之前别人做的一个内容管理系统,后台是Django,前端是reactjs的Antd Pro。
之前一直发现前端页面loading很慢:
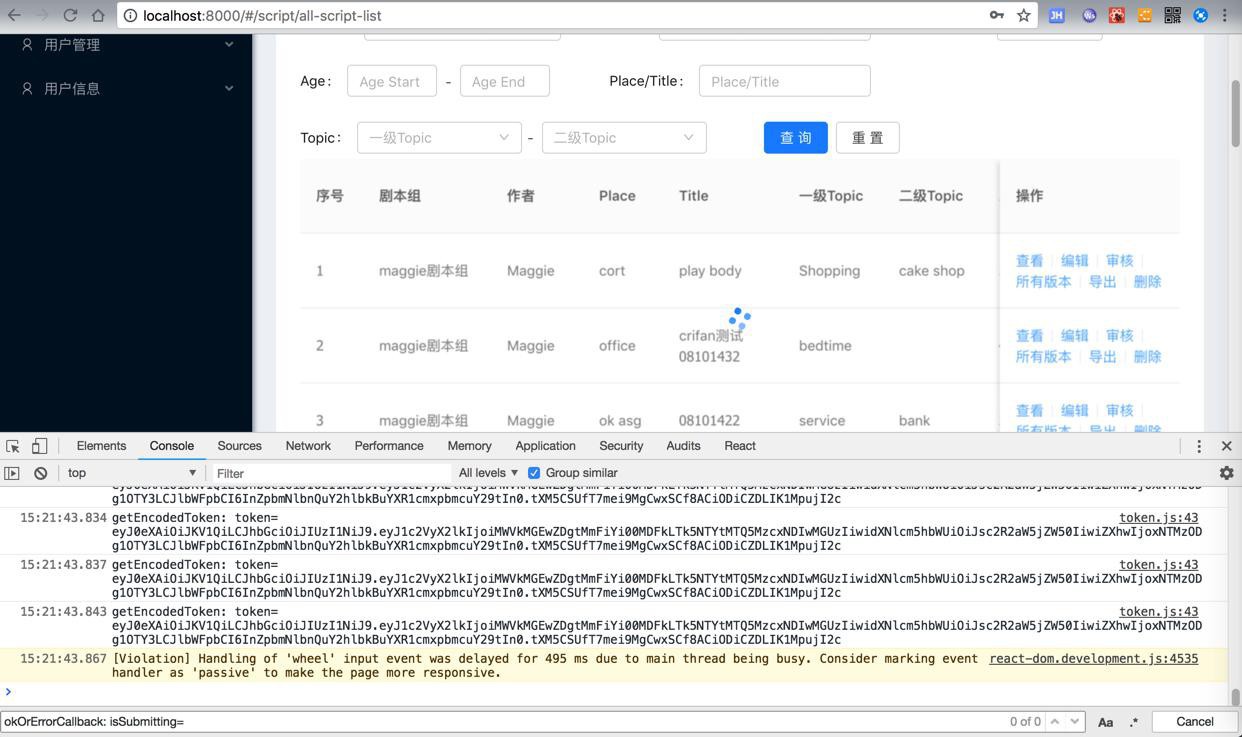
之前一直不知道原因,后来的后来发现是:
后端代码竟然是:
对于访问接口:
由于没有检测到page的参数,竟然返回所有的page的数据
-》而此处数据量很大(有几百几千个)
-〉所以导致后台返回和前端加载,都要耗时,所以loading时间很长
-》所以现在需要去优化:
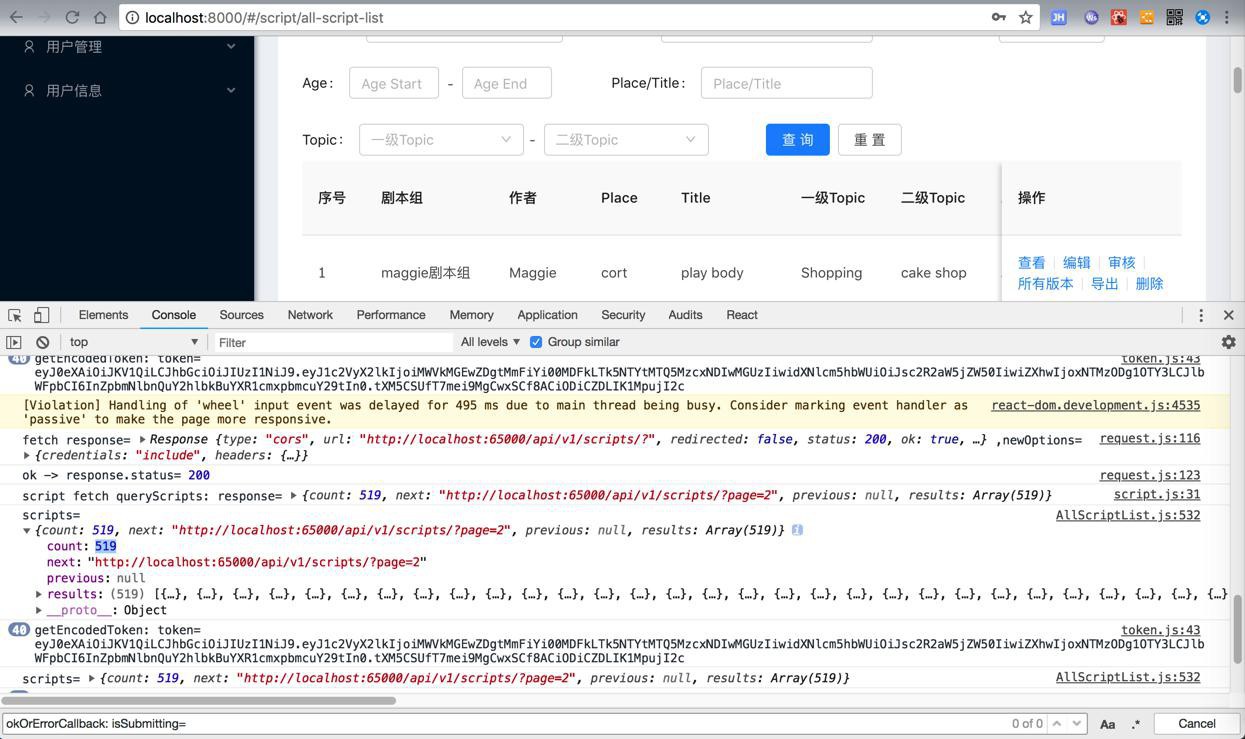
而经过调试发现:
此处虽然后台接口,传入page=1但是返回所以数据是有问题
但是更加有问题的是前端页面,前端页面已经返回了数据:
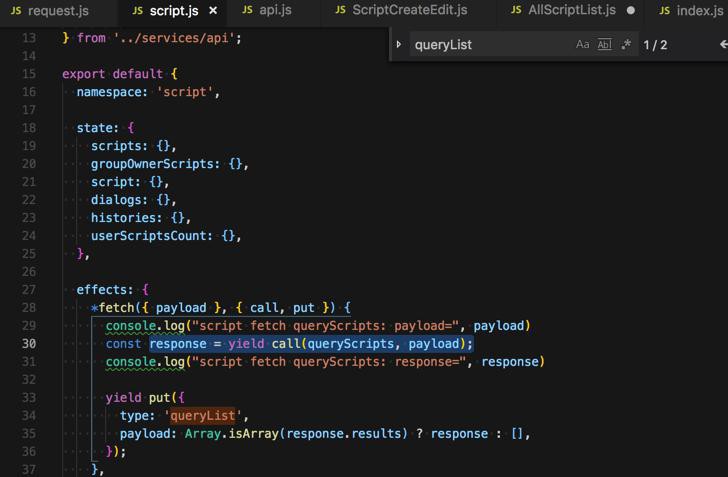
-》
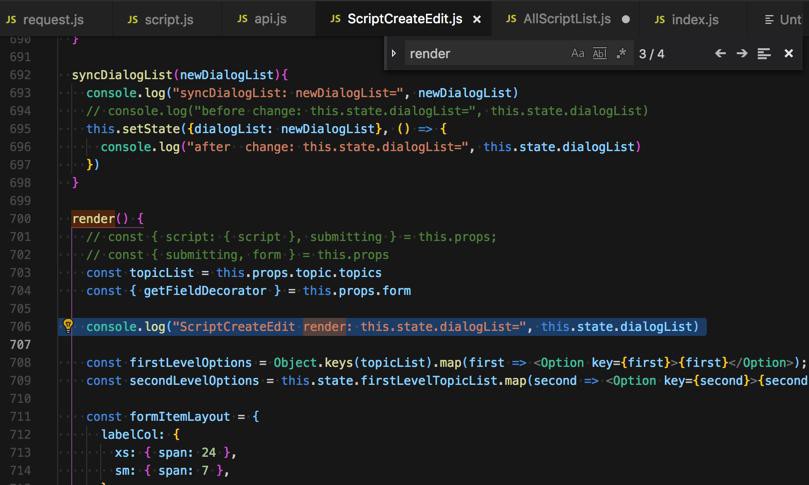
传递到redux的store,更新了props中的scripts了:
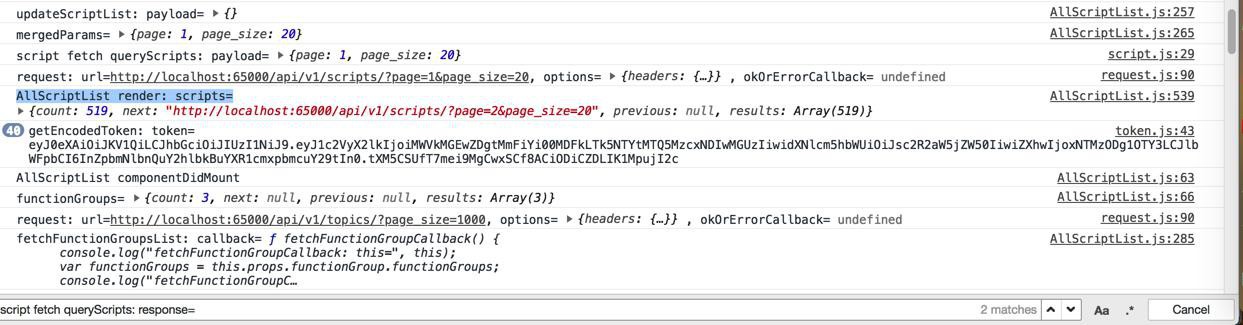
但是等待了半天之后,最后才调用此处的:
script fetch queryScripts: response=
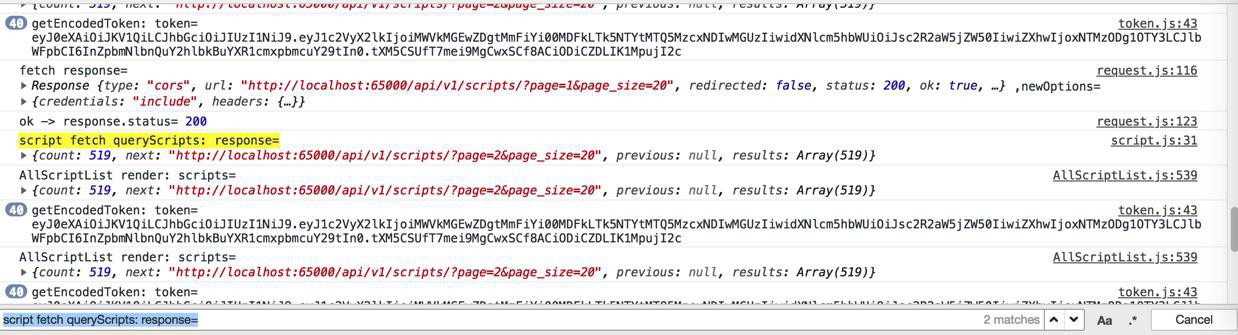
-》即:
此处yield后的数据已经返回了
render都已经显示了
但是loading还存在,所以去:
【已解决】Antd Pro中如何绑定loading确保返回后正在加载立刻消失
后来感觉像是:
const response = yield call(queryScripts, payload);
返回的太慢,然后如果返回了,则之后的queryList和endLoading都是正常快速执行的。
-》所以要去找到为何:
yield call(queryScripts, payload);
返回太慢的原因
ant design pro yield call 太慢
antd pro yield call 太慢
antd pro yield call 返回 很慢
还是去搞清楚,此处的call的源码 和具体的调用路径
然后发现了,好像没什么特殊的,但是就是很慢:
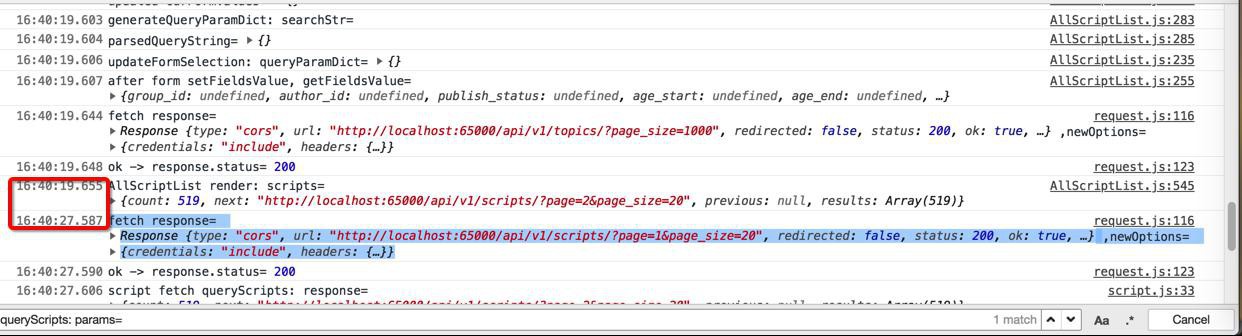
中间差了8秒
而实际上,在此之前,早就获取到promise的返回的数据了:
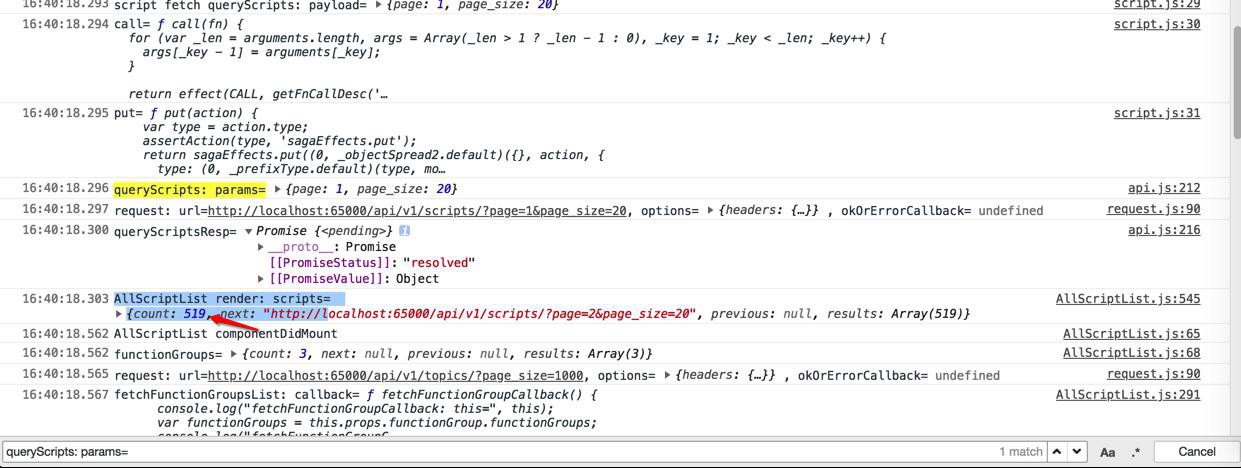
1 2 3 4 5 6 7 8 9 10 | queryScripts: params=1. {page: 1, page_size: 20}16:40:18.297request.js:90 request: url=http://localhost:65000/api/v1/scripts/?page=1&page_size=20, options=1. {headers: {…}}, okOrErrorCallback= undefined16:40:18.300api.js:216 