于调试清楚 更改编码 之前 和 之后,各个变量和编码是否有变化 具体是什么值 方便找出问题所在。 |
但是问题依旧没解决。
所以再去深入研究看看:
UnicodeEncodeError gbk codec can’t encode character ‘\xa9’ in position 3738 illegal multiple sequence
UnicodeEncodeError gbk encode character ‘\xa9’
1 | sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') |
感觉像是
此处的GBK编码去输出,但是个别字符GBK编码不支持
所以报错
那么估计:转换此处输出的终端的编码为GB18030 估计就可以了?
python windows print encoding
PEP 528 — Change Windows console encoding to UTF-8 | Python.org
sys.stdout.encoding
python change sys.stdout.encoding
1 | sys.stdout.reconfigure(encoding='utf-8') |
总的来说就是:
去尝试把终端输出编码改为GB18030试试
方式1:
1 | sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') |
方式2:
1 | sys.stdout.reconfigure(encoding=‘GB18030’) |
另外,为了调试确认编码的确已改,最好在之前和之后都加上:
1 | print(“sys.stdout.encoding=%s” % sys.stdout.encoding) |
即:
1 2 3 | print(“sys.stdout.encoding=%s” % sys.stdout.encoding)sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030')print(“sys.stdout.encoding=%s” % sys.stdout.encoding) |
或:
1 2 3 | print(“sys.stdout.encoding=%s” % sys.stdout.encoding)sys.stdout.reconfigure(encoding=‘GB18030’)print(“sys.stdout.encoding=%s” % sys.stdout.encoding) |
另外,为了研究和清楚当前编码,最好都去打印出来看看
1 2 3 4 5 6 | import sys, locale, osprint(sys.stdout.encoding)print(sys.stdout.isatty())print(locale.getpreferredencoding())print(sys.getfilesystemencoding())print(os.environ["PYTHONIOENCODING"]) |
不过后来搜:
gbk \xa9
找到更多相关内容:
-》
想起来,前面在
就注意到:
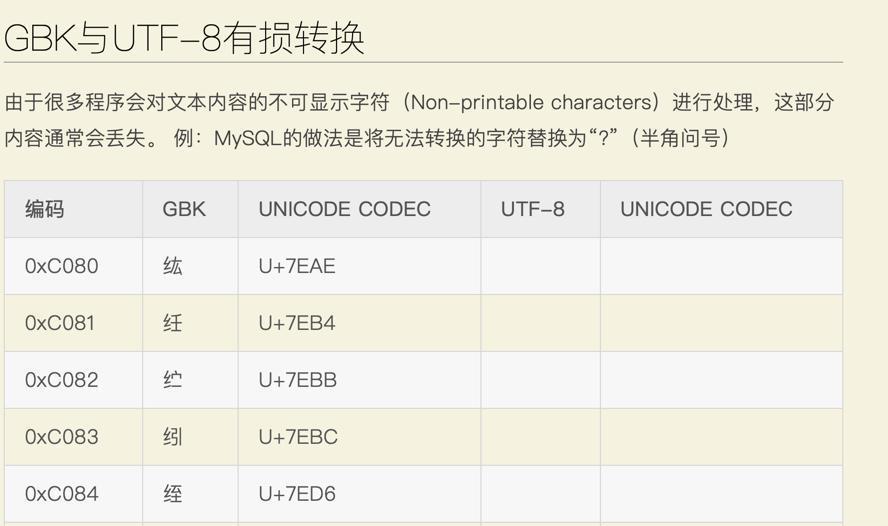
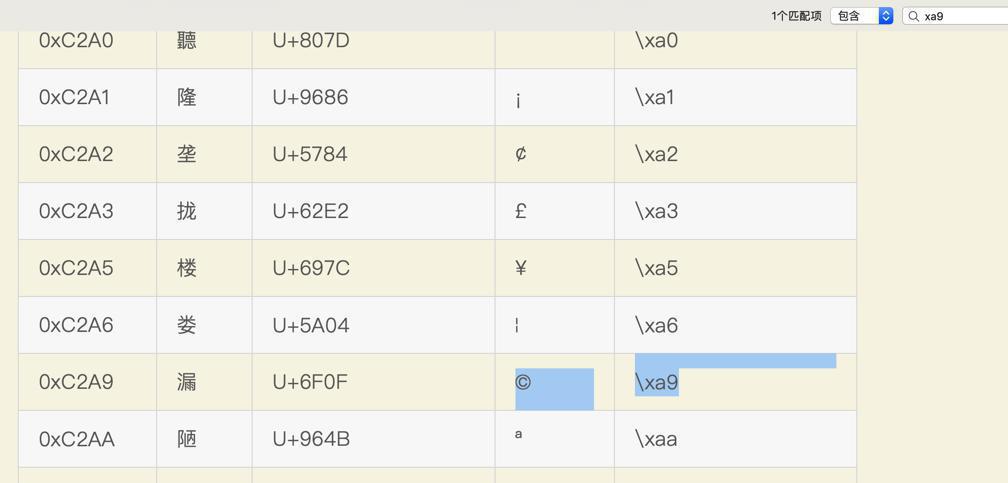
-》即:
1 | \xa9 |
就是:
字符
1 | © |
另外
1 2 3 | # Linux平台默认情况下就是UTF-8编码,所以以下结果就是UTF-8编码值>>> '驹''\xe9\xa9\xb9' |
