命名实体识别 NER 常见方法
自然语言处理之中文自动分词 | 白宁超的官网
https://bainingchao.github.io/2019/02/13/自然语言处理之中文自动分词/
【总结】
- 命名实体识别=NER=Named Entity Recognition
- 别名:
- 专名识别
- 专名辨识
- 含义:
- 一句话描述:从非结构化的文本中提取出实体
- 简单说:识别自然文本中的实体指称的边界和类别
- 主要包含
- 实体边界识别
- 识别文本中具有特定意义或者指代性强的实体
- 确定实体类别:再将其分类至事先划定好的类别
- 人名、地名、机构名或其他等
- 举例
- 在招聘信息中提取具体招聘公司、岗位和工作地点的信息
- 并将其分别归纳至公司、岗位和地点的类别下
- 从属于
- 信息提取(Information Extraction)
- 一个子任务
- 实体类别
- 总体分类
- 3大类
- 实体类
- 时间类
- 数字类
- 7小类:命名实体
- 人名
- 地名
- 机构名
- 时间
- 日期
- 货币
- 百分比
- 特殊
- 不同业务需求-》不同类别的实体
- 产品名称、型号、价格等
- 如书名、歌曲名、期刊名等
- 处理过程
- 将整句拆解为词语
- 对每个词语进行此行标注
- 根据习得的规则对词语进行判别
- 关键点:对未知实体的识别
- 主要思想:根据现有实例的特征总结识别和分类规则
- 侧重点:高召回率
- 注:
- 在信息检索领域,高准确率更重要
- 识别结果
- 一般来说
- 识别出人名、地名、组织机构名、日期时间即可
- 部分系统输出专有名词
- 比如缩写、会议名、产品名等
- 货币、百分比等:用正则处理
- 举例

- 评价标准
- 实体的边界是否正确
- 实体的类型是否标注正确
- 可能的错误
- 文本实体词正确,类型错误
- 文本边界错误,主要实体词和词类正确
- 所属领域:NLP
- NER属于NLP领域中的研究热点
- 常被用于、涉及到
- 信息抽取
- 关系抽取
- 事件抽取
