折腾:
期间,已经可以用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 | #!/usr/bin/env python# -*- encoding: utf-8 -*-# Created on 2019-03-27 15:35:20# Project: XiaohuashengAppfrom pyspider.libs.base_handler import *import osimport jsonimport codecsimport base64import gzipimport copyimport time# import datetimefrom datetime import datetime, timedeltafrom hashlib import md5####################################################################### Const######################################################################gServerPort = "http://www.xiaohuasheng.cn:83"SelfReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/selfReadingBookQuery2"ParentChildReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2"# ViewEnglishSeries2UrlPrefix = "http://www.xiaohuasheng.cn:83/Reading.svc/viewEnglishSeries2"RESPONSE_OK = "1001"####################################################################### Config & Settings######################################################################OutputFolder = "/Users/crifan/dev/dev_root/company/xxx/projects/crawler_projects/crawler_xiaohuasheng_app/output"DefaultPageSize = 10gUserAgentNoxAndroid = "Mozilla/5.0 (Linux; U; Android 4.4.2; zh-cn; A0001 Build/KOT49H) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1"gUserId = "1134723"gAuthorization = """NSTp9~)NwSfrXp@\\"""gUserToken = “40d2267f-x-x-x-xxx"gSecretKey = “AyGt7ohMR!yyy#N"gHeaders = { "Host": "www.xiaohuasheng.cn:83", "User-Agent": gUserAgentNoxAndroid, "Content-Type": "application/json", "userId": gUserId, "Authorization": gAuthorization, # "timestamp": gTimestamp, # "signature": gSignature, "cookie": "ASP.NET_SessionId=dxf3obxgn5t4w350xp3icgy0", # "Cookie2": "$Version=1", "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "cache-control": "no-cache", "Connection": "keep-alive", # "content-length": "202",}####################################################################### Common Util Functions######################################################################def getCurTimestamp(withMilliseconds=False): """ get current time's timestamp (default)not milliseconds -> 10 