顺带了解了:\xa9是 驹 的UTF-8 的3个字节 中的其中一个字节
更主要的是
发现直接就是原贴的内容:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 | 代码:import requestsres = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html’)print(res.status_code)html = res.textprint(html)报错:Traceback (most recent call last):File “c:/Users/jacky/Desktop/test/fb0520.py”, line 6, inprint(html)UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa9’ in position 3738: illegal multibyte sequence差了很多搜索都一头雾水。于是一个一个来试。最终这个方案管用。import ioimport sys#改变标准输出的默认编码#utf-8中文乱码sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030’)改变之后的代码是这样的:import requestsimport ioimport sysres = requests.get(‘https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html’)sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding=‘gb18030’)html = res.textprint(html)报错问题解决,具体原来还不是非常明白。以现在的水平,解决问题先。 |
即:
完全验证了我之前的推断:
此处就是:
把(包含很多字符的)html输出到 Windows中的(默认编码是GBK的)终端
-》但是报错:
1 | UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa9’ in position 3738: illegal multibyte sequence |
原因:
GBK中,缺少对于某些字符的支持,比如此处的 ©,导致无法编码,所以报错:UnicodeEncodeError
解决办法:
把此处Windows中的终端的编码,改为,支持更多字符的GB18030
而把Windows中的 系统终端输出编码改为GB18030
方法1:
1 | sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') |
方法2:
1 | sys.stdout.reconfigure(encoding='GB18030') |
另外,再去额外验证自己的推断:
GBK中,报错的字符的确是3738位置的@,对应着 \xa9
所以自己写代码去试试:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | import requests #调用requests库res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') #获取网页源代码,得到的res是response对象print(res.status_code) #检查请求是否正确响应html = res.text #把res的内容以字符串的形式返回htmlCharNum = len(html)print("htmlCharNum=%s" % htmlCharNum)htmlBytes = res.contenthtmlByteNum = len(htmlBytes)print("htmlByteNum=%s" % htmlByteNum)errorPositionNum = 3738errorPositionIdx = errorPositionNum - 1# errorByte = htmlBytes[errorPositionNum]errorByte = htmlBytes[errorPositionIdx]print("errorByte=%s" % errorByte) |
index=3738是 60
index=3737是 32
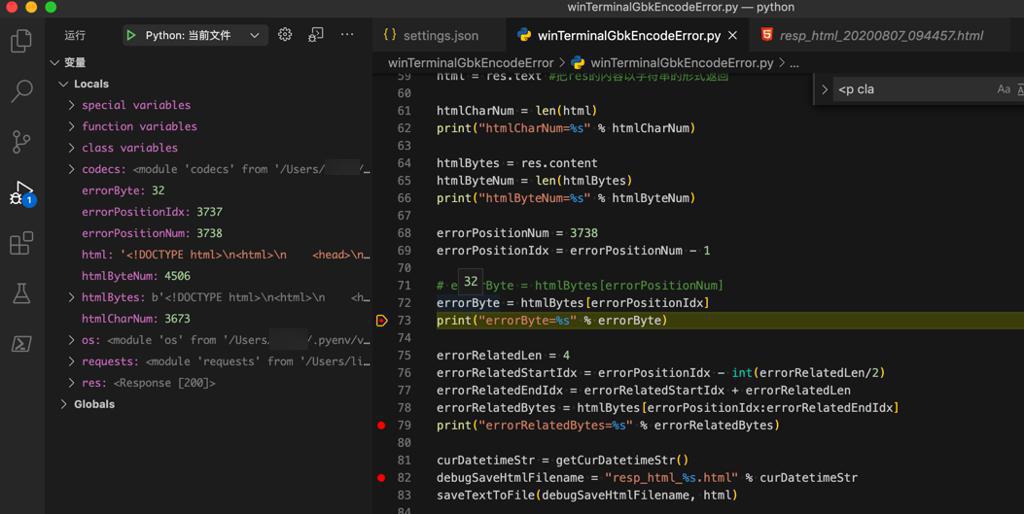
-》感觉错误的字符串,不是这个位置的。
-》加上后续调试:
1 2 3 4 5 6 7 8 9 10 | errorRelatedLen = 10errorRelatedStartIdx = errorPositionIdx - int(errorRelatedLen/2)errorRelatedEndIdx = errorRelatedStartIdx + errorRelatedLenerrorRelatedBytes = htmlBytes[errorPositionIdx:errorRelatedEndIdx]print("errorRelatedBytes=%s" % errorRelatedBytes)curDatetimeStr = getCurDatetimeStr()debugSaveHtmlFilename = "resp_html_%s.html" % curDatetimeStrsaveTextToFile(debugSaveHtmlFilename, html) |
看看出错的位置前后一段代码,发现是:
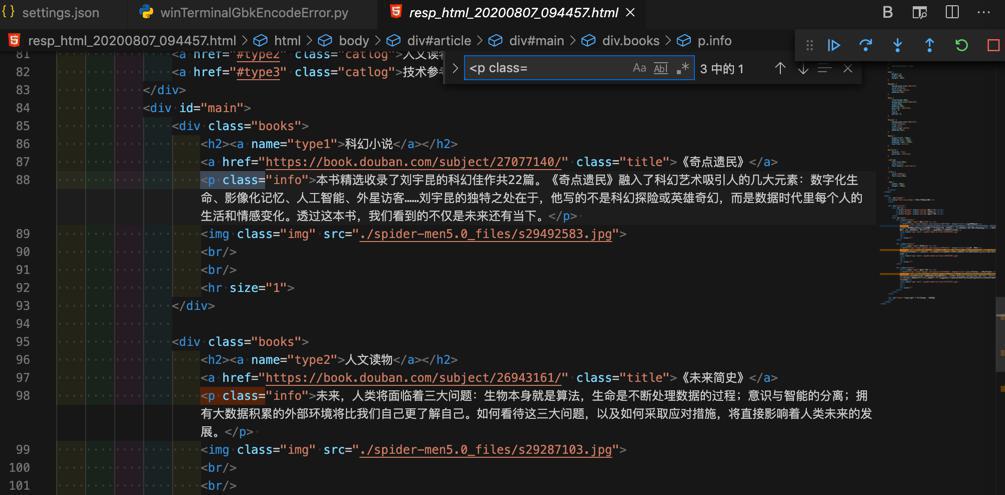
1 | b' <p class=' |
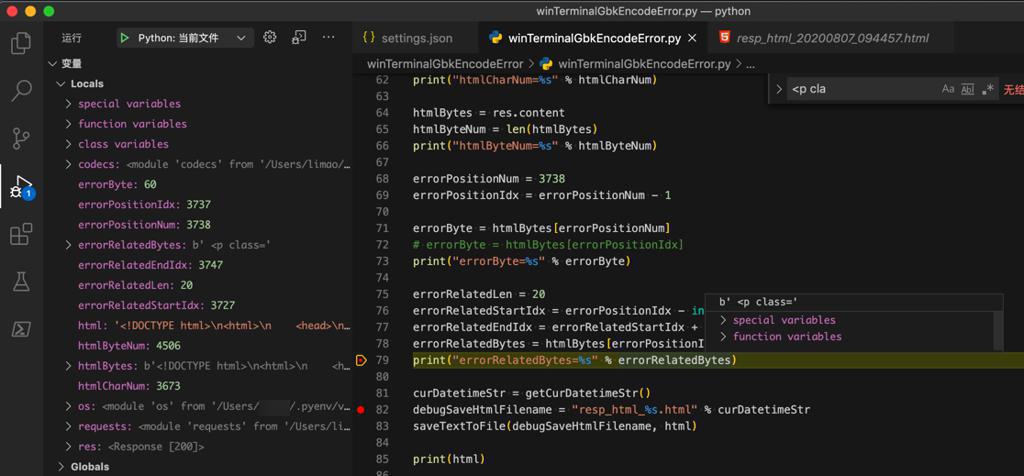
而html中
1 | <p class= |
有3处:
且前后也没有特殊的,感觉是GBK无法支持的字符啊:
所以:基本上推断
此处报错的位置:3738
是GBK编码后的字符的值
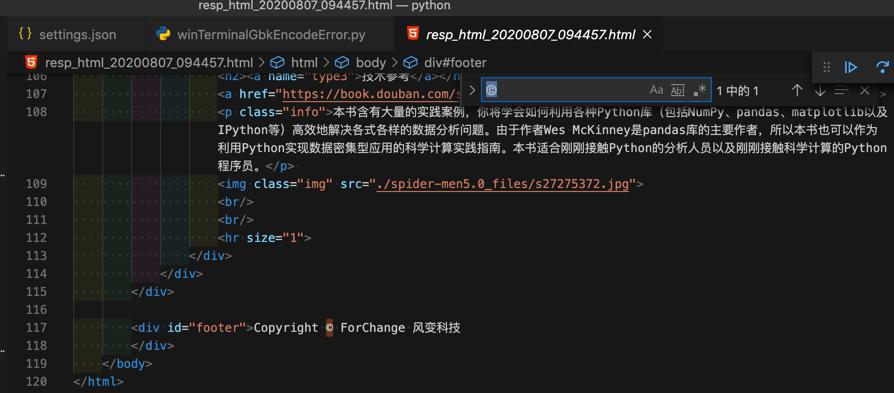
另外,早就看到了,此处html中最后是有©这个字符的:
1 2 | <div id="footer">Copyright © ForChange 风变科技 </div> |
-》怀疑是这个字符,GBK无法编码的
所以,重新写调试代码,直接用gbk去encode看看
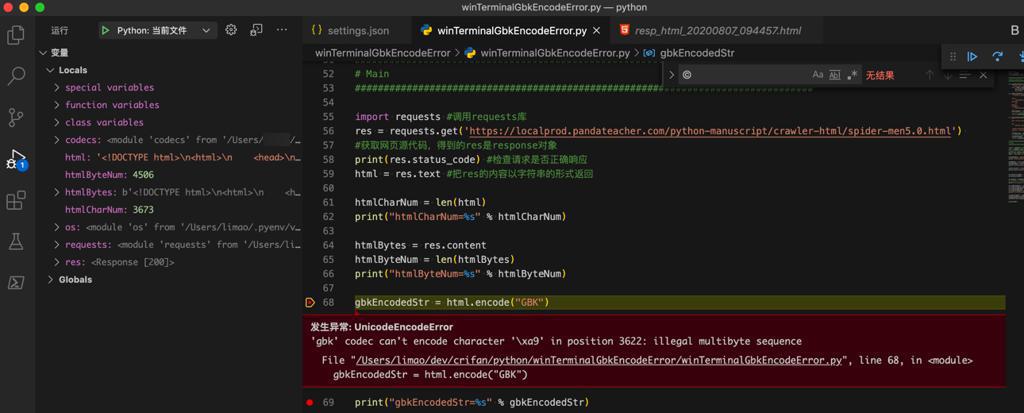
1 2 3 4 5 6 | htmlBytes = res.contenthtmlByteNum = len(htmlBytes)print("htmlByteNum=%s" % htmlByteNum)gbkEncodedStr = html.encode("GBK") |
的确会报错:
1 2 | 发生异常: UnicodeEncodeError'gbk' codec can't encode character '\xa9' in position 3622: illegal multibyte sequence |
基本上就明确了:
此处错误的字符串就是:©
不过,再去继续验证,去掉看看,是否就不会报错了