- 信息检索
- 机器翻译
- 问答系统
- 知识图谱
- 背景和特点
- 命名实体数量不断增加
- 通常不可能在词典中穷尽列出
- 其构成方法具有各自的一些规律性
- -》把对这些词的识别从词汇形态处理(如汉语切分)任务中独立处理,称为命名实体识别
- 中文命名实体识别相较于英文命名实体识别来说更加困难
- 英文中每个词很自然的被空格分隔开来
- 而中文中词与词之间是没有明显的边界的
- 汉语分词和命名实体识别互相影响
- 现代汉语文本,尤其是网络汉语文本,常出现中英文交替使用
- 现状
- 部分认为已很好的解决了NER问题
- 有些认为还没很好的解决NER问题
- 目前的NER
- 只是有限的场景效果还算不错
- 文本类型
- 主要是新闻语料中
- 和实体类别
- 主要是人名、地名、组织机构名
- 通用的识别多种类和场景的
- 性能很差
- 常见方法分类
- 发展历史

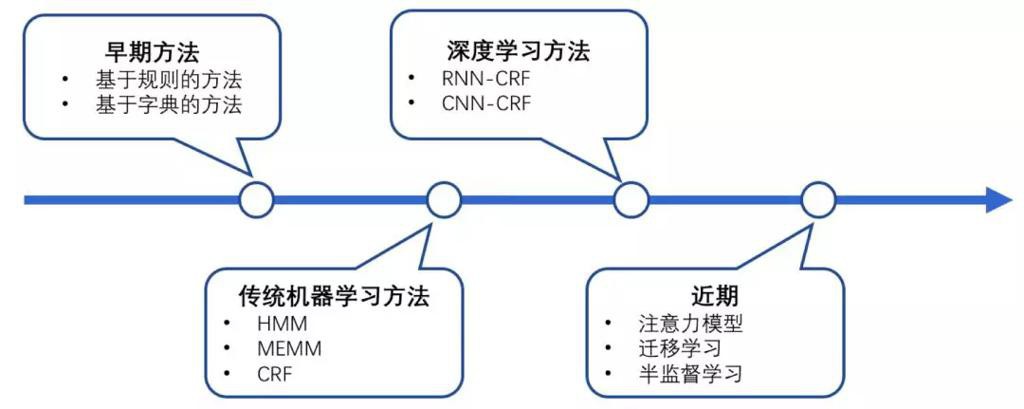
- 不同阶段
- 包括
- 阶段 1:早期的方法,如:基于规则的方法、基于字典的方法
- 阶段 2:传统机器学习,如:HMM、MEMM、CRF
- 阶段 3:深度学习的方法,如:RNN – CRF、CNN – CRF
- 阶段 4:近期新出现的一些方法,如:注意力模型、迁移学习、半监督学习的方法
- 分类概述
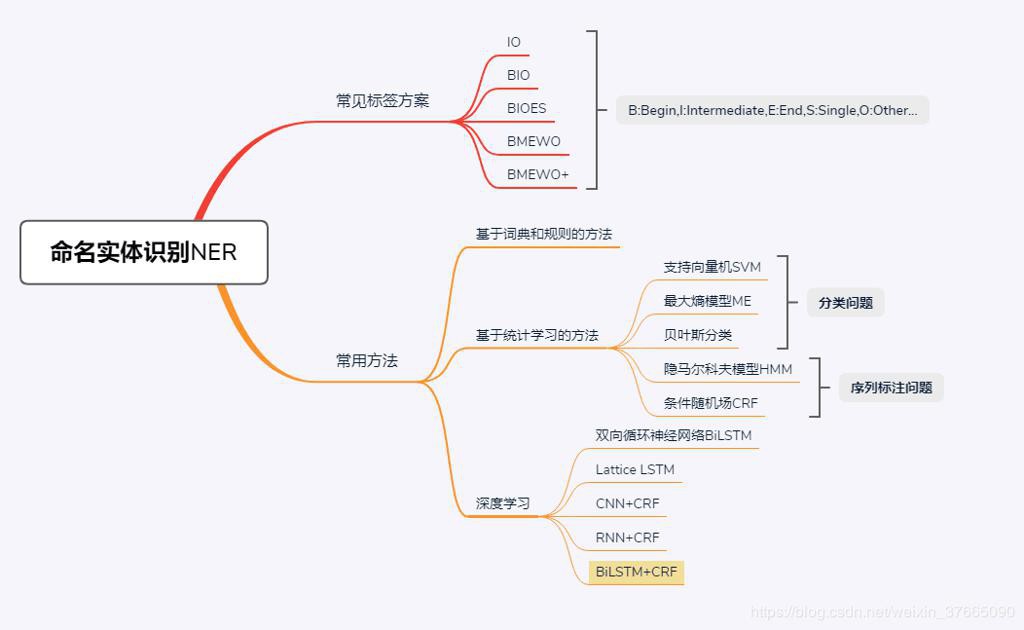
- 早期:
- 基于规则和词典的方法
- 缺点
- 成本高昂
- 现在:
- 基于统计的方法
- 核心:从训练语料中挖掘出特征
- =需要语料库来进行训练
- 特征分类
- 单词特征
- 上下文特征
- 词典及词性特征
- 停用词特征
- 核心词特征
- 语义特征
- 特点:
- 对特征选取的要求高
- 从文本中选择对该项任务有影响的各种特征
- 并将这些特征加入到特征向量中
- 语料库的依赖也比较大
- 现状:大规模通用语料库比较少
- 常用方法
- HMM
- CRF
- 神经网络
- 二者混合的方法
