背景:
做NER命名实体识别时,用传统的字典或规则实现,有种方式是用TrieTree,Trie树
对此
同事表示很喜欢这个数据结构=算法,一般面试都会问到
自己不熟悉,去研究看看
TrieTree 算法 数据结构
trie tree 算法
算法笔记之trie树
命名实体识别 trie tree
ner trie tree
【总结】
- Trie Tree=Tire树
- 别名:
- 字典树
- 前缀树=Prefix Tree
- 单词查找树
- 键树
- 是什么:
- 一种数据结构~=算法
- 一种多叉树
- 一种查询数
- key往往是字符串
- 与之对比:
- 二进制查找树 binary search tree
- 一种有序树
- 用途
- 保存关联数组
- 举例
- 关键字集合
- {“a”, “to”, “tea”, “ted”, “ten”, “i”, “in”, “inn”}
- -》
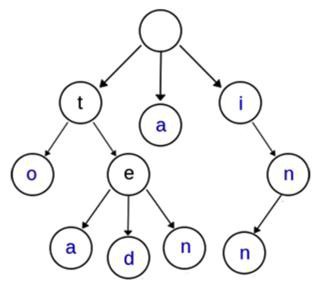
- 基本性质
- 根节点不包含字符,除根节点外的每一个子节点都包含一个字符
- 从根节点到某一个节点,路径上经过的字符连接起来,为该节点对应的字符串
- 每个节点的所有子节点包含的字符互不相同
- 实际实现
- 在节点结构中设置一个标志,用来标记该结点处是否构成一个单词(关键字)
- 特点
- 关键字一般都是字符串
- 把每个关键字保存在一条路径上
- 而不是一个结点中
- 两个有公共前缀的关键字,在Trie树中前缀部分的路径相同
- 所以Trie树又叫做前缀树
- 核心思想
- 空间换时间
- 利用字符串的公共前缀来减少无谓的字符串比较
- 以达到提高查询效率的目的
- 用途:一般都是和Hash表相比较,用来替换Hash表
- -》优缺点
- 优点
- 插入和查询的效率很高,都为O(m)
- Trie树中不同的关键字不会产生冲突
- Trie树只有在允许一个关键字关联多个值的情况下才有类似hash碰撞发生
- Trie树不用求 hash 值,对短字符串有更快的速度
- 通常,求hash值也是需要遍历字符串的
- Trie树可以对关键字按字典序排序
- 缺点
- 当 hash 函数很好时,Trie树的查找效率会低于哈希搜索
- 空间消耗比较大
- 压缩空间
- radix tree基数树
- 结构举例
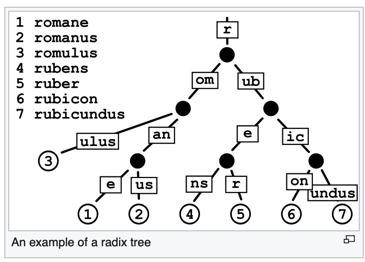
- 别名
- 压缩前缀树compact prefix tree
- 基数Trie树 radix trie
- -》应用领域
- 字符串检索
- 思路
- 从根节点开始一个一个字符进行比较
- 如果沿路比较,发现不同的字符,则表示该字符串在集合中不存在
- 如果所有的字符全部比较完并且全部相同,还需判断最后一个节点的标志位(标记该节点是否代表一个关键字)
- 词频统计
- 常被搜索引擎系统用于文本词频统计
- 字符串排序
- 对大量字符串按字典序进行排序
- 思路
- 遍历一次所有关键字,将它们全部插入trie树,树的每个结点的所有儿子很显然地按照字母表排序
- 然后先序遍历输出Trie树中所有关键字即可
- 前缀匹配
- 举例
- 搜索提示
- 如当输入一个网址,可以自动搜索出可能的选择。当没有完全匹配的搜索结果,可以返回前缀最相似的可能
转载请注明:在路上 » 【整理】NER TrieTree Trie Tree Trie树