digits: 1351670162 with milliseconds -> 13 digits: 1531464292921 """ curDatetime = datetime.now() return datetimeToTimestamp(curDatetime, withMilliseconds)def datetimeToTimestamp(datetimeVal, withMilliseconds=False) : """ convert datetime value to timestamp eg: "2006-06-01 00:00:00.123" -> 1149091200 if with milliseconds -> 1149091200123 :param datetimeVal: :return: """ timetupleValue = datetimeVal.timetuple() timestampFloat = time.mktime(timetupleValue) # 1531468736.0 -> 10 digits timestamp10DigitInt = int(timestampFloat) # 1531468736 timestampInt = timestamp10DigitInt if withMilliseconds: microsecondInt = datetimeVal.microsecond # 817762 microsecondFloat = float(microsecondInt)/float(1000000) # 0.817762 timestampFloat = timestampFloat + microsecondFloat # 1531468736.817762 timestampFloat = timestampFloat * 1000 # 1531468736817.7621 -> 13 digits timestamp13DigitInt = int(timestampFloat) # 1531468736817 timestampInt = timestamp13DigitInt return timestampIntdef extractSuffix(fileNameOrUrl): """ extract file suffix from name or url eg: <div style="width: 640px;" class="wp-video"><!--[if lt IE 9]><script>document.createElement('video');</script><![endif]--><span class="mejs-offscreen">视频播放器</span><div id="mep_0" class="mejs-container mejs-container-keyboard-inactive wp-video-shortcode mejs-video" tabindex="0" role="application" aria-label="视频播放器" style="width: 640px; height: 360px; min-width: 16006px;"><div class="mejs-inner"><div class="mejs-mediaelement"><mediaelementwrapper id="video-75569-1"><video class="wp-video-shortcode" id="video-75569-1_html5" width="640" height="360" preload="metadata" src="https://cdn2.xxx.cn/2018-09-10/15365514898246.mp4?_=1" style="width: 640px; height: 360px;"><source type="video/mp4" src="https://cdn2.xxx.cn/2018-09-10/15365514898246.mp4?