- 思路
- 统计学习方法之间或内部层叠融合
- 规则、词典和机器学习方法之间的融合
- 核心:融合方法技术
- 将各类模型、算法结合起来
- 将前一级模型的结果作为下一级的训练数据
- 并用这些训练数据对模型进行训练,得到下一级模型
- 依赖于:相关分类技术
- 分类技术
- Voting
- XVoting
- GradingVa
- l Grading
- 举例
- Bi-LSTM+CRF
- 具体分类解释
- 早期:基于规则或字典
- 前提:
- 人工(语言学专家手工)构造规则模板
- 建立知识库和词典
- 主要手段:模式和字符串相匹配
- 选用特征
- 包含
- 统计信息
- 标点符号
- 关键字
- 指示词
- 方向词
- 位置词(如尾字)
- 中心词
- 缺点
- 依赖于具体语言、领域、文本风格
- 编制过程耗时
- 特别容易产生错误
- 难以涵盖所有的语言现象
- =系统可移植性不好
- 不同的系统需要语言学专家重新书写规则
- 代价太大
- 常见方法
- 正向最大匹配法
- 逆向最大匹配法
- 双向扫描匹配法
- 逐词遍历法
- 之后:基于统计基于大规模的语料库的统计
- 在NLP中取得不错的效果
- 主要方法
- 基于字符串匹配的分词方法
- 基于理解的分词方法
- 基于统计的分词方法
- 继续演化:用机器学习的方法
- 核心:基于统计
- 分类
- supervised=有监督的学习方法
- 前提:大规模的已标注语料
- 方法:对模型进行参数训练
- 读取注释语料库,记忆实例并进行学习
- 根据这些例子的特征生成针对某一种实例的识别规则
- 常用模型或方法
- 对比:
- 最大熵和支持向量机 正确率 > 隐马尔可夫模型
- 隐马尔可夫模型 训练和识别的速度 > 最大熵和支持向量机
- 包括:
- 分类问题
- SVM=Support VectorMachine=支持向量机
- ME=Maximum Entropy=最大熵模型
- 贝叶斯分类
- 序列标注问题
- HMM=Hidden Markov Mode=隐马尔可夫模型
