【代码分享】Python代码:scrape_chaosgroup_contact(Python 2.x版本和Python 3.x版本) – 抓取chaosgroup.com中的联系人信息保存为excel
11年前 (2013-09-23) 2861浏览 0评论
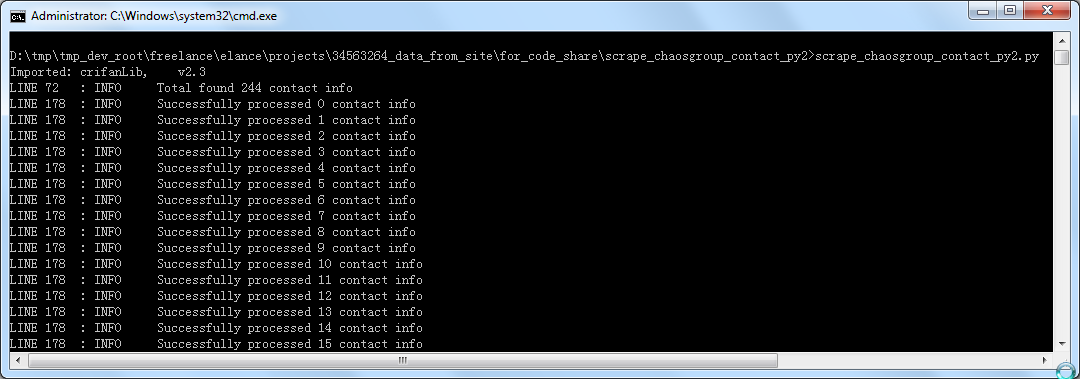
背景】 之前写的,前后共写了两个版本的: Python 2.x版本 和 Python 3.x版本 去抓取 http://www.chaosgroup.com/ 中联系人信息,并保存为excel文件 【scrape_ch...
11年前 (2013-09-23) 2861浏览 0评论
背景】 之前写的,前后共写了两个版本的: Python 2.x版本 和 Python 3.x版本 去抓取 http://www.chaosgroup.com/ 中联系人信息,并保存为excel文件 【scrape_ch...
11年前 (2013-09-23) 2517浏览 0评论
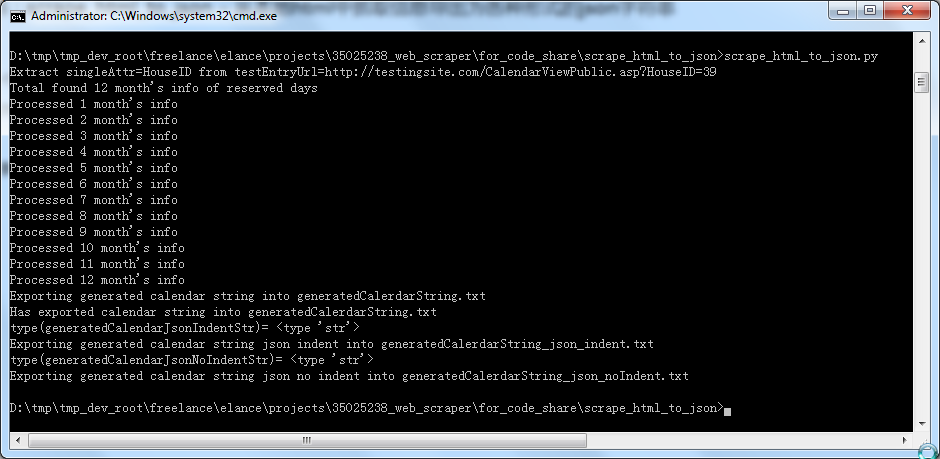
背景】 之前写的,去处理本地已有的一个html文件, 然后对于提取出来的信息,导出为,各种形式的json字符串。 【scrape_html_to_json代码分享】 1.截图: (1)运行效果: (2)输出的各种json字符...
