折腾:
【记录】用PySpider去爬取scholastic的绘本书籍数据
期间,遇到一个稍微特殊一点的内容的提取:
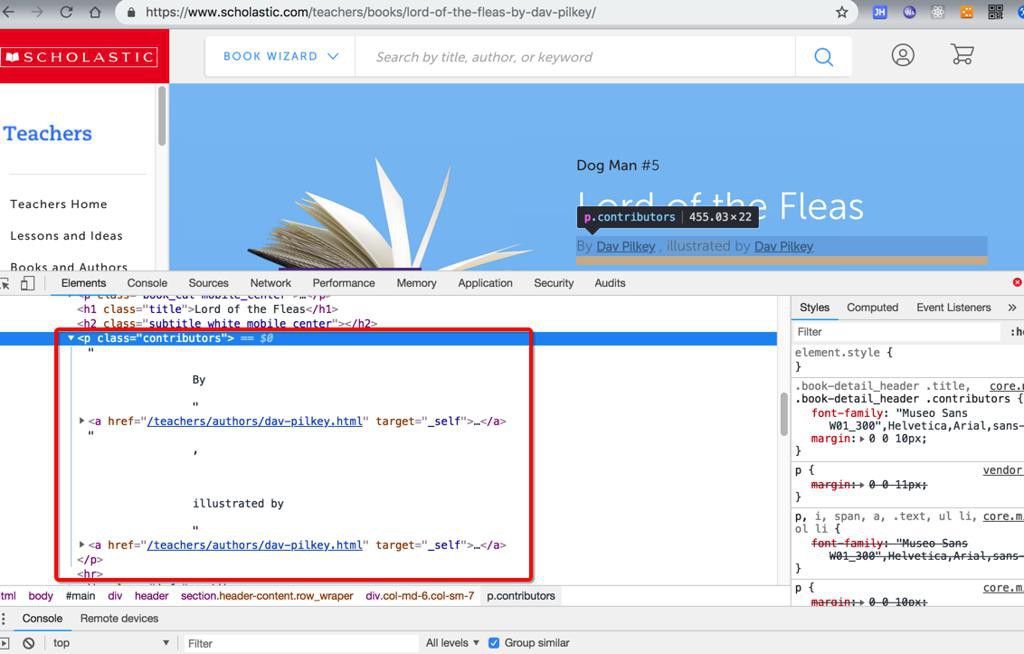
1 2 3 4 5 6 7 8 | <p class="contributors"> By <a href="/teachers/authors/dav-pilkey.html" target="_self"><strong> Dav Pilkey</strong></a> , illustrated by <a href="/teachers/authors/dav-pilkey.html" target="_self"><strong> Dav Pilkey</strong></a> </p> |
现在想要:
提取出:
除了authors之外,还要提取出:illustrator,要区分开。
之前用:
1 2 3 4 5 6 7 8 | authors = [] contributors = response.doc('p[class="contributors"]') print("contributors=%s" % contributors) for eachAuthor in contributors.find('a[href] strong').items(): print("eachAuthor=%s" % eachAuthor) authorText = eachAuthor.text() print("authorText=%s" % authorText) authors.append(authorText) |
可以获取authors没问题,但是会把illustrator混在一起。
现在要去想办法提取出来
通过代码:
1 2 3 4 5 6 | for eachContributorContent in contributors.contents(): print("eachContributorContent=%s" % eachContributorContent) contentItemType = type(eachContributorContent) print("contentItemType=%s" % contentItemType) # contentText = eachContributorContent.text() # print("contentText=%s" % contentText) |
调试输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | eachContributorContent= By contentItemType=<class 'lxml.etree._ElementUnicodeResult'>eachContributorContent=<Element a at 0x102ac3e58>contentItemType=<class 'lxml.html.HtmlElement'>eachContributorContent= , illustrated by contentItemType=<class 'lxml.etree._ElementUnicodeResult'>eachContributorContent=<Element a at 0x102ac32c8>contentItemType=<class 'lxml.html.HtmlElement'>eachContributorContent= contentItemType=<class 'lxml.etree._ElementUnicodeResult'> |
所以:
其中一个思路是:
去判断each的content的type,如果是str ? lxml.etree._ElementUnicodeResult
去判断是否包含:illustrated by
如果是,则开始计算illustrator的值,否则一直计算authors
如果type是lxml.html.HtmlElement,则去获取其中的.text()
然后用:
eachContributorContent.text()
会报错,然后参考:
python lxml.html.HtmlElement
“getset_descriptor
text = <attribute ‘text’ of ‘lxml.etree._Element’ object…”
看起来应该用:
text
结果此处是用text但是获得是none:
1 2 3 4 5 6 7 8 9 | ---------- eachContributorContent= By contentItemType=<class 'lxml.etree._ElementUnicodeResult'>---------- eachContributorContent=<Element a at 0x101647458>contentItemType=<class 'lxml.html.HtmlElement'>contentText=None |
继续参考:
去找,lxml.html.HtmlElement如何获取text
此处的html是:
<strong>xxx</strong>
感觉或许是:
“find(self, path, namespaces=None)
Finds the first matching subelement, by tag name or path.”
去获取值,去试试
1 2 | strongValue = eachContributorContent.find("strong")print("strongValue=%s" % strongValue) |
得到:
strongValue=<Element strong at 0x105b5d908>
看来是可以的,然后可以去:
1 2 3 4 5 6 7 | # contentText = eachContributorContent.text()strongElement = eachContributorContent.find("strong")print("strongElement=%s" % strongElement)# contentText = eachContributorContent.textcontentText = strongElement.textprint("contentText=%s" % contentText)currentList.append(contentText) |
获取到值。
另外去:
1 2 3 4 5 6 7 8 | else: # is text print("Not lxml.html.HtmlElement: eachContributorContent=%s" % eachContributorContent) pureText = eachContributorContent.text print("pureText=%s" % pureText) if "illustrated by" in pureText: print("+++ found illustrated by") illustrator.append(pureText) |
结果:
1 | AttributeError: 'lxml.etree._ElementUnicodeResult' object has no attribute 'text' |
所以要再去搞清楚:
lxml.etree._ElementUnicodeResult 如何获得text
lxml.etree._ElementUnicodeResult text
lxml.etree._elementunicoderesult to str
“$ pydoc lxml.etree._ElementUnicodeResult
lxml.etree._ElementUnicodeResult = class _ElementUnicodeResult(__builtin__.unicode)
| Method resolution order:
| _ElementUnicodeResult
| __builtin__.unicode
| __builtin__.basestring
| __builtin__.object”
其就是从unicode继承出来的
-》可以直接看做普通的(Unicode)字符串,此处Python 3,所以可以再去加上str转换一下,以防万一:
1 2 | # pureText = eachContributorContent.textpureText = str(eachContributorContent) |
然后就可以得到字符串了。
【总结】
最后用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | authors = [] illustrator = [] # for eachAuthor in contributors.find('a[href] strong').items(): # print("eachAuthor=%s" % eachAuthor) # authorText = eachAuthor.text() # print("authorText=%s" % authorText) # authors.append(authorText) # special: has illustrator # https://www.scholastic.com/teachers/books/riff-raff-sails-the-high-cheese-by-susan-schade/ contributors = response.doc('p[class="contributors"]') print("contributors=%s" % contributors) for eachContributorItem in contributors.items(): print("eachContributorItem=%s" % eachContributorItem) itemText = eachContributorItem.text() print("itemText=%s" % itemText) # for eachContributorChild in contributors.children(): # print("eachContributorChild=%s" % eachContributorChild) # childText = eachContributorChild.text() # print("childText=%s" % childText) currentAuthorList = authors for eachContributorContent in contributors.contents(): print("---------- eachContributorContent=%s" % eachContributorContent) contentItemType = type(eachContributorContent) print("contentItemType=%s" % contentItemType) if contentItemType is lxml.html.HtmlElement: # is element # contentText = eachContributorContent.text() strongElement = eachContributorContent.find("strong") print("strongElement=%s" % strongElement) # contentText = eachContributorContent.text contentText = strongElement.text print("contentText=%s" % contentText) strippedText = contentText.strip() currentAuthorList.append(strippedText) else: # is text print("Not lxml.html.HtmlElement: eachContributorContent=%s" % eachContributorContent) # pureText = eachContributorContent.text pureText = str(eachContributorContent) print("pureText=%s" % pureText) if "illustrated by" in pureText: print("+++ found illustrated by") currentAuthorList = illustrator print("authors=%s" % authors) print("illustrator=%s" % illustrator) |
输出:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 | contributors=<p class="contributors"> By <a href="https://www.scholastic.com/teachers/authors/dav-pilkey.html"><strong> Dav Pilkey</strong></a> , illustrated by <a href="https://www.scholastic.com/teachers/authors/dav-pilkey.html"><strong> Dav Pilkey</strong></a> </p> eachContributorItem=<p class="contributors"> By <a href="https://www.scholastic.com/teachers/authors/dav-pilkey.html"><strong> Dav Pilkey</strong></a> , illustrated by <a href="https://www.scholastic.com/teachers/authors/dav-pilkey.html"><strong> Dav Pilkey</strong></a> </p> itemText=By Dav Pilkey , illustrated by Dav Pilkey---------- eachContributorContent= By contentItemType=<class 'lxml.etree._ElementUnicodeResult'>Not lxml.html.HtmlElement: eachContributorContent= By pureText= By ---------- eachContributorContent=<Element a at 0x10fbe9958>contentItemType=<class 'lxml.html.HtmlElement'>strongElement=<Element strong at 0x10fbe9778>contentText= Dav Pilkey---------- eachContributorContent= , illustrated by contentItemType=<class 'lxml.etree._ElementUnicodeResult'>Not lxml.html.HtmlElement: eachContributorContent= , illustrated by pureText= , illustrated by +++ found illustrated by---------- eachContributorContent=<Element a at 0x10fbe9688>contentItemType=<class 'lxml.html.HtmlElement'>strongElement=<Element strong at 0x10fbe9a48>contentText= Dav Pilkey---------- eachContributorContent= contentItemType=<class 'lxml.etree._ElementUnicodeResult'>Not lxml.html.HtmlElement: eachContributorContent= pureText= authors=['Dav Pilkey']illustrator=['Dav Pilkey'] |
终于分析出我们要的作者和插座作者的列表了。
另外再去验证了:
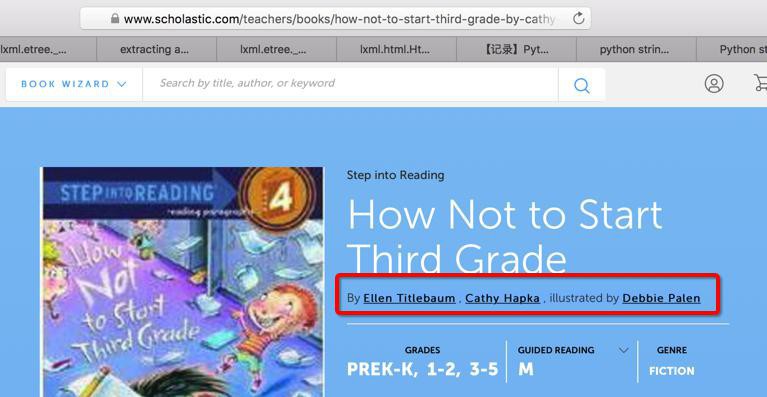
也是可以分析出对应的值的:
1 2 | authors=['Ellen Titlebaum', 'Cathy Hapka']illustrator=['Debbie Palen'] |
转载请注明:在路上 » 【已解决】PySpider中用PyQuery提取出html中p下面的a的href中的多个strong字符串