- CRF=Conditional Random Fields=条件随机场
- 其他
- 决策树
- 语言模型
- semi-supervised=半监督的学习方法
- 前提:已标注的小数据集(种子数据)
- 方法:自举学习
- unsupervised=无监督的学习方法
- 前提:词汇资源
- 举例
- WordNet
- 方法:进行上下文聚类
- 混合方法
- 几种模型相结合
- 利用统计方法和人工总结的知识库
- 现在:深度学习
- 核心思路:把命名实体识别当做序列标注任务来做
- 经典方法:
- 基础方法
- LSTM=LongShort Term Memory网络
- BiLSTM=双向循环神经网络
- 组合方法
- BiLSTM+CRF
- LSTM+CRF
- DL-CRF
- Lattice LSTM
- CNN+CRF
- RNN+CRF
- IDCNN-CRF
- NER的主流模型:
- 神经网络与CRF模型相结合的CNN
- 基于神经网络结构的NER方法
- 继承了深度学习方法的优点
- 无需大量人工特征
- RNN-CRF
- RNN有天然的序列结构
- RNN-CRF使用更为广泛
- 常见工具和库
- Stanford NER
- 属于:Stanford NLP
- 原理:基于条件随机场
- 系统参数:基于CoNLL、MUC-6、MUC-7和ACE命名实体语料训练
- MALLET
- http://mallet.cs.umass.edu/
- 原理:序列标注
- HanLP:NLP工具包
- 一系列模型与算法组成
- 目标:普及自然语言处理在生产环境中的应用
- NLTK
- SpaCy
- 工业级的自然语言处理工具
- 缺点:不支持中文
- Crfsuite:可以载入自己的数据集去训练CRF实体识别模型
【NER的相关数据集】
数据集 | 简要说明 | 访问地址 |
电子病例测评 | CCKS2017开放的中文的电子病例测评相关的数据 | |
音乐领域 | CCKS2018开放的音乐领域的实体识别任务 | CCKS |