_=1"><a href="https://cdn2.xxx.cn/2018-09-10/15365514898246.mp4" data-original-title="" title="">https://cdn2.xxx.cn/2018-09-10/15365514898246.mp4</a></video></mediaelementwrapper></div><div class="mejs-layers"><div class="mejs-poster mejs-layer" style="display: none; width: 100%; height: 100%;"></div><div class="mejs-overlay mejs-layer" style="display: none; width: 100%; height: 100%;"><div class="mejs-overlay-loading"><span class="mejs-overlay-loading-bg-img"></span></div></div><div class="mejs-overlay mejs-layer" style="display: none; width: 100%; height: 100%;"><div class="mejs-overlay-error"></div></div><div class="mejs-overlay mejs-layer mejs-overlay-play" style="width: 100%; height: 100%;"><div class="mejs-overlay-button" role="button" tabindex="0" aria-label="播放" aria-pressed="false"></div></div></div><div class="mejs-controls"><div class="mejs-button mejs-playpause-button mejs-play"><button type="button" aria-controls="mep_0" title="播放" aria-label="播放" tabindex="0"></button></div><div class="mejs-time mejs-currenttime-container" role="timer" aria-live="off"><span class="mejs-currenttime">00:00</span></div><div class="mejs-time-rail"><span class="mejs-time-total mejs-time-slider" role="slider" tabindex="0" aria-label="时间轴" aria-valuemin="0" aria-valuemax="0" aria-valuenow="0" aria-valuetext="00:00"><span class="mejs-time-buffering" style="display: none;"></span><span class="mejs-time-loaded"></span><span class="mejs-time-current"></span><span class="mejs-time-hovered no-hover"></span><span class="mejs-time-handle"><span class="mejs-time-handle-content"></span></span><span class="mejs-time-float"><span class="mejs-time-float-current">00:00</span><span class="mejs-time-float-corner"></span></span></span></div><div class="mejs-time mejs-duration-container"><span class="mejs-duration">00:00</span></div><div class="mejs-button mejs-volume-button mejs-mute"><button type="button" aria-controls="mep_0" title="静音" aria-label="静音" tabindex="0"></button><a href="javascript:void(0);" class="mejs-volume-slider" aria-label="音量" aria-valuemin="0" aria-valuemax="100" role="slider" aria-orientation="vertical"><span class="mejs-offscreen">使用上/下箭头键来增高或降低音量。