queryScriptsResp=1. Promise {<pending>} 1. __proto__:Promise 2. [[PromiseStatus]]:"resolved" 3. [[PromiseValue]]:Object |
不过看到此处三个Fetch同时返回的感觉:
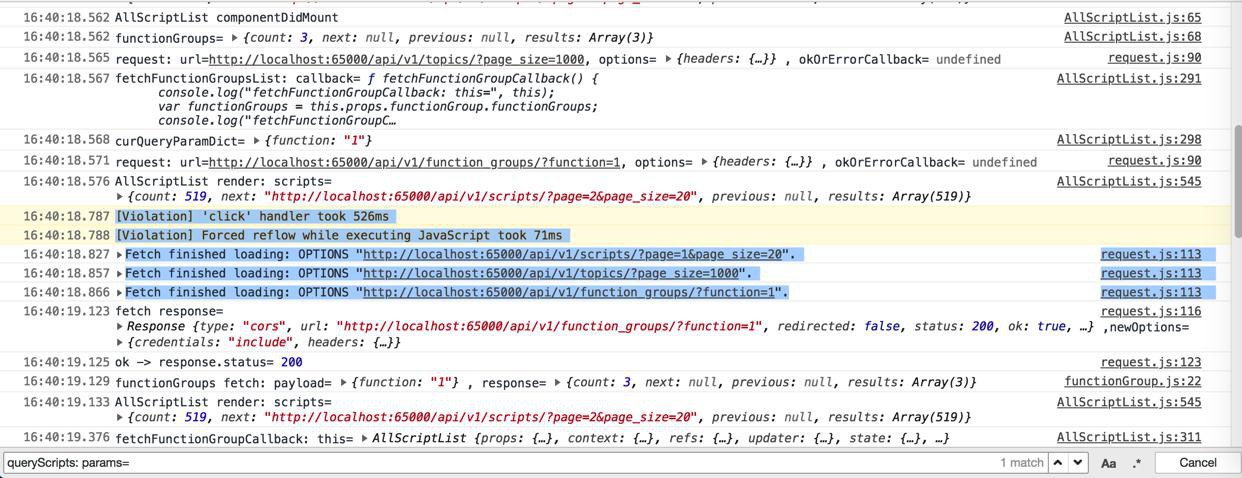
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | [Violation] 'click' handler took 526ms16:40:18.788 [Violation] Forced reflow while executing JavaScript took 71ms16:40:18.827 request.js:113 Fetch finished loading: OPTIONS "http://localhost:65000/api/v1/scripts/?page=1&page_size=20".request @ request.js:113_callee33$ @ api.js:213tryCatch @ runtime.js:62...updateScriptList @ AllScriptList.js:270componentWillMount @ AllScriptList.js:61callComponentWillMount @ react-dom.development.js:11507...dispatchInteractiveEvent @ react-dom.development.js:453216:40:18.857 request.js:113 Fetch finished loading: OPTIONS "http://localhost:65000/api/v1/topics/?page_size=1000".request @ request.js:113_callee32$ @ api.js:204tryCatch @ runtime.js:62...dispatchInteractiveEvent @ react-dom.development.js:453216:40:18.866 request.js:113 Fetch finished loading: OPTIONS "http://localhost:65000/api/v1/function_groups/?function=1". |
感觉像是浏览器的js的Fetch的promise返回很慢:
【已解决】Chrome中js的fetch response很慢
期间:
【已解决】Django中如何自定义返回分页数据
此处继续调试发现一个现象:
js中有返回的时间,相差了8秒
分别是21秒的:Fetch finished loading: OPTIONS “http://localhost:65000/api/v1/scripts/?page=1&page_size=20“.