11年前 (2013-09-23) 2955浏览 0评论
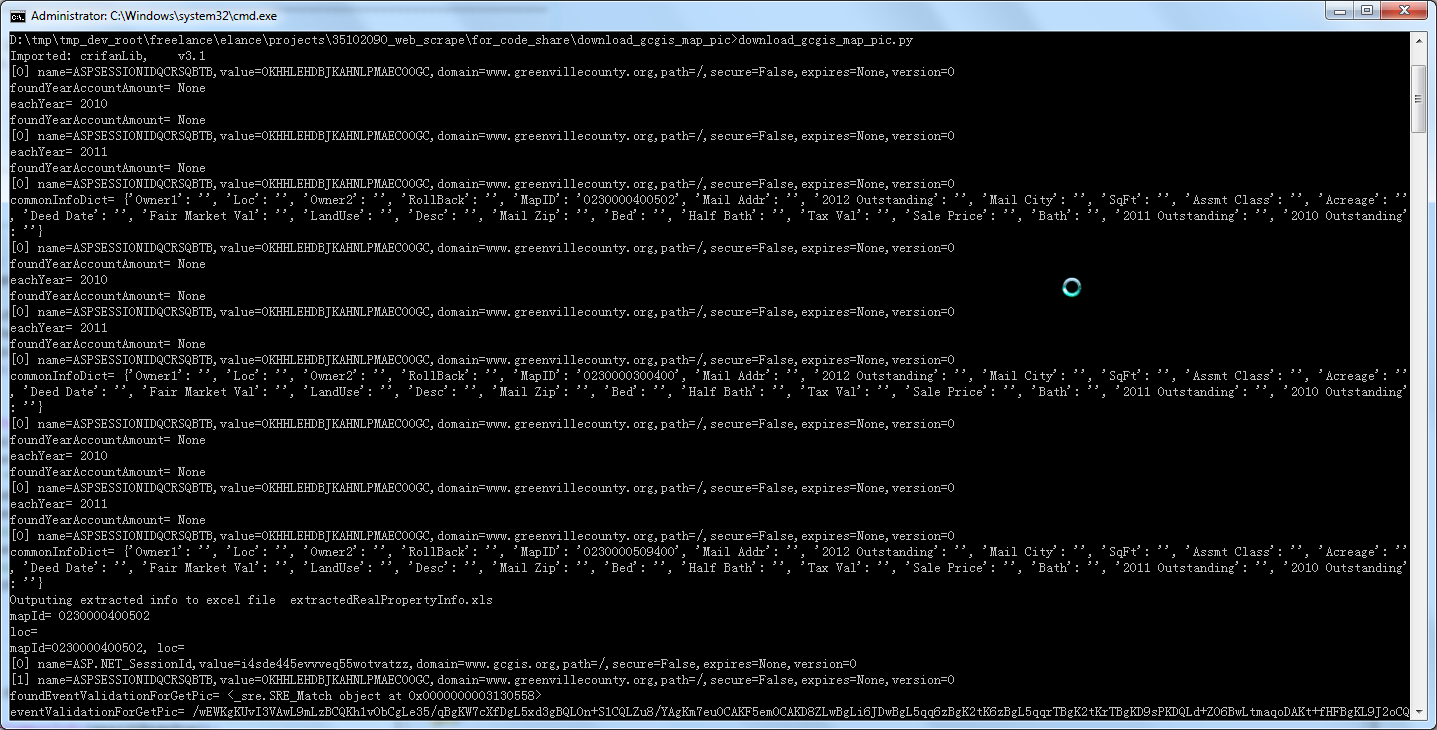
【背景】 之前写的,去处理: http://www.gcgis.org/webmappub/titleWF.aspx http://www.greenvillecounty.org/vrealpr24/clRealProp.ASP?WCI=tp...

11年前 (2013-09-23) 2253浏览 0评论
【背景】 之前写的,去模拟: http://www.menupix.com 然后获得返回的jsonp字符串。 【scrape_menupix_com代码分享】 1.截图: (1)运行效果: 返回的jsonp示例: jsonp...