位置、组织、人… | 这是来自GMB语料库的摘录,用于训练分类器以预测命名实体,例如姓名,位置等。 | |
口语 | NLPCC2018开放的任务型对话系统中的口语理解评测 | |
人名、地名、机构、专有名词 | 一家公司提供的数据集,包含人名、地名、机构名、专有名词 |
【实体命名识别NER常见算法详细对比】
- ME=Maximum Entropy=最大熵模型
- 优点:
- 结构紧凑
- 较好的通用性
- 缺点:
- 训练时间复杂性非常高
- 有时甚至难以承受
- 开销比较大
- 需要明确的归一化计算
- HMM=Hidden Markov Mode=隐马尔可夫模型
- 核心:Viterbi算法
- 求解命名实体类别序列的效率较高
- 应用
- 在自然语言处理领域应用比较广泛
- 如汉语分词,词性标注,语音识别
- 适用场景
- 实时性高
- 数据量大的短文本命名实体识别
- 信息检索
- CRF=Conditional Random Fields=条件随机场
- 效果:最成功
- 目前最主流
- 核心:标注框架
- 原理
- 一种线性链条件随机场
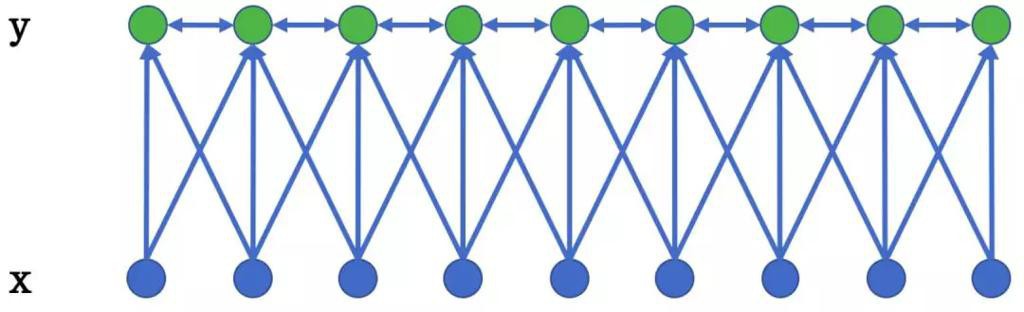
- 目标函数
- 不仅考虑输入的状态特征函数
- 还包含了标签转移特征函数
- 模型的训练
- 特点
- 非传统的pipeline
- 是一个端到端的过程
- 不依赖于特征工程
- 包含
- 将token从离散one-hot表示映射到低维空间中成为稠密的embedding
- 随后将句子的embedding序列输入到RNN中
- 用神经网络自动提取特征
- Softmax来预测每个token的标签
- 特点:
- 特征灵活
- 全局最优
- 为一个位置进行标注的过程中可以利用丰富的内部及上下文特征信息
- 缺点:
- 收敛速度慢
- 训练时间长
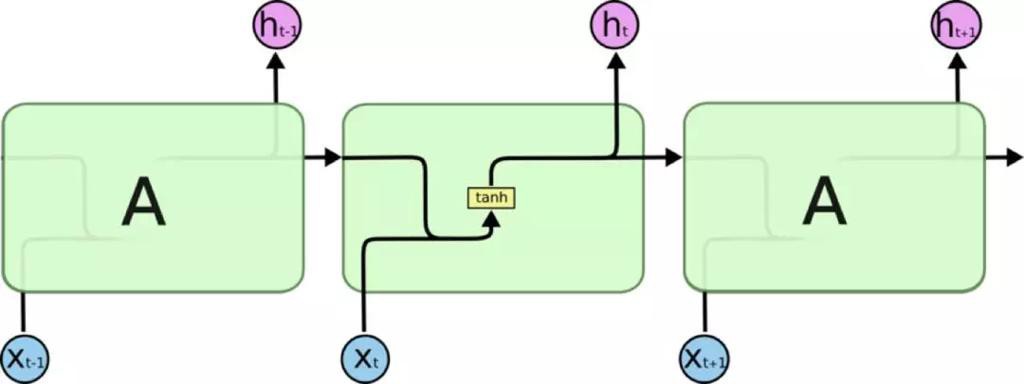
- LSTM=LongShort Term Memory网络