和29秒的fetch response=
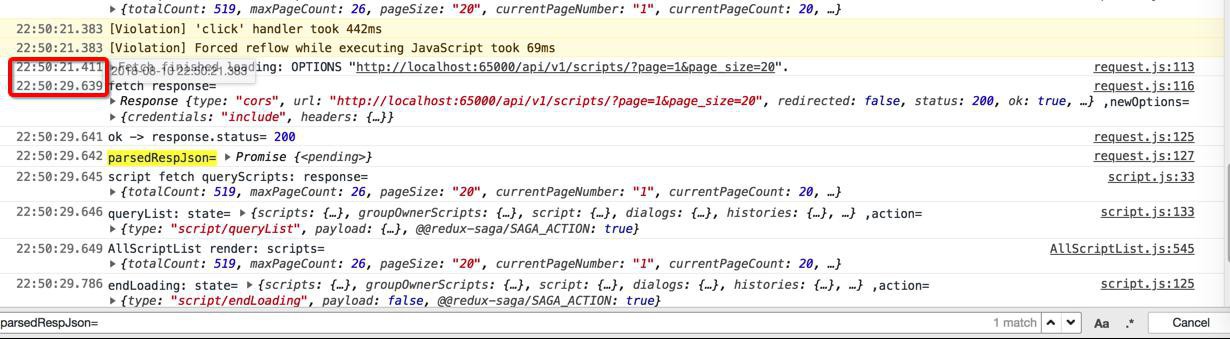
而此处Django后台的log是:
1 2 | 127.0.0.1 - - [10/Aug/2018 22:50:20] "OPTIONS /api/v1/scripts/?page=1&page_size=20 HTTP/1.1" 200 -127.0.0.1 - - [10/Aug/2018 22:50:29] "GET /api/v1/scripts/?page=1&page_size=20 HTTP/1.1" 200 - |
难道是:
此处OPTIONS之后再GET,就一定会需要间隔这么长时间?
django jwt api OPTIONS too slow
django DWF api OPTIONS too slow
搜了下,项目中没有DEFAULT_THROTTLE_CLASSES
django DWF GET too slow
django DWF some api too slow
后来再去调试发现:
貌似就是现有之前别人写的代码的逻辑,耗时太长:
这中间的9秒左右的耗费时间分别是:
(1)检索history占了4秒 到了:23:03:04
1 2 3 4 5 6 7 8 9 10 11 12 13 | for curHisotryIdIdx, eachHistoryId in enumerate(historyIdList): logger.info("===[%d] eachHistoryId=%s", curHisotryIdIdx, eachHistoryId) history = History.objects.get(pk=eachHistoryId) logger.info("history=%s", history) orderedScriptAllHistory = history.script_history.all().order_by('version') logger.info("orderedScriptAllHistory=%s", orderedScriptAllHistory) lastHistory = orderedScriptAllHistory.last() logger.info("lastHistory=%s", lastHistory) result.append(lastHistory.id) logger.info("result=%s", result) resultLen = len(result) logger.info("resultLen=%s", resultLen) |
耗时大概:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | ...INFO|20180810 23:03:04|views:list:170|===[517] eachHistoryId=c0d1140d-5043-44f4-a1c7-7486f1b0639cDEBUG|20180810 23:03:04|utils:execute:111|(0.000) SELECT `script_history`.`created_at`, `script_history`.`updated_at`, `script_history`.`id` FROM `script_history` WHERE `script_history`.`id` = 'c0d1140d504344f4a1c77486f1b0639c'; args=('c0d1140d504344f4a1c77486f1b0639c',)INFO|20180810 23:03:04|views:list:172|history=History object (c0d1140d-5043-44f4-a1c7-7486f1b0639c)DEBUG|20180810 23:03:04|utils:execute:111|(0.000) SELECT `script_script`.`created_at`, `script_script`.`updated_at`, `script_script`.`id`, `script_script`.`place`, `script_script`.`title`, `script_script`.`topic_id`, `script_script`.`second_level_topic_id`, `script_script`.`age_start`, `script_script`.`age_end`, `script_script`.`version`, `script_script`.`publish_status`, `script_script`.`edit_status`, `script_script`.`review_id`, `script_script`.`history_id`, `script_script`.`author_id` FROM `script_script` WHERE `script_script`.`history_id` = 'c0d1140d504344f4a1c77486f1b0639c' ORDER BY `script_script`.`version` ASC LIMIT 21; args=('c0d1140d504344f4a1c77486f1b0639c',)INFO|20180810 23:03:04|views:list:174|orderedScriptAllHistory=<QuerySet [<Script: cooking the salad>]>DEBUG|20180810 23:03:04|utils:execute:111|(0.000) SELECT `script_script`.`created_at`, `script_script`.`updated_at`, `script_script`.`id`, `script_script`.`place`, `script_script`.`title`, `script_script`.`topic_id`, `script_script`.`second_level_topic_id`, `script_script`.`age_start`, `script_script`.`age_end`, `script_script`.`version`, `script_script`.`publish_status`, `script_script`.`edit_status`, `script_script`.`review_id`, `script_script`.`history_id`, `script_script`.`author_id` FROM `script_script` WHERE `script_script`.`history_id` = 'c0d1140d504344f4a1c77486f1b0639c' ORDER BY `script_script`.`version` DESC LIMIT 1; args=('c0d1140d504344f4a1c77486f1b0639c',)INFO|20180810 23:03:04|views:list:176|lastHistory=cooking the saladINFO|20180810 23:03:04|views:list:170|===[518] eachHistoryId=8337f985-d113-473f-9bd3-2312c6dc1726DEBUG|20180810 23:03:04|utils:execute:111|(0.000) SELECT `script_history`.`created_at`, `script_history`.`updated_at`, `script_history`.`id` FROM `script_history` WHERE `script_history`.