11年前 (2013-09-23) 2856浏览 0评论
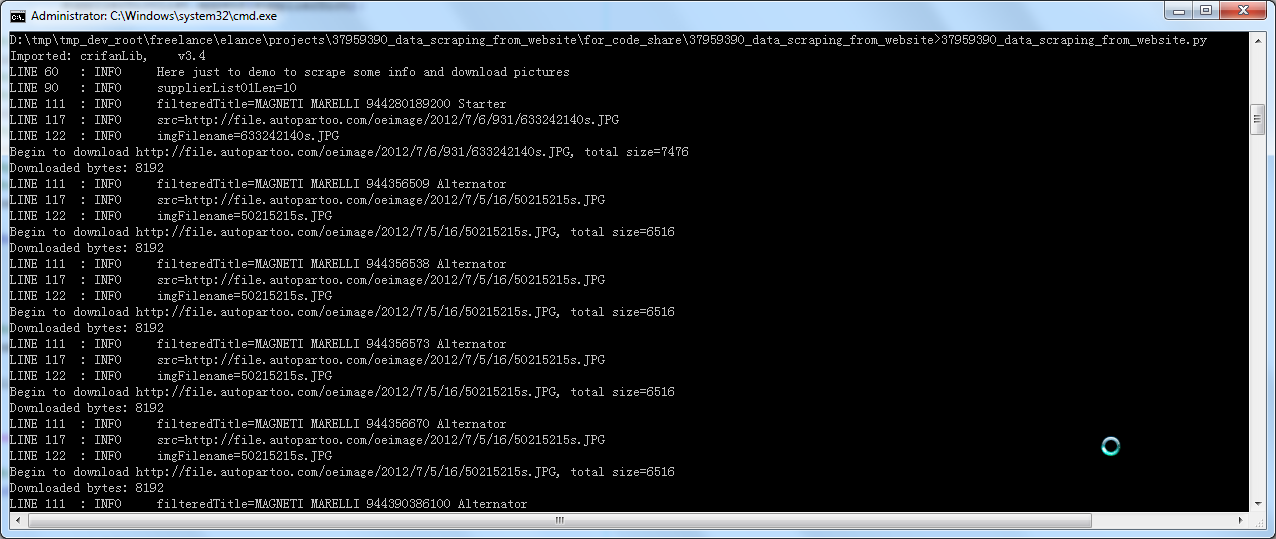
【背景】 之前写的,去下载: http://www.autopartoo.com 中的图片,并且保存图片信息为csv文件。 【37959390_data_scraping_from_website代码分享】 1.截图: (1...
11年前 (2013-09-23) 1984浏览 0评论
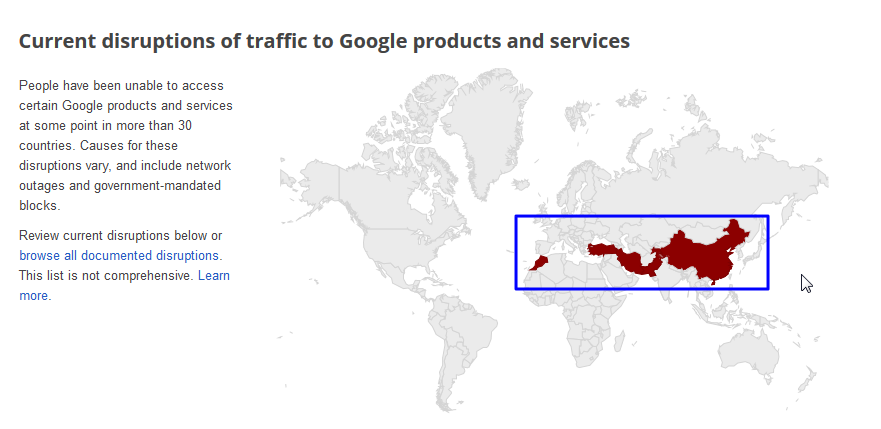
之前无意间发现, 关于google,其提供了各种服务 当然最常用的就是google搜索, 而这些服务,对于有些国家或地区, 出于各种原因而无法访问 比如天朝的长城,你懂的 其他有些还有因为某人在网上骂该某某,而被政府看着不爽,而禁了google的(当...