1 2 3 4 5 | gbkUnsupportedChar = '©'filteredHtml = html.replace(gbkUnsupportedChar, '')# gbkEncodedStr = html.encode("GBK")gbkEncodedStr = filteredHtml.encode("GBK")print("gbkEncodedStr=%s" % gbkEncodedStr) |
结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | htmlStrLen = len(html)print("before replace: htmlStrLen=%s" % htmlStrLen)gbkUnsupportedChar = '©'filteredHtml = html.replace(gbkUnsupportedChar, '')htmlStrLen = len(filteredHtml)print("after replace: htmlStrLen=%s" % htmlStrLen)# gbkEncodedStr = html.encode("GBK")gbkEncodedStr = filteredHtml.encode("GBK")print("gbkEncodedStr=%s" % gbkEncodedStr) |
结果:
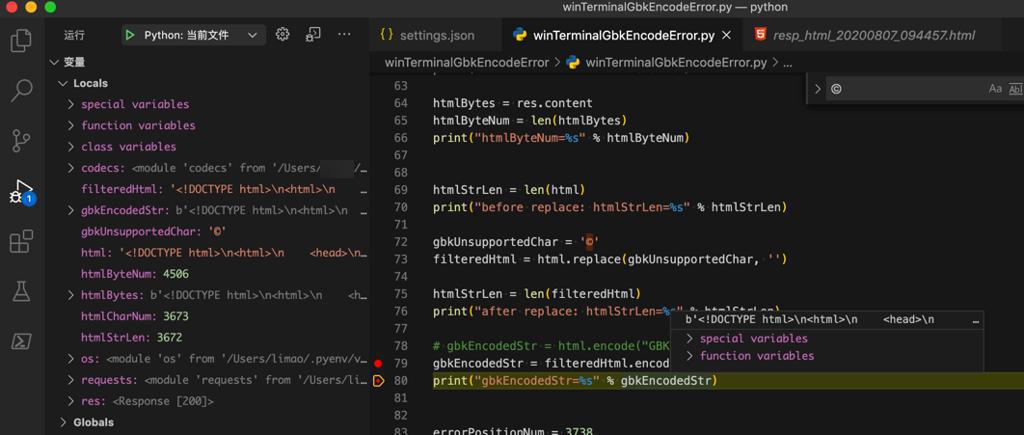
果然不会报错了。
-》说明之前推断是对的
-》GBK中,对于有些(稍微特殊一些的)字符,比如表示copyright的版权字符 © ,是不支持的
-》但是其他字符集范围更大的编码,比如GB18030,是支持的
-》当然最全的unicode字符集,即对应的常见编码,UTF-8,也同样支持。
-》所以才会出现此处的
Python3的unicode字符串中有 ©
去输出到Windows中的终端(cmd)中时,如果默认编码是GBK
就会出现,个别特殊字符无法编码而报错的情况
而如果把输出的终端的字符串编码格式,从默认的GBK改为GB18030,就可以正常输出字符串,而不会报错。
后记,再去用代码模拟之前错误:
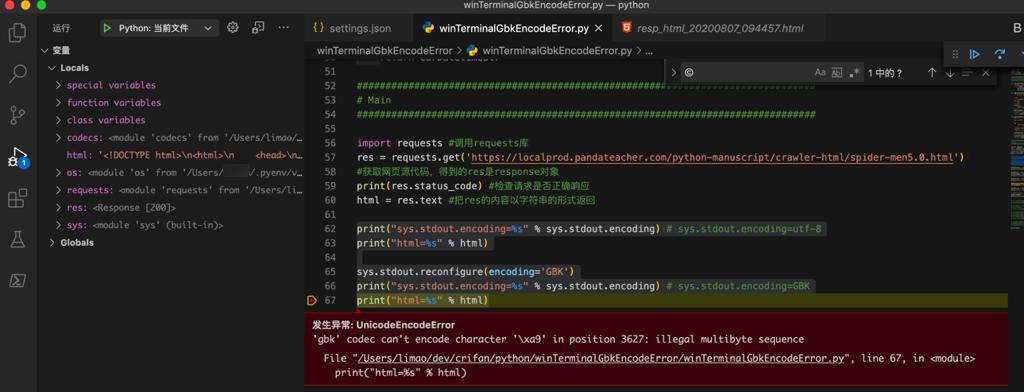
1 2 3 4 5 6 | print("sys.stdout.encoding=%s" % sys.stdout.encoding) # sys.stdout.encoding=utf-8print("html=%s" % html)sys.stdout.reconfigure(encoding='GBK')print("sys.stdout.encoding=%s" % sys.stdout.encoding) # sys.stdout.encoding=GBKprint("html=%s" % html) |
也是可以复现的:
1 2 | 发生异常: UnicodeEncodeError'gbk' codec can't encode character '\xa9' in position 3627: illegal multibyte sequence |
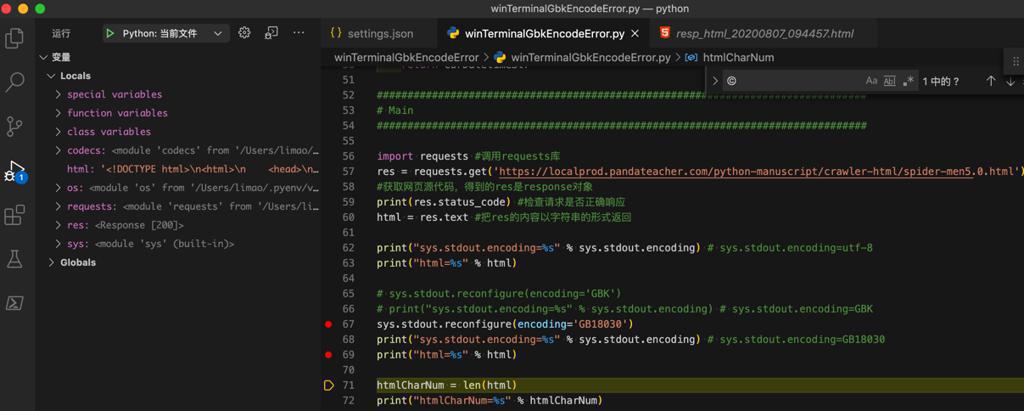
然后如果改为GB18030:
1 2 3 4 5 6 7 8 | print("sys.stdout.encoding=%s" % sys.stdout.encoding) # sys.stdout.encoding=utf-8print("html=%s" % html)# sys.stdout.reconfigure(encoding='GBK')# print("sys.stdout.encoding=%s" % sys.stdout.encoding) # sys.stdout.encoding=GBKsys.stdout.reconfigure(encoding='GB18030')print("sys.stdout.encoding=%s" % sys.stdout.encoding) # sys.stdout.encoding=GB18030print("html=%s" % html) |
就可以了:
也是符合预期的
不过此处,Mac中VSCode中输出是乱码:
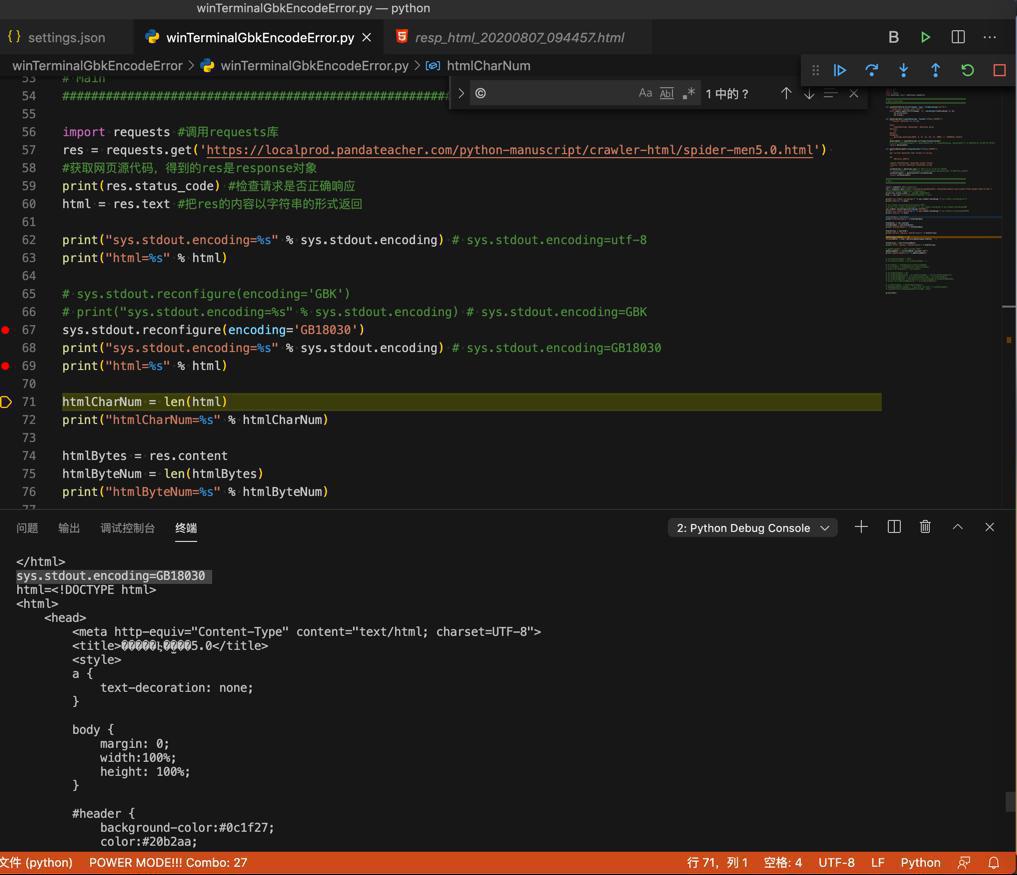
那是因为:
unicode的html被encode为GB18030的bytes,但是却在此处VSCode的编码为UTF-8的终端中显示,所以才是乱码的。也是符合预期的。
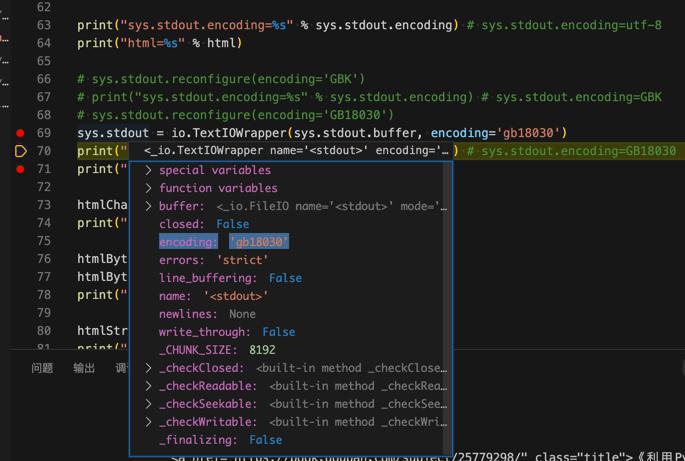
另外,也去试试:
1 | sys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') |
也是可以的:
【总结】
Windows中,用VSCode调试代码:
1 2 3 4 5 6 7 8 9 | import requests #调用requests库res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') #获取网页源代码,得到的res是response对象print(res.status_code) #检查请求是否正确响应html = res.text #把res的内容以字符串的形式返回print(html) |
报错:
1 | UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa9’ in position 3738: illegal multibyte sequence |
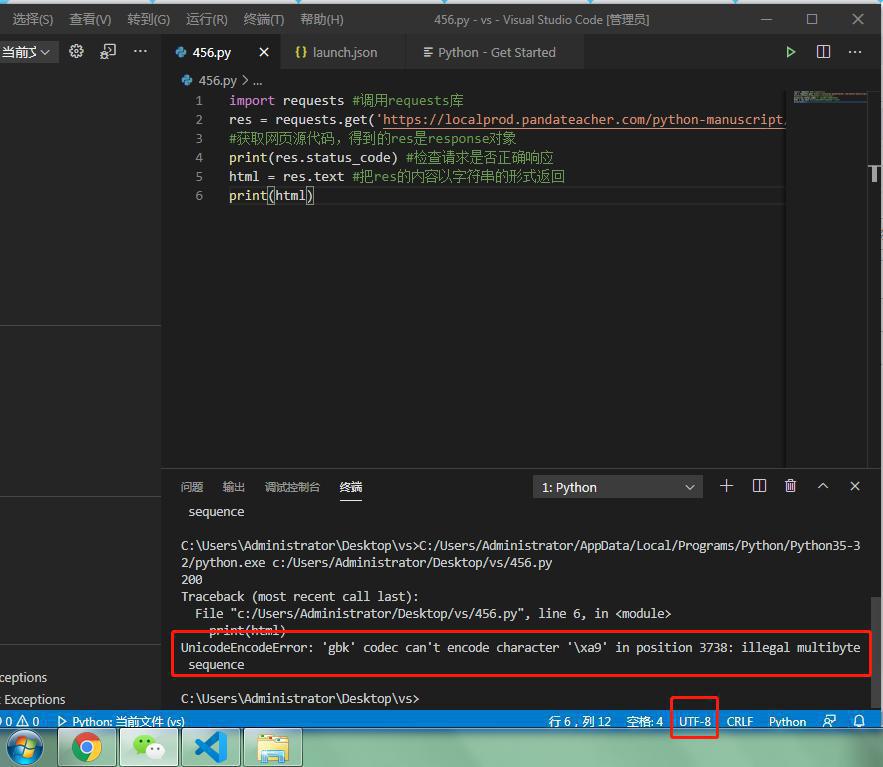
原因:
此处Windows中VSCode的终端的默认编码是GBK
而GBK不支持一些特殊字符,比如此处的表示copyright版权的字符:©
导致在把 此处unicode的str的html,去encode编码为GBK期间,而报错
1 | UnicodeEncodeError: ‘gbk’ codec can’t encode character ‘\xa9’ in position 3738: illegal multibyte sequence |
具体分析和解释就是:
- UnicodeEncodeError
- 表示是在unicode去encode发生的error
- 反推,之前的html已经是unicode类型了
- 对应着此处的Python3中的str了
- 注:可以从截图中 Python35-32看出是Python3.5版本
- gbk codec
- 表示当前输出的环境是GBK编码
- 当前环境指的是:Windows中VSCode中的(内置集成)终端
- 一般默认编码跟随者Windows中cmd的编码
- Windows中cmd的默认编码是GBK
- can’t encode character
- 无法给字符编码而报错
- \xa9’
- 经确认,\xa9,就是字符:©
- in position 3738
- 表示出错的位置
- 即此处GBK在尝试给unicode数据去编码时出错的位置
- illegal multibyte sequence
- 非法的多字节序列
- 总之就是编码方面报错时候的相关信息
- 或者说GBK属于 多字节序列 编码?