- RNN的一种特殊类型
- 可以学习长距离依赖信息
- BiLSTM=双向循环神经网络
- 对比
- 传统RNN结构
- LSTM结构
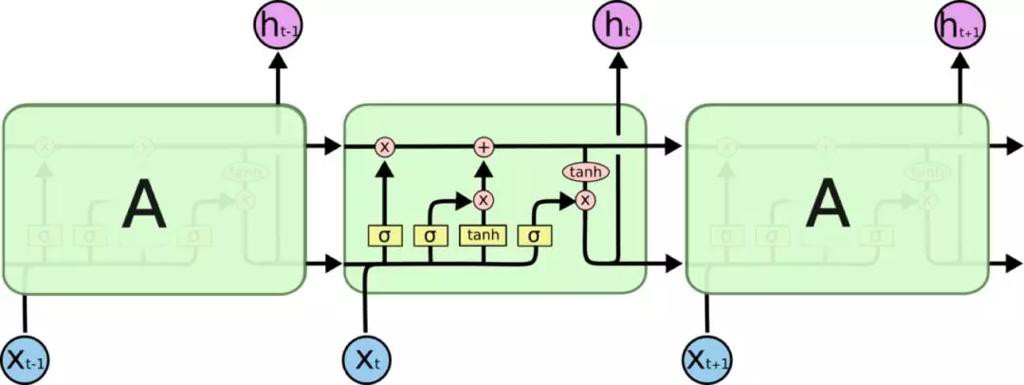
- LSTM各个门控结构
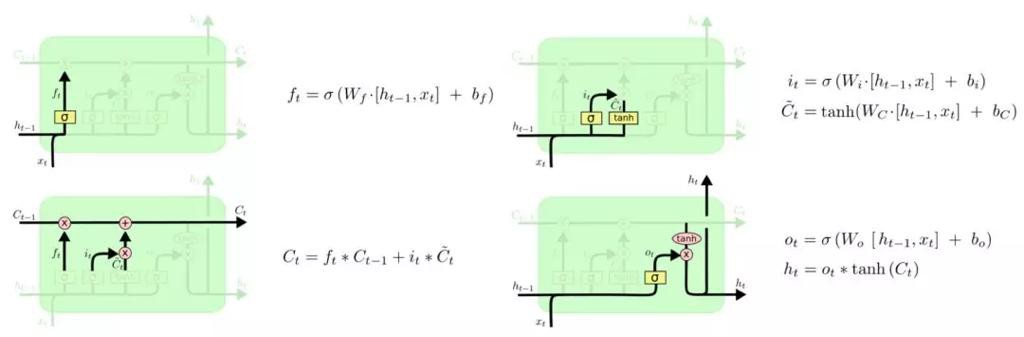
- 三个门结构
- 输入门:加入部分当前输入信息
- 遗忘门:选择性地遗忘部分历史信息
- 输出门:最终整合到当前状态并产生输出状态
- 构成
- Embedding层
- 组成:词向量,字向量以及一些额外特征
- 双向LSTM层
- CRF层
- 结构示意图
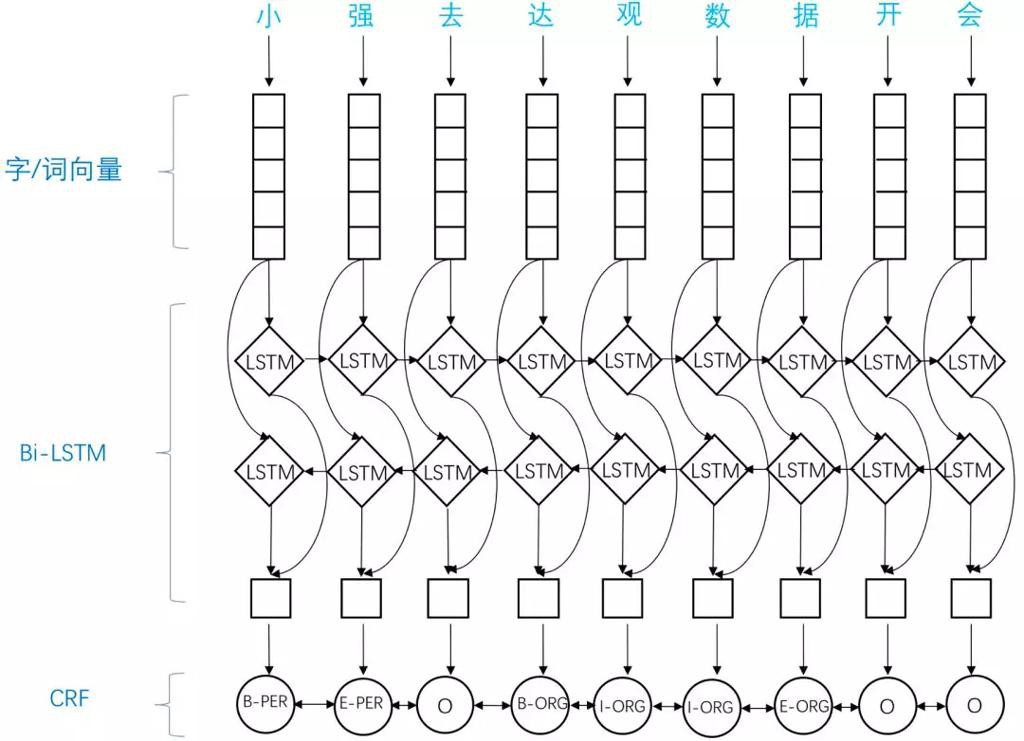
- 特点
- 继承了深度学习方法的优势
- 无需特征工程
- 使用词向量以及字符向量就可以达到很好的效果
- 如果有高质量的词典特征,能够进一步获得提高
- 效果
- 达到或者超过了基于丰富特征的CRF模型
- 成为目前基于深度学习的NER方法中的最主流模型
- IDCNN-CRF
- 背景
- 对于序列标注
- 普通CNN有一个不足
- 卷积之后,末层神经元可能只是得到了原始输入数据中一小块的信息
- 而整个输入句子中每个字都有可能对当前位置的标注产生影响
- 即所谓的长距离依赖问题
- 为了覆盖到全部的输入信息
- 加入更多的卷积层
- 导致
- 层数越来越深
- 参数越来越多
- 为了防止过拟合
- 加入更多的Dropout之类的正则化
- 带来更多的超参数
- 整个模型变得庞大且难以训练
- 结论
- 因为CNN这样的劣势,对于大部分序列标注问题
- 选择biLSTM之类的网络结构
- 尽可能利用网络的记忆力记住全句的信息来对当前字做标注
- 带来另外一个问题
- biLSTM本质是一个序列模型
- 对GPU并行计算的利用上不如CNN那么强大
- 问题
- 如何能够像CNN那样给GPU提供一个火力全开的战场
- 而又像LSTM这样用简单的结构记住尽可能多的输入信息呢?