`id` = '8337f985d113473f9bd32312c6dc1726'; args=('8337f985d113473f9bd32312c6dc1726',)INFO|20180810 23:03:04|views:list:172|history=History object (8337f985-d113-473f-9bd3-2312c6dc1726)DEBUG|20180810 23:03:04|utils:execute:111|(0.001) SELECT `script_script`.`created_at`, `script_script`.`updated_at`, `script_script`.`id`, `script_script`.`place`, `script_script`.`title`, `script_script`.`topic_id`, `script_script`.`second_level_topic_id`, `script_script`.`age_start`, `script_script`.`age_end`, `script_script`.`version`, `script_script`.`publish_status`, `script_script`.`edit_status`, `script_script`.`review_id`, `script_script`.`history_id`, `script_script`.`author_id` FROM `script_script` WHERE `script_script`.`history_id` = '8337f985d113473f9bd32312c6dc1726' ORDER BY `script_script`.`version` ASC LIMIT 21; args=('8337f985d113473f9bd32312c6dc1726',)INFO|20180810 23:03:04|views:list:174|orderedScriptAllHistory=<QuerySet [<Script: xxx>]>DEBUG|20180810 23:03:04|utils:execute:111|(0.000) SELECT `script_script`.`created_at`, `script_script`.`updated_at`, `script_script`.`id`, `script_script`.`place`, `script_script`.`title`, `script_script`.`topic_id`, `script_script`.`second_level_topic_id`, `script_script`.`age_start`, `script_script`.`age_end`, `script_script`.`version`, `script_script`.`publish_status`, `script_script`.`edit_status`, `script_script`.`review_id`, `script_script`.`history_id`, `script_script`.`author_id` FROM `script_script` WHERE `script_script`.`history_id` = '8337f985d113473f9bd32312c6dc1726' ORDER BY `script_script`.`version` DESC LIMIT 1; args=('8337f985d113473f9bd32312c6dc1726',)INFO|20180810 23:03:04|views:list:176|lastHistory=xxxINFO|20180810 23:03:04|views:list:179|result=[UUID('cb54d47d-6e9c-4ec2-8666-eb97df30e654'),...INFO|20180810 23:03:04|views:list:181|resultLen=519 |
(2)序列化耗费了大概5秒 到了23:03:09
1 2 3 4 | serializer = ScriptSerializer(queryset, many=True)logger.info("after ScriptSerializer serializer=%s", serializer)serializedData = serializer.datalogger.info("serializedData=%s", serializedData) |
输出:
1 2 3 4 5 6 7 | DEBUG|20180810 23:03:09|utils:execute:111|(0.000) SELECT `user_user`.`password`, `user_user`.`last_login`, `user_user`.`is_superuser`, `user_user`.`username`, `user_user`.`first_name`, `user_user`.`last_name`, `user_user`.`email`, `user_user`.`is_staff`, `user_user`.`date_joined`, `user_user`.`id`, `user_user`.`is_active`, `user_user`.`name`, `user_user`.`mobile_phone_number` FROM `user_user` WHERE `user_user`.`id` = '7e8832bcc02d4befa303ed9488fb654a'; args=('7e8832bcc02d4befa303ed9488fb654a',)INFO|20180810 23:03:09|serializers:to_representation:25|ScriptFuctionGroup to_representation: self=ScriptFuctionGroup(source='author'), value=username=xxx,id=7e8832bc-c02d-4bef-a303-ed9488fb654a,is_superuser=FalseINFO|20180810 23:03:09|serializers:to_representation:28|curUser=username=xxx,id=7e8832bc-c02d-4bef-a303-ed9488fb654a,is_superuser=FalseDEBUG|20180810 23:03:09|utils:execute:111|(0.000) SELECT `user_functiongroup`.`id`, `user_functiongroup`.`created_at`, `user_functiongroup`.`updated_at`, `user_functiongroup`.`owner_id`, `user_functiongroup`.`name`, `user_functiongroup`.`function`, `user_functiongroup`.`description` FROM `user_functiongroup` INNER JOIN `user_functiongroup_members` ON (`user_functiongroup`.`id` = `user_functiongroup_members`.`functiongroup_id`) WHERE (`user_functiongroup`.`function` = '1' AND `user_functiongroup_members`.`user_id` = '7e8832bcc02d4befa303ed9488fb654a'); args=('1', '7e8832bcc02d4befa303ed9488fb654a')INFO|20180810 23:03:09|serializers:to_representation:31|joinedScriptGroup=script_function_groupDEBUG|20180810 23:03:09|utils:execute:111|(0.000) SELECT COUNT(*) AS `__count` FROM `script_dialog` WHERE `script_dialog`.`script_id` = '9215ab9492f34e3b8f02677743e05e3b'; args=('9215ab9492f34e3b8f02677743e05e3b',)INFO|20180810 23:03:09|views:list:191|serializedData=[OrderedDict([('id', |