如何解决:
那就把 不支持(此处算稍微有一点)特殊字符\xa9的© 的编码GBK,换成其他支持©的编码
比如GB18030,UTF-8等
此处以更换为GB18030去介绍具体更换方式:
对于此处要输出的内容是系统的标准输出的终端的编码,则对应着:system的output的encoding
Python中相关的变量是:sys.stdout.encoding
想要更换系统标准输出终端的编码格式为GB18030,有多种写法:
方法1:
1 2 3 4 | import sysimport iosys.stdout = io.TextIOWrapper(sys.stdout.buffer, encoding='gb18030') |
方法2:
1 2 3 | import syssys.stdout.reconfigure(encoding='GB18030') |
注:
可以通过
1 | print("sys.stdout.encoding=%s" % sys.stdout.encoding) |
确认编码是否的确已改变。
以及其他一些相关变量:
1 2 3 4 5 6 7 | import sys, locale, osprint(sys.stdout.encoding)print(sys.stdout.isatty())print(locale.getpreferredencoding())print(sys.getfilesystemencoding())print(os.environ["PYTHONIOENCODING"]) |
供打印查看以辅助调试。
然后就可以正常输出此处,包含了特殊字符©的,完整的html字符串了。
相关现象:
(1)python自带的idle:正常
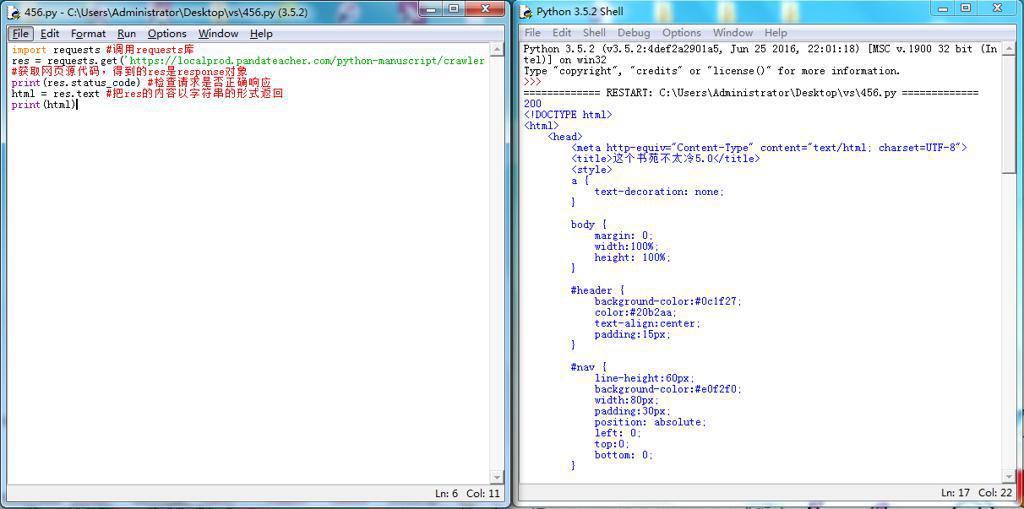
原因:
IDLE中输出的编码,应该是UTF-8
- 注:
- 推测:早期版本Python可能会报错
- Windows中早期Python版本的IDLE的默认编码,可能是 ANSI=Windows的cmd的GBK
- 如果是,就会报错
(2)pycharm:正常
原因:PyCharm中默认终端的编码,好像都是UTF-8,所以不会报错
(3)Windows的cmd:正常
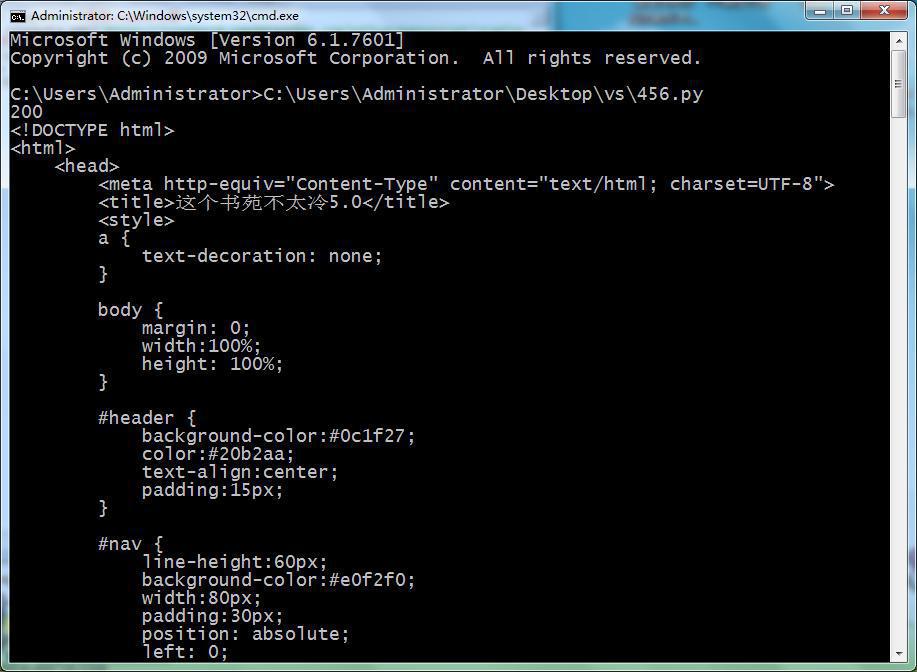
- 原因:怀疑是最新的win的cmd的编码已经变成了GB18030了?
- 所以才不会报错,正常输出的
- 根据此处截图,看起来像是,比较新的windows10的系统,且cmd也是很新的版本?