- 用:dilated CNN=膨胀的 CNN
- 原理
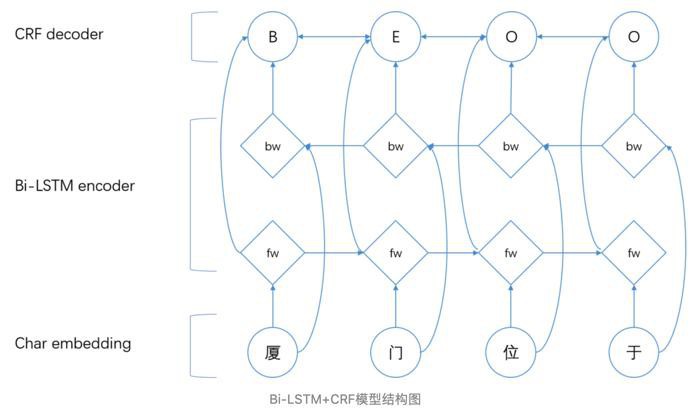
- dilated CNN=膨胀的 CNN
- 思路和原理
- 为这个filter增加了一个dilation width,作用在输入矩阵的时候,会skip所有dilation width中间的输入数据
- 而filter本身的大小保持不变,这样filter获取到了更广阔的输入矩阵上的数据
- 看上去就像是“膨胀”了一般
- 具体使用时,dilated width会随着层数的增加而指数增加
- 这样随着层数的增加,参数数量是线性增加的
- 而receptive field却是指数增加的,可以很快覆盖到全部的输入数据
- idcnn示意图
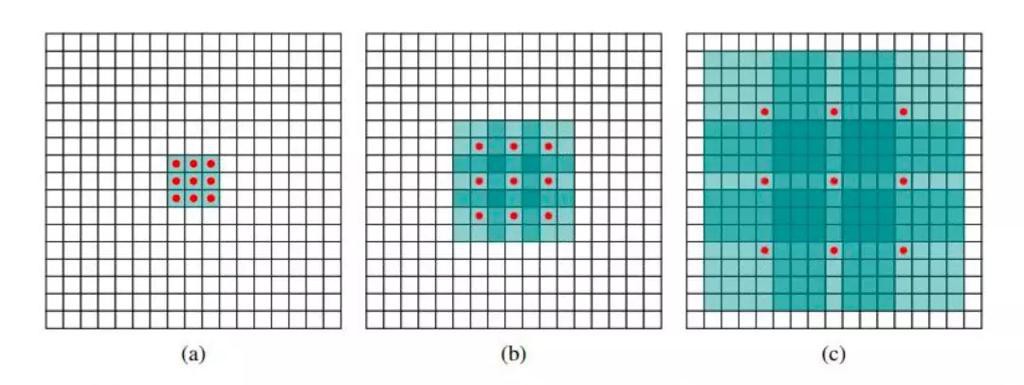
- 一个最大膨胀步长为4的idcnn块
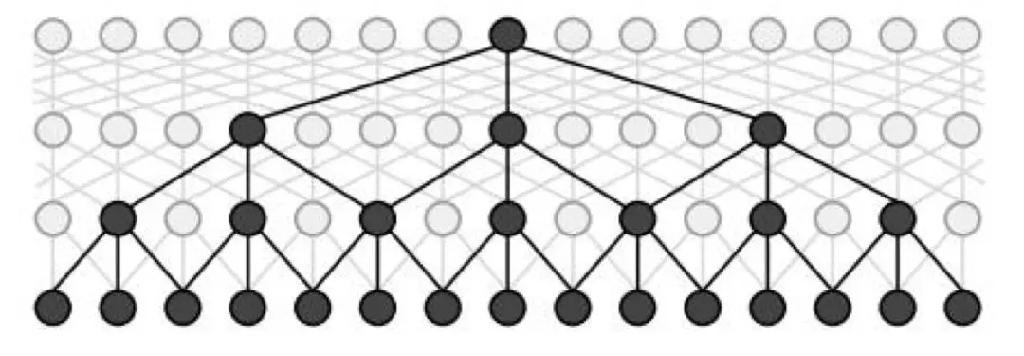
- 其他对比
- LSTM=单向LSTM vs Bi-LSTM=双向
- 双向LSTM的效果要比单向的LSTM效果好
- 双向LSTM将序列正向和逆向均进行了遍历
- 相较于单向LSTM可以提取到更多的特征
转载请注明:在路上 » 【整理】命名实体识别 NER 常见方法