所以结论是:
代码中业务逻辑有点复杂,加上原先设计的不够好,导致此处 检索4秒+序列化5秒,加起来需要9秒左右才返回到前端 -》 误以为前端有问题呢。
所以接下来,就是去优化业务逻辑和设计,以便于减少代码时间。
其中可以做的是,现在的序列化是针对所有的数据的,
应该改为:只针对于需要返回的那些数据即可。
以及,再去想办法通过优化提升速度:
根据已有业务逻辑,在不大动干戈改动数据库的情况下(因为直接给Script增加,去优化减少查询数据库,最后代码优化改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 | from django.conf import settingsfrom rest_framework.response import Responsefrom django.core.paginator import Paginatorclass ScriptViewSet(mixins.ListModelMixin, mixins.CreateModelMixin, mixins.RetrieveModelMixin, PutOnlyUpdateModelMixin, mixins.DestroyModelMixin, viewsets.GenericViewSet): queryset = Script.objects.all() serializer_class = ScriptSerializer permission_classes = (IsAuthenticated, IsUserScriptFunctionGroup)... def list(self, request, *args, **kwargs): ... # filterByUserScriptList = Script.objects.filter(userFilter) # Note: here order by created time to let new created show first # -> make it easy for later will got latest version script via filter by history id filterByUserScriptList = Script.objects.filter(userFilter).order_by('-created_at') logger.info("filterByUserScriptList=%s", filterByUserScriptList) filterByUserScriptListLen = len(filterByUserScriptList) logger.info("filterByUserScriptListLen=%s", filterByUserScriptListLen) filter_condition = self.generateQueryFilterCondiction(request) logger.info("filter_condition=%s", filter_condition) resultScriptIdList = [] latestVersionDict = {} # store history_id : latest_version_script # uniqueHistoryIdList = [] for curScriptIdx, singleScript in enumerate(filterByUserScriptList): logger.info("---[%d] singleScript=%s", curScriptIdx, singleScript) scriptHistoryId = singleScript.history_id logger.info("scriptHistoryId=%s", scriptHistoryId) # if scriptHistoryId not in uniqueHistoryIdList: if scriptHistoryId not in latestVersionDict.keys(): # uniqueHistoryIdList.append(singleScript.history_id) # latestVersionScriptList.append(singleScript) latestVersionDict[scriptHistoryId] = singleScript else: # logger.debug("filter out [%d] script: %s", curScriptIdx, singleScript) logger.debug("Check is latest version or not for: [%d] singleScript=%s", curScriptIdx, singleScript) prevStoredScript = latestVersionDict[scriptHistoryId] logger.debug("prevStoredScript=%s", prevStoredScript) prevStoredScriptVersion = prevStoredScript.version curScriptVersion = singleScript.version logger.debug("prevStoredScriptVersion=%d, curScriptVersion=%d", prevStoredScriptVersion, curScriptVersion) if (curScriptVersion > prevStoredScriptVersion): latestVersionDict[scriptHistoryId] = singleScript else: logger.debug("omit older version script: %s", singleScript) # generate result script id list for eachHistoryId in latestVersionDict.keys(): logger.debug("eachHistoryId=%s", eachHistoryId) eachScript = latestVersionDict[eachHistoryId] logger.debug("eachScript=%s", eachScript) resultScriptIdList.append(eachScript.id) # logger.info("uniqueHistoryIdList=%s", uniqueHistoryIdList) # uniqueHistoryIdListLen = len(uniqueHistoryIdList) # logger.info("uniqueHistoryIdListLen=%s", uniqueHistoryIdListLen) # for curHisotryIdIdx, eachHistoryId in enumerate(uniqueHistoryIdList): # logger.info("===[%d] eachHistoryId=%s", curHisotryIdIdx, eachHistoryId) # history = History.objects.get(pk=eachHistoryId) # logger.info("history=%s", history) # orderedScriptAllHistory = history.script_history.all().order_by('version') # logger.info("orderedScriptAllHistory=%s", orderedScriptAllHistory) # lastHistory = orderedScriptAllHistory.last() # logger.info("lastHistory=%s", lastHistory) # resultScriptIdList.append(lastHistory.id) logger.info("resultScriptIdList=%s", resultScriptIdList) resultScriptIdListLen = len(resultScriptIdList) logger.info("resultScriptIdListLen=%s", resultScriptIdListLen) allScriptList = Script.objects.filter(pk__in=resultScriptIdList).filter(filter_condition).order_by('-created_at') logger.info("allScriptList=%s", allScriptList) # paginatedQueryset = self.paginate_queryset(allScriptList) # logger.info("paginatedQueryset=%s", paginatedQueryset) # serializer = ScriptSerializer(allScriptList, many=True) # logger.info("after ScriptSerializer serializer=%s", serializer) # serializedData = serializer.data # logger.info("serializedData=%s", serializedData) # respDict = None # if paginatedQueryset is not None: # respDict = self.get_paginated_response(serializedData) # # respDict = self.get_paginated_response(serializedData, page) # else: # respDict = Response(serializedData) # logger.info("respDict=%s", respDict) # return respDict # curPaginator = Paginator(serializedData, page_size) curPaginator = Paginator(allScriptList, page_size) logger.info("curPaginator=%s", curPaginator) totalCount = curPaginator.count logger.info("totalCount=%s", totalCount) maxPageCount = curPaginator.num_pages logger.info("maxPageCount=%s", maxPageCount) curPageNum = page logger.info("curPageNum=%s", curPageNum) curPage = curPaginator.page(curPageNum) logger.info("curPage=%s", curPage) logger.info("type(curPage)=%s", type(curPage)) curPageItemList = curPage.object_list logger.info("curPageItemList=%s", curPageItemList) curPageSerializer = ScriptSerializer(curPageItemList, many=True) logger.info("curPageSerializer=%s", curPageSerializer) curPageSerializedData = curPageSerializer.data logger.info("curPageSerializedData=%s", curPageSerializedData) # currentPageCount = len(curPageItemList) currentPageCount = len(curPageSerializedData) logger.info("currentPageCount=%s", currentPageCount) # nextPageUrl = self.get_next_link() # previousPageUrl = self.get_previous_link() nextPageUrl = None previousPageUrl = None respDict = { "totalCount": totalCount, "maxPageCount": maxPageCount, "pageSize": page_size, "currentPageNumber": curPageNum, "currentPageCount": currentPageCount, "next": nextPageUrl, "previous": previousPageUrl, # "results": curPageItemList, "results": curPageSerializedData, } return Response(respDict, status=status.HTTP_200_OK) |
从而把之前的耗时9秒左右(4秒的查询script的hisotry + 5秒的所有页面数据的序列化serialize)的操作,优化不到1秒:
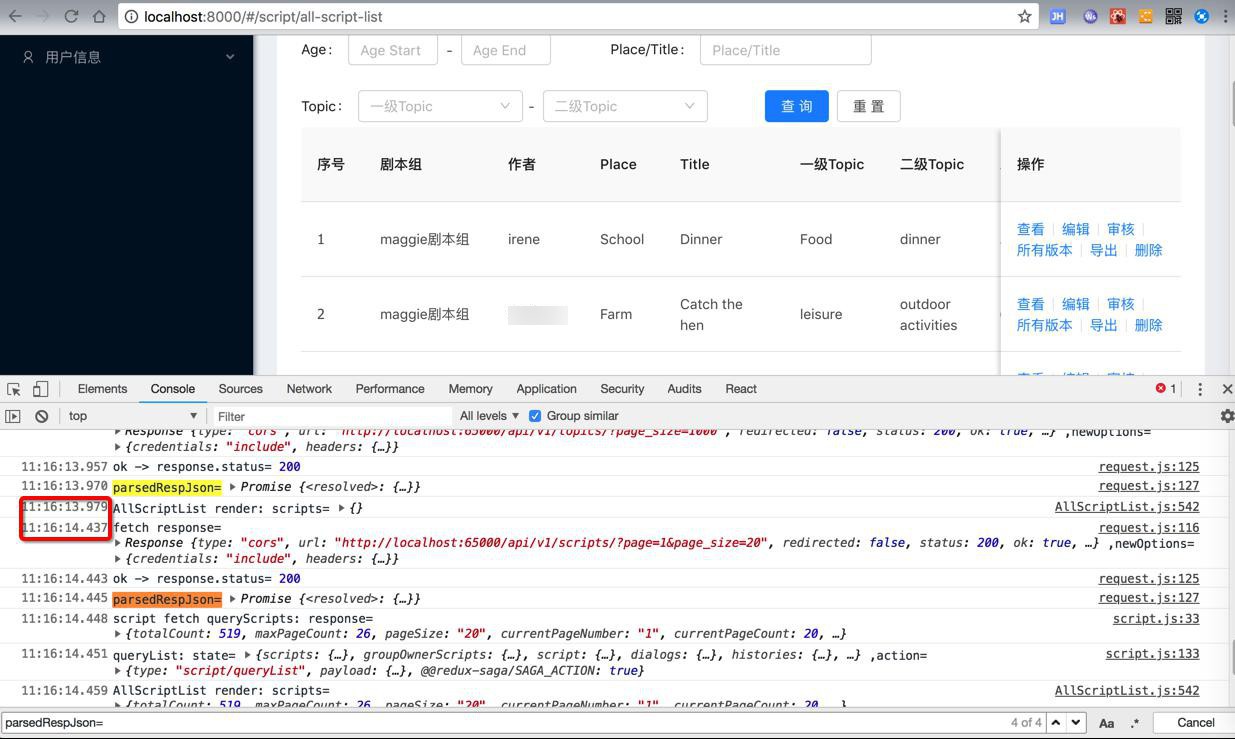
【后记】
后来看到:
聊聊python的轻量级orm peewee及对比SQLAlchemy | 峰云就她了
http://xiaorui.cc/2015/10/09/聊聊python的轻量级orm-peewee及对比sqlalchemy/
-》
话说Django orm性能为什么比原生的mysqldb慢 | 峰云就她了
http://xiaorui.cc/2015/09/24/话说django-orm模型为什么比原生的mysqldb慢/
其中遇到Django的ORM性能慢的现象:
感觉和此处很类似:
上面的Script的History的之前代码,也是通过Django的ORM去跨表查询的:
1 2 3 | history = History.objects.get(pk=eachHistoryId)orderedScriptAllHistory = history.script_history.all().order_by('version')lastHistory = orderedScriptAllHistory.last() |
500多条Script,通过script_history的外键去查询所有符合条件的内容,再去找到last最新的一条
也是查询很慢:大概要花4秒左右
而自己当时的优化是通过逻辑上避免了这个额外的查询。
看来如果以后会有机会,借鉴其所说的:
“直接走原生的mysql sql语句,在python下你的选择 mysqldb,也可以用django的connection。推荐用connection,因为大家的db地址配置都是放在settings.config里面的。”
即:也是可以通过直接转换为内部的SQL查询语句,直接查询,提升性能的。
转载请注明:在路上 » 【已解决】Antd Pro中前端列表页面loading加载很慢