为了给教程:
自动化测试概览
增加易懂的例子。
此处去Mac中写个简单的Selenium的例子,比如调用浏览器,打开百度主页,输入内容,点击搜索,输出搜索结果的列表
先去Mac中安装和搭建Selenium的环境:
【未解决】Mac中搭建Selenium的Python开发环境
其中:
【已解决】Mac中下载Selenium的Chrome的driver:ChromeDriver
另外还要:
查看 chromedriver 和 Chrome版本一致
- ChromeDriver:89.0.4389.23
- Chrome:版本 89.0.4389.90(正式版本) (x86_64)
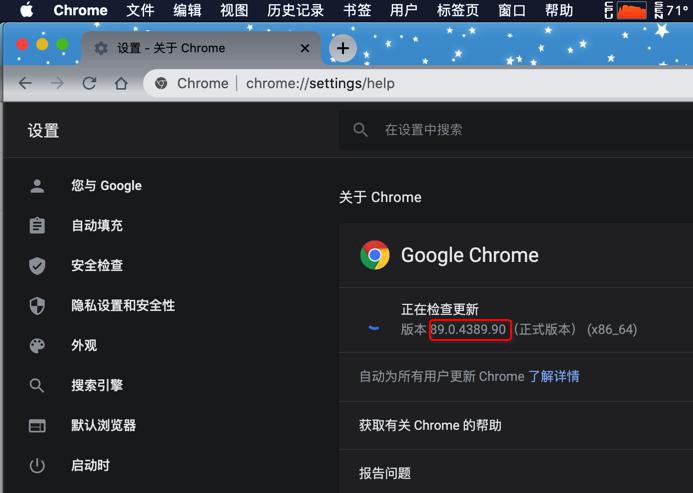
其中:两个主版本号是一致的:89.0.4389
最后末尾的版本号 不太一致:23 vs 90,估计影响不大
然后即可:
【已解决】Mac中搭建Selenium的Python开发环境
接着继续写代码
其他参考资料
1 2 3 4 5 6 | from selenium import webdriverfrom selenium.webdriver.common.keys import KeyschromeDriver = webdriver.Chrome()chromeDriver.get(baiduUrl) |
可以启动Chrome了:
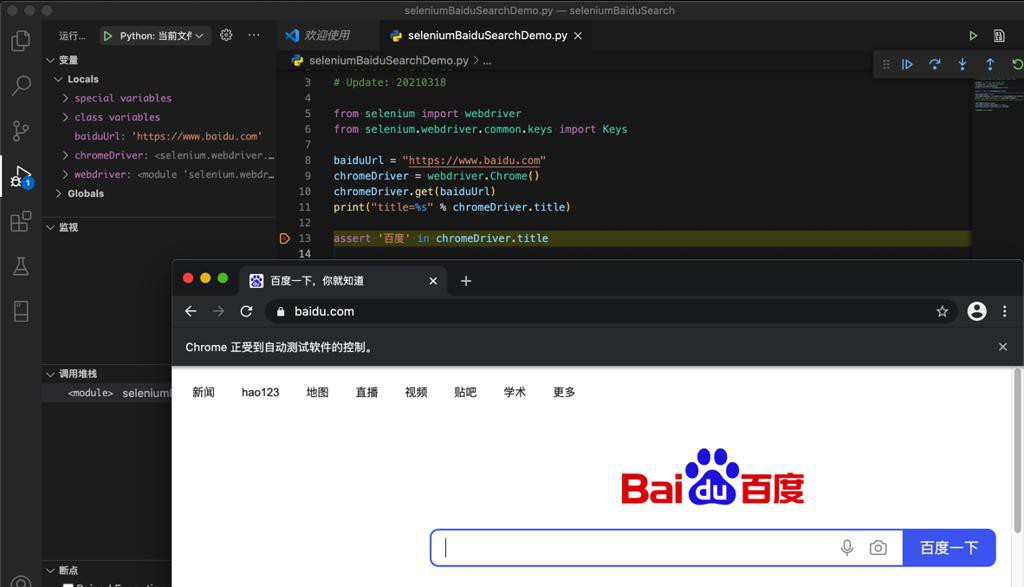
期间,可以看出此处页面的确,如我们所希望的,进入到了百度首页
如果担心发生意外,则可以加上逻辑确保符合希望:
【整理】用Chrome或Chromium查看百度首页中各元素的html源码
所以可以代码写成:
1 | assert chromeDriver.title == "百度一下,你就知道" |
或:
1 | assert '百度' in chromeDriver.title |
确保,的确进入了百度的页面
接着,需要去:搞清楚,如何定位到 百度搜索的输入框:
【已解决】Selenium中如何定位元素:百度首页中的输入框
接下来,就简单了,就是把要实现的逻辑,用Selenium实现即可:
希望给搜索框中输入内容,点击 百度一下 按钮,触发搜索
得到搜索结果,默认只显示第一页
然后再去从搜索结果中,解析得到第一页的文章的标题
最终得到百度搜索结果第一页的文章的标题的列表
所以先去:
【已解决】Selenium中给百度搜索框中输入文字并触发搜索
接着,再去想办法获取到搜索结果的标题列表:
【已解决】Selenium中Python解析百度搜索结果第一页获取标题列表
然后再去另外实现:
【已解决】Mac中录制gif动画图片
【总结】
最后代码是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 | # Function: demo selenium do baidu search and extract result# Author: Crifan Li# Update: 20210327from selenium import webdriverfrom selenium.webdriver.common.keys import Keysfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.support import expected_conditions as ECfrom bs4 import BeautifulSoupimport rechromeDriver = webdriver.Chrome()################################################################################# Open url################################################################################chromeDriver.get(baiduUrl)print("title=%s" % chromeDriver.title)assert chromeDriver.title == "百度一下,你就知道"# assert '百度' in chromeDriver.title################################################################################# Find/Locate search button################################################################################SearchButtonId = "kw"searchButtonElem = chromeDriver.find_element_by_id(SearchButtonId)print("searchButtonElem=%s" % searchButtonElem)# searchButtonElem=<selenium.webdriver.remote.webelement.WebElement (session="e0d8b72f2fc31e27220f66fcbdb22bfc", element="21aa0e9d-04fa-4385-b16b-d82998068887")>################################################################################# Input text################################################################################searchButtonElem.clear()print("Clear existed content")searchStr = "crifan"searchButtonElem.send_keys(searchStr)print("Entered %s to search box" % searchStr)################################################################################# Click button################################################################################# Method 1: emulate press Enter key# searchButtonElem.send_keys(Keys.RETURN)# print("Pressed