- 注:旧的windows的cmd的默认编码是Windows CP936=GBK
- 是会报错的
另外补充
想要去修改windows的cmd的默认编码
可以参考
去:
1 | chcp 65001 |
其中:code page 65001=UTF-8
【后记】
此处对于长远来说,感觉应该去修改Windows中VSCode中的终端的默认编码,为GB18030或UTF-8
具体如何修改,主要是去VSCode中找和终端有关参数
此处Mac中VSCode中找到一些,供参考和借鉴:
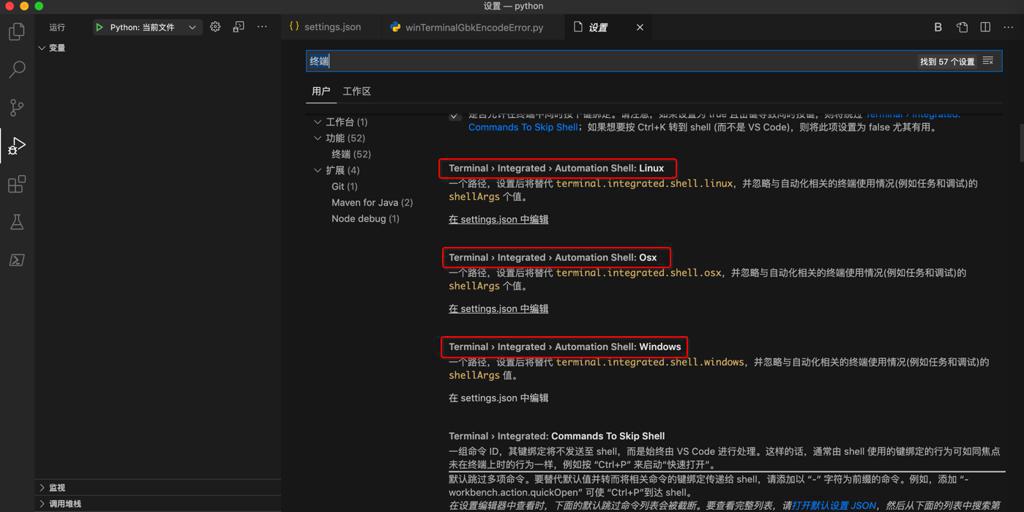
以及,其实最先要搞懂:
你的VSCode中的终端,是用哪种
- 内置的=integrated
- 默认配置就是内置的
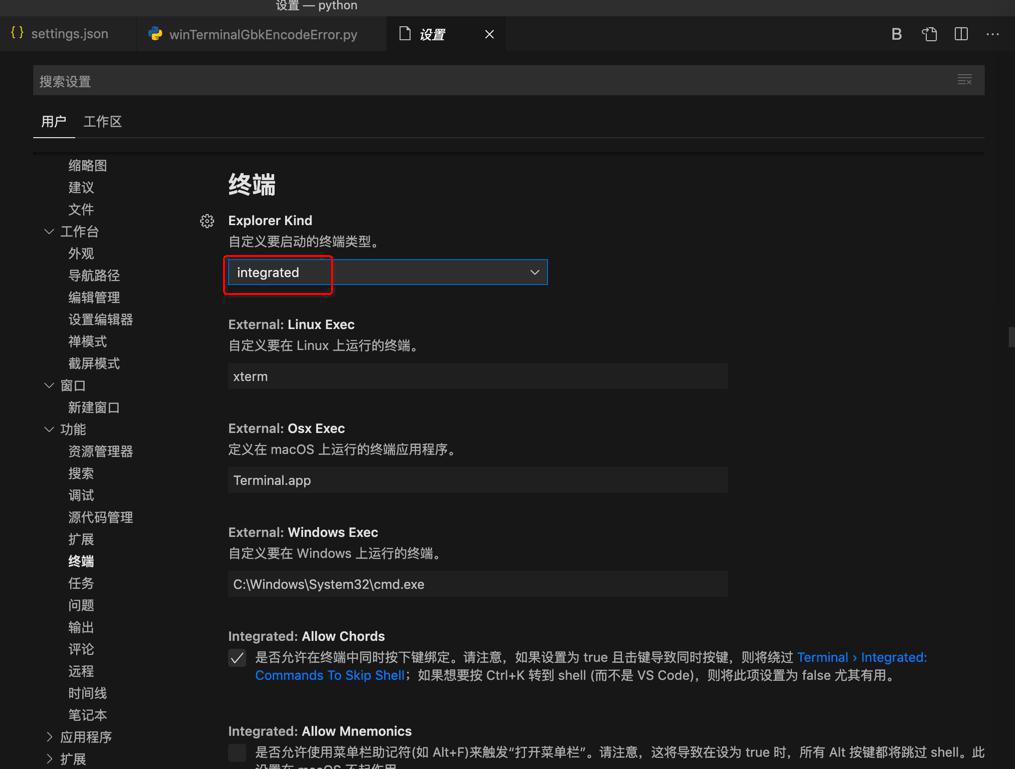
- VSCode自己内置实现的终端
- 注意:不是你的当前的系统的终端
- 外置的=external
- 可以根据自己需求,改为外置终端
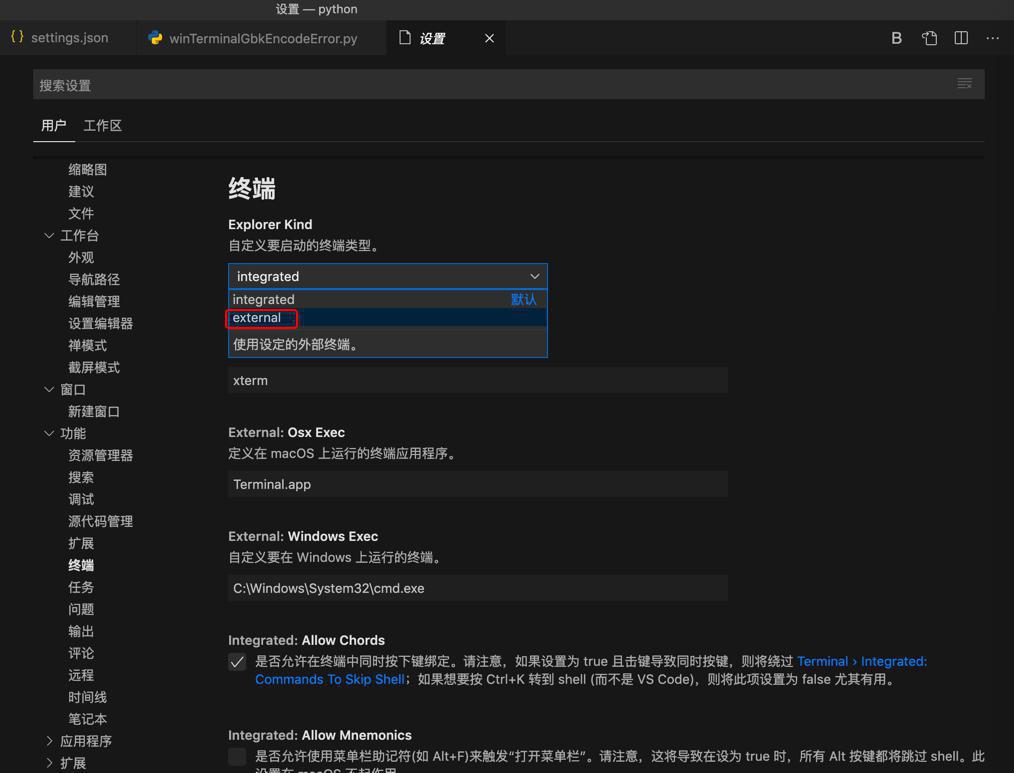
- 如果使用外部终端,也都有默认值,当然也可以更改为别的终端
- Windows系统
- cmd.exe
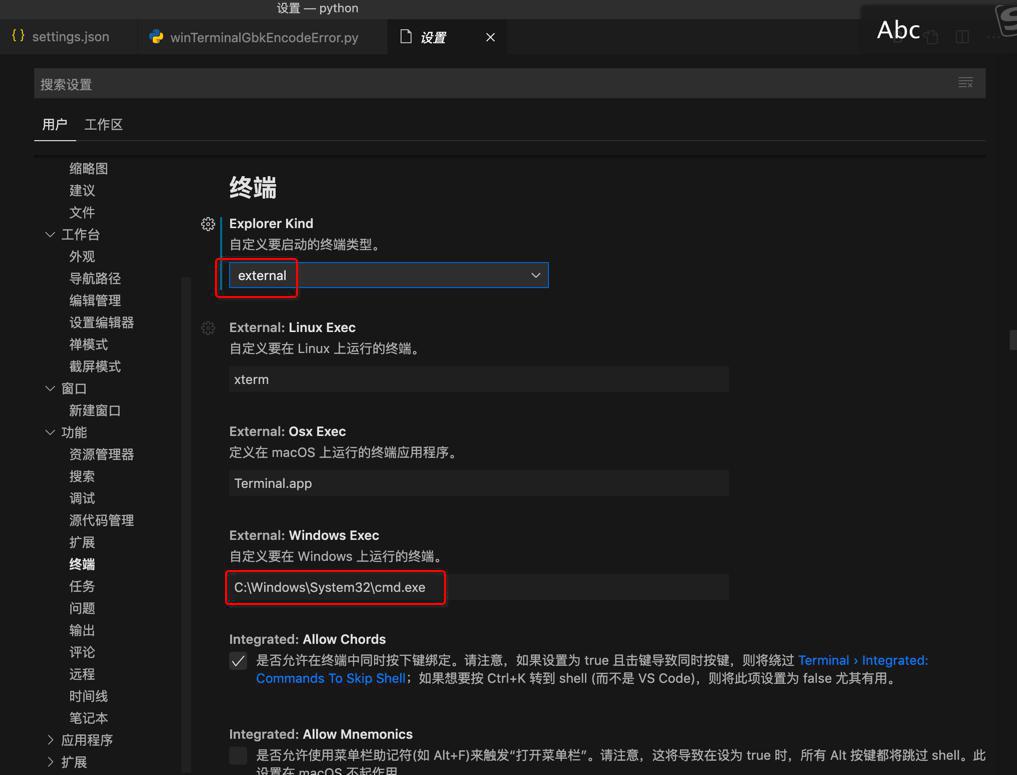