</span><div class="mejs-volume-total"><div class="mejs-volume-current" style="bottom: 0px; height: 100%;"></div><div class="mejs-volume-handle" style="bottom: 100%; margin-bottom: 0px;"></div></div></a></div><div class="mejs-button mejs-fullscreen-button"><button type="button" aria-controls="mep_0" title="全屏" aria-label="全屏" tabindex="0"></button></div></div></div></div></div> -> mp4 15365514894833.srt -> srt """ return fileNameOrUrl.split('.')[-1]def createFolder(folderFullPath): """ create folder, even if already existed Note: for Python 3.2+ """ os.makedirs(folderFullPath, exist_ok=True) print("Created folder: %s" % folderFullPath)def saveDataToFile(fullFilename, binaryData): """save binary data info file""" with open(fullFilename, 'wb') as fp: fp.write(binaryData) fp.close() print("Complete save file %s" % fullFilename)def saveJsonToFile(fullFilename, jsonValue): """save json dict into file""" with codecs.open(fullFilename, 'w', encoding="utf-8") as jsonFp: json.dump(jsonValue, jsonFp, indent=2, ensure_ascii=False) print("Complete save json %s" % fullFilename)def loadJsonFromFile(fullFilename): """load and parse json dict from file""" with codecs.open(fullFilename, 'r', encoding="utf-8") as jsonFp: jsonDict = json.load(jsonFp) print("Complete load json from %s" % fullFilename) return jsonDict####################################################################### Main######################################################################class Handler(BaseHandler): crawl_config = { } def on_start(self): jValueTemplateSelfReading = "{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"grades\":\"\",\"levels\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}" jValueTemplateParentChildReading = "{\"userId\":\"%s\",\"fieldName\":\"\",\"fieldValue\":\"全部类别\",\"theStageOfTheChild\":\"\",\"parentalEnglishLevel\":\"\",\"supportingResources\":\"有音频\",\"offset\":%d,\"limit\":%d}" paramDictSelfReading = { "curUrl": SelfReadingUrl, "offset": 0, "limit": DefaultPageSize, "jValueTemplate": jValueTemplateSelfReading } self.getBookQuery2(paramDictSelfReading) paramDictParentChildReading = { "curUrl": ParentChildReadingUrl, "offset": 0, "limit": DefaultPageSize, "jValueTemplate": jValueTemplateParentChildReading } self.getBookQuery2(paramDictParentChildReading) def