Enter/Return key")# Method 2: find button and clickBaiduSearchId = "su"baiduSearchButtonElem = chromeDriver.find_element_by_id(BaiduSearchId)print("baiduSearchButtonElem=%s" % baiduSearchButtonElem)baiduSearchButtonElem.click()print("Clicked button %s" % baiduSearchButtonElem)################################################################################# Wait page change/loading completed# -> following element makesure show = visible# -> otherwise possibly can NOT find elements################################################################################MaxWaitSeconds = 10numTextElem = WebDriverWait(chromeDriver, MaxWaitSeconds).until( EC.presence_of_element_located((By.XPATH, "//span[@class='nums_text']")))print("Search complete, showing: %s" % numTextElem)################################################################################# Extract result################################################################################# Method 1: use Selenium to extract title listsearchResultAList = chromeDriver.find_elements_by_xpath("//h3[contains(@class, 't')]/a")print("searchResultAList=%s" % searchResultAList)searchResultANum = len(searchResultAList)print("searchResultANum=%s" % searchResultANum)for curIdx, curSearchResultAElem in enumerate(searchResultAList): curNum = curIdx + 1 print("%s [%d] %s" % ("-"*20, curNum, "-"*20)) baiduLinkUrl = curSearchResultAElem.get_attribute("href") print("baiduLinkUrl=%s" % baiduLinkUrl) title = curSearchResultAElem.text print("title=%s" % title)# # Method 2: use BeautifulSoup to extract title list# curHtml = chromeDriver.page_source# curSoup = BeautifulSoup(curHtml, 'html.parser')# beginTP = re.compile("^t.*")# searchResultH3List = curSoup.find_all("h3", {"class": beginTP})# print("searchResultH3List=%s" % searchResultH3List)# searchResultH3Num = len(searchResultH3List)# print("searchResultH3Num=%s" % searchResultH3Num)# for curIdx, searchResultH3Item in enumerate(searchResultH3List):# curNum = curIdx + 1# print("%s [%d] %s" % ("-"*20, curNum, "-"*20))# aElem = searchResultH3Item.find("a")# # print("aElem=%s" % aElem)# baiduLinkUrl = aElem.attrs["href"]# print("baiduLinkUrl=%s" % baiduLinkUrl)# title = aElem.text# print("title=%s" % title)################################################################################# End close################################################################################chromeDriver.close() |
对应的gif动画是:
/Users/crifan/dev/dev_root/python/seleniumBaiduSearch/gif/SeleniumDoBaiduSearch_24M.gif
附上相关资料:
- 自己的教程
- 文档和教程 · Selenium知识总结
- 心得和总结 · Selenium知识总结
- 官网
- 英文:
- 3. Navigating — Selenium Python Bindings 2 documentation
- 4. Locating Elements — Selenium Python Bindings 2 documentation
- 中文
- 4. 查找元素 — Selenium-Python中文文档 2 documentation
- 5. 等待页面加载完成(Waits) — Selenium-Python中文文档 2 documentation
- 6. 页面对象 — Selenium-Python中文文档 2 documentation
转载请注明:在路上 » 【已解决】Mac中用Selenium自动操作浏览器实现百度搜索