- Mac
- 默认是:Terminal.app
- 比如我安装了iTerm2:
- 理论上也可以改为:iTerm.app
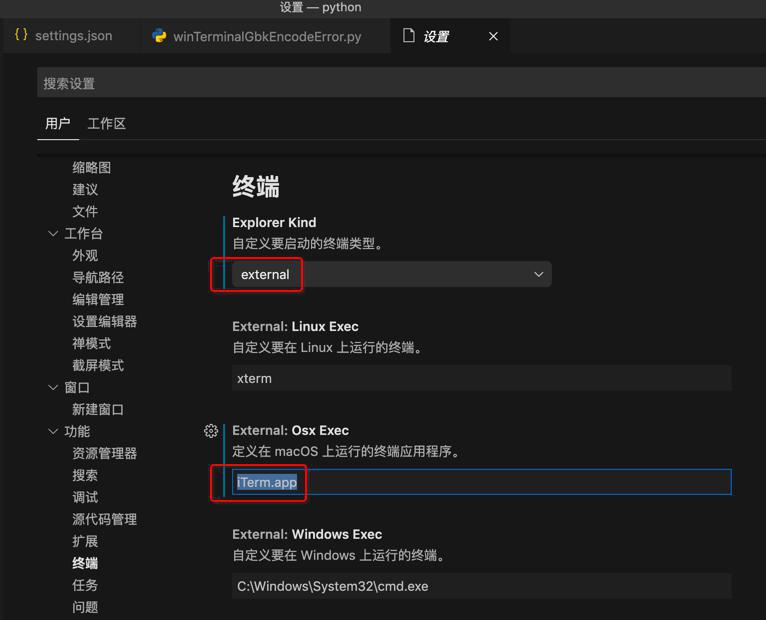
- Linux
- 默认是:xterm
找了些资料,供参考:
windows vscode terminal encoding
1 | terminal.integrated.shell.windows": "C:\Windows\system32\cmd.exe \K chcp 65001 |
或
1 | terminal.integrated.shellArgs.windows": ["chcp 65001"], |
或:
1 | "terminal.integrated.shellArgs.windows": ["/K", "chcp 65001"], |
结论:
此处也可以把之前的:
Windows中的VSCode的终端,默认是:内置的
改为:external外部的,比如Windows的cmd.exe
则理论上也可以避免上面的GBK编码错误的问题了。
转载请注明:在路上 » 【已解决】Windows中VSCode中输出字符串到终端报错:UnicodeEncodeError gbk codec can’t encode character \xa9