getBookQuery2(self, curParamDict): print("getBookQuery2: curParamDict=%s" % curParamDict) curUrl = curParamDict["curUrl"] jValueTemplate = curParamDict["jValueTemplate"] offset = curParamDict["offset"] limit = curParamDict["limit"] jValueStr = jValueTemplate % (gUserId, offset, limit) jcJsonDict = { "J": jValueStr, "C": 0 } jcJsonDictStr = json.dumps(jcJsonDict) curParamDict["jValueStr"] = jValueStr curParamDict["jcJsonDict"] = jcJsonDict curParamDict["jcJsonDictStr"] = jcJsonDictStr curHeaders = copy.deepcopy(gHeaders) curTimestampInt = getCurTimestamp() curTimestampStr = str(curTimestampInt) curHeaders["timestamp"] = curTimestampStr curSignature = self.generateSignature(curTimestampInt, jValueStr) curHeaders["signature"] = curSignature self.crawl(curUrl, method="POST", # data=jcJsonDict, data= jcJsonDictStr, # callback=curCallback, callback=self.getBookQuery2Callback, headers=curHeaders, save=curParamDict ) def generateSignature(self, timestampInt, jValueOrUrlEndpoint): # print("generateSignature: timestampInt=%d, jValueOrUrlEndpoint=%s" % (timestampInt, jValueOrUrlEndpoint)) # userId = "1134723" userId = gUserId timestamp = "%s" % timestampInt # localObject = "/Reading.svc/parentChildReadingBookQuery2" # localObject = jValueOrUrlEndpoint # userToken = "40d2267f-359e-4526-951a-66519e5868c3" userToken = gUserToken # fixedSault = “AyGt7ohMR!xx#N" # secretKey = “AyGt7ohMR!xx#N" secretKey = gSecretKey # strToCalc = userId + timestamp + localObject + jValueOrUrlEndpoint + fixedSault # strToCalc = timestamp + localObject + fixedSault strToCalc = userId + timestamp + jValueOrUrlEndpoint + userToken + secretKey # print("strToCalc=%s" % strToCalc) encodedStr = strToCalc.encode() # encodedStr = strToCalc.encode("UTF-8") # print("encodedStr=%s" % encodedStr) md5Result = md5(encodedStr) # print("md5Result=%s" % md5Result) # md5Result=<md5 HASH object @ 0x1044f1df0> # md5Result = md5() # md5Result.update(strToCalc) # md5Digest = md5Result.digest() # print("md5Digest=%s" % md5Digest) # # print("len(md5Digest)=%s" % len(md5Digest)) md5Hexdigest = md5Result.hexdigest() # print("md5Hexdigest=%s" % md5Hexdigest) # print("len(md5Hexdigest)=%s" % len(md5Hexdigest)) # md5Hexdigest=c687d5dfa015246e6bdc6b3c27c2afea # print("md5=%s from %s" % (md5Hexdigest, strToCalc)) return md5Hexdigest # return md5Digest def extractResponseData(self, respJson): """ { "C": 2, "J": "H4sIAA.......AA=", "M": "1001", "ST": null } """ # respJson = json.loads(respJson) respM = respJson["M"] if respM != RESPONSE_OK: return None encodedStr = respJson["J"] decodedStr = base64.b64decode(encodedStr) # print("decodedStr=%s" % decodedStr) decompressedStr = gzip.decompress(decodedStr) # print("decompressedStr=%s" % decompressedStr) decompressedStrUnicode = decompressedStr.decode("UTF-8") # print("decompressedStrUnicode=%s" % decompressedStrUnicode) decompressedJson = json.loads(decompressedStrUnicode) respDataDict = decompressedJson return respDataDict def getBookQuery2Callback(self, response): respUrl = response.url print("respUrl=%s" % respUrl) prevParaDict = response.save print("prevParaDict=%s" % prevParaDict) respJson = response.json print("respJson=%s" % respJson) respData = self.extractResponseData(respJson) print("respData=%s" % respData) if respData: newOffset = prevParaDict["offset"] + prevParaDict["limit"] prevParaDict["offset"] = newOffset self.getBookQuery2(prevParaDict) bookSeriesList = respData for eachBookSerie in bookSeriesList: print("eachBookSerie=%s" % eachBookSerie) self.getStorybookDetail(eachBookSerie) else: print("!!! %s return no more data: %s" % (response.url, respJson)) def getStorybookDetail(self, bookSerieDict): print("getStorybookDetail: bookSerieDict=%s" % bookSerieDict) seriePrimayKey = bookSerieDict["pk"] urlEndpoint = "/Reading.svc/viewEnglishSeries2/%s/%s" % (gUserId, seriePrimayKey) fullUrl = "%s%s" % (gServerPort, urlEndpoint) # http://www.xiaohuasheng.cn:83/Reading.svc/viewEnglishSeries2/1134723/31 print("urlEndpoint=%s, fullUrl=%s" % (urlEndpoint, fullUrl)) curHeaders = copy.deepcopy(gHeaders) curTimestampInt = getCurTimestamp() curTimestampStr = str(curTimestampInt) curHeaders["timestamp"] = curTimestampStr curSignature = self.generateSignature(curTimestampInt, urlEndpoint) curHeaders["signature"] = curSignature self.crawl(fullUrl, method="GET", callback=self.getSerieDetailCallback, headers=curHeaders, save=bookSerieDict ) def getSerieDetailCallback(self, response): respUrl = response.url print("respUrl=%s" % respUrl) bookSerieDict = response.save print("bookSerieDict=%s" % bookSerieDict) respJson = response.json print("respJson=%s" % respJson) respData = self.extractResponseData(respJson) print("respData=%s" % respData) respDict = respData[0] # respDict["url"] = response.url return respDict |
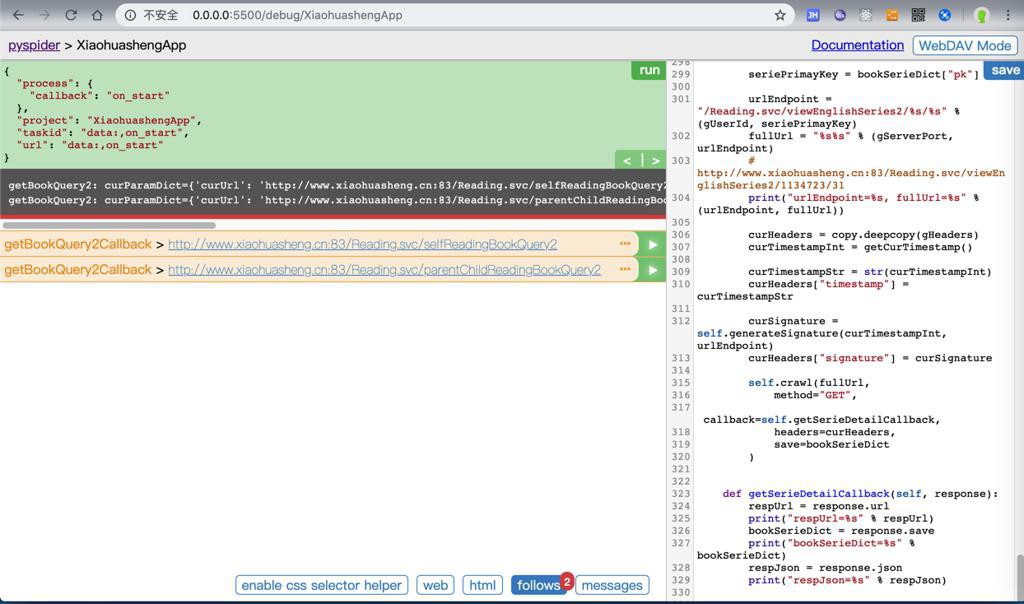
返回selfReadingBookQuery2和parentChildReadingBookQuery2的数据:
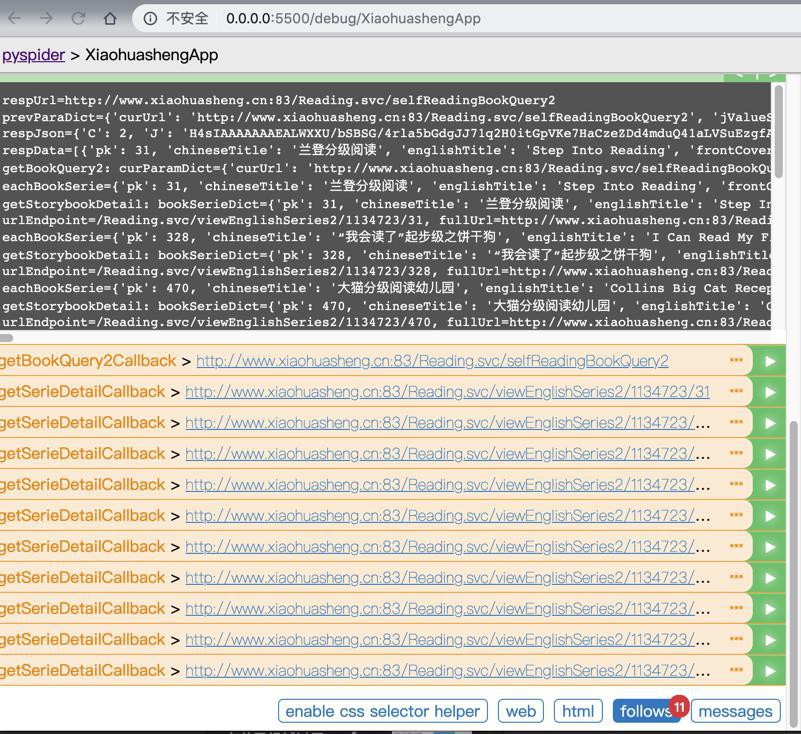
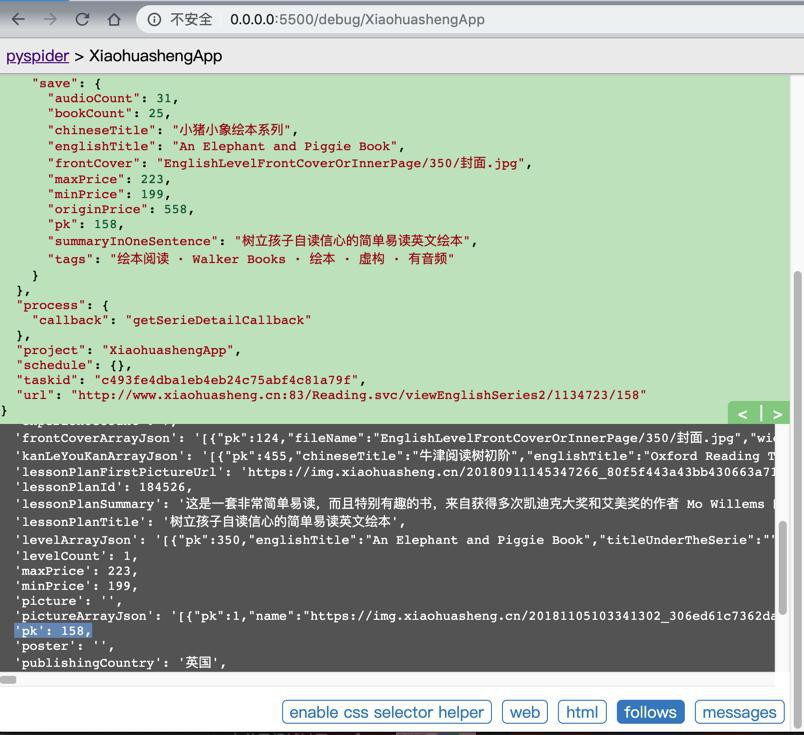
以及每个series的详情了:
不过,去批量运行后,始终只有17个url,就停了:
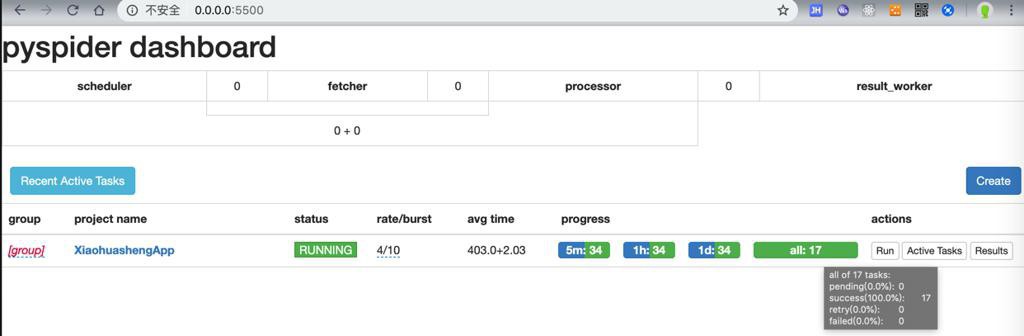
而不是以为的,有几十几百个url,以及能继续运行。
找了半天原因,终于想到是:
即使每次offset变了,json参数变了,由于两个post的url一直没变:
1 2 3 4 5 6 | SelfReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/selfReadingBookQuery2"ParentChildReadingUrl = "http://www.xiaohuasheng.cn:83/Reading.svc/parentChildReadingBookQuery2" |
导致后续不继续运行了。
所以参考自己的:
去加上#hash #someDiffValue,试试。
代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | # add hash value for url to force re-crawl when POST url not changed timestampStr = datetime.now().strftime("%Y%m%d_%H%M%S_%f") curUrlWithHash = curUrl + "#" + timestampStr # fakeItagForceRecrawl = "%s_%s_%s" % (timestampStr, offset, limit) self.crawl(curUrlWithHash, # itag=fakeItagForceRecrawl, # To force re-crawl for next page method="POST", # data=jcJsonDict, data= jcJsonDictStr, # callback=curCallback, callback=self.getBookQuery2Callback, headers=curHeaders, save=curParamDict ) |
调试效果:
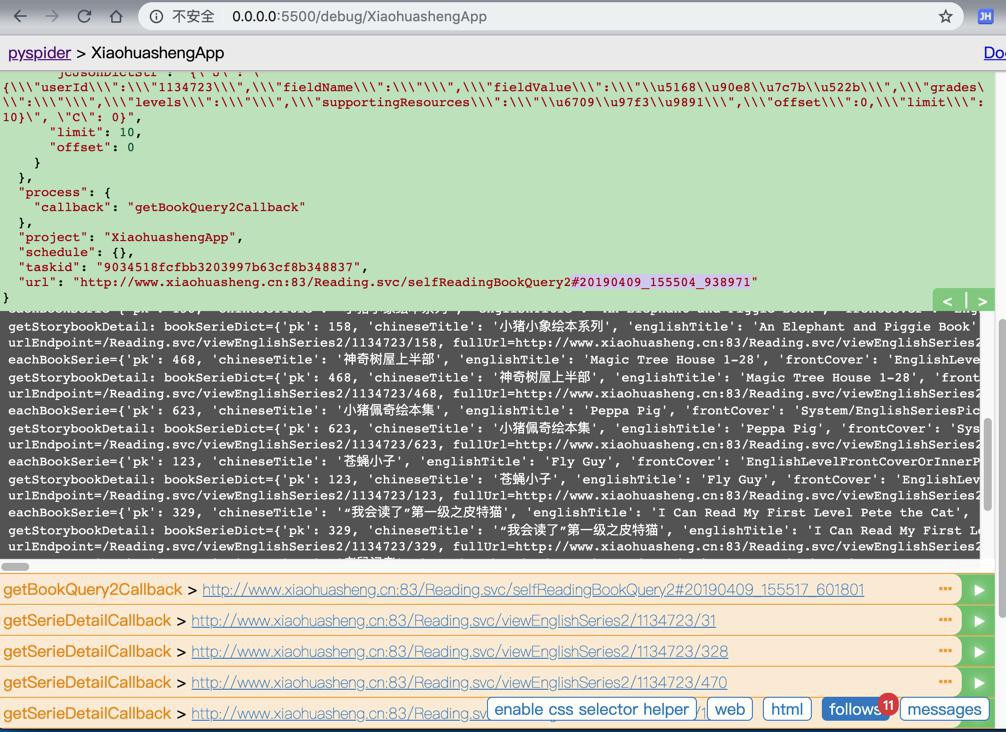
1 | /selfReadingBookQuery2#20190409_162018_413205 |
批量运行试试,能否继续爬取所有数据。
是可以继续爬取后续数据的:
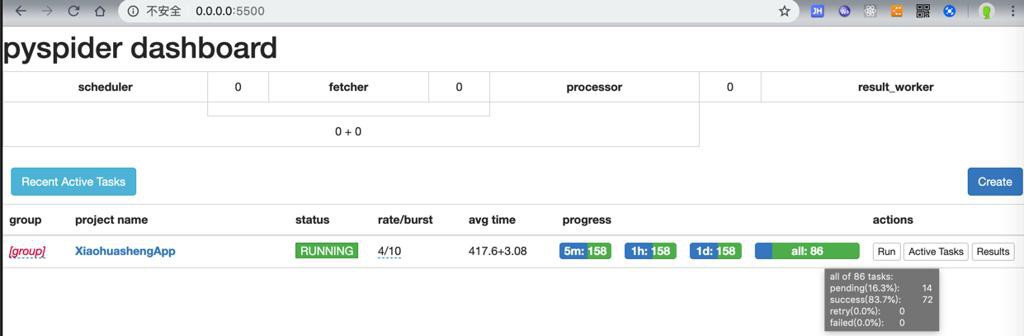
不过只有117个:
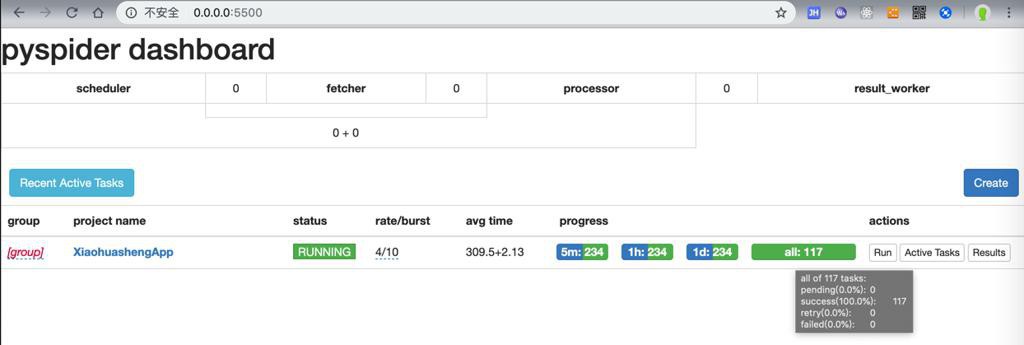
也不太对的感觉
->因为之前:
- 自主阅读:50多个
- 亲子阅读:90多个
的绘本系列,加起来应该有140才对
或许是部分url重复了?好像是的。
加起来去重后,看来是117个绘本。
【总结】
此处是通过给url加上#hash,保证每次hash值不同,使得post同样的url#hash,url值不同,得以继续爬取剩余数据。
转载请注明:在路上 » 【已解决】PySpider无法继续爬取剩余绘本数据