11年前 (2013-09-23) 1822浏览 0评论
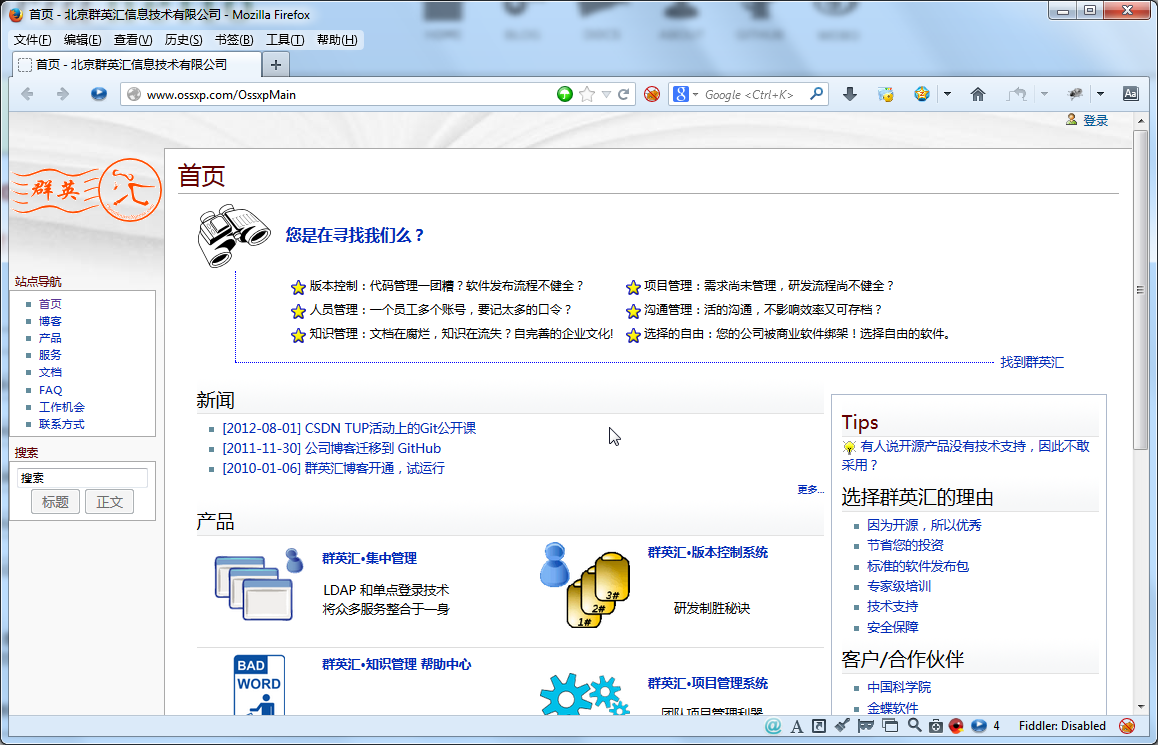
【背景】 之前折腾docbook时,就看过此篇文章: DocBook 助你完成传世之作 之后,又看到过,该文章,只是worldhello: http://www.worldhello.net/doc/ 中的其中一个。 【技术趣闻】 之后,无意间发现,...
11年前 (2013-09-22) 2271浏览 0评论
【背景】 之前写了很多docbook。 已发布至: https://www.crifan.com/files/doc/docbook/ 现在,想要: 如果可以实现,把现有的docbook 即一堆的xml(和相关的xls和其他配置) 转换为wiki格式的...
11年前 (2013-09-22) 5345浏览 3评论
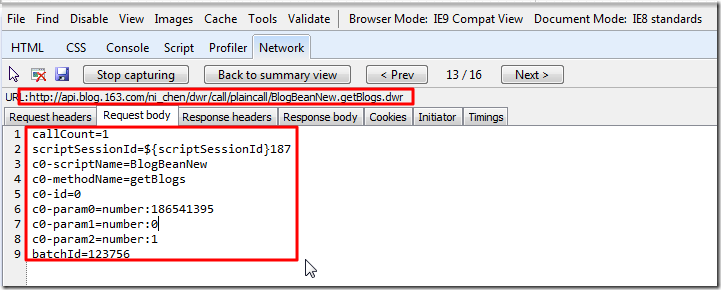
【背景】 之前的 BlogsToWordpress 不支持网易的心情随笔。 现在去添加此功能。 【解决过程】 1.结果使用: BlogsToWordpress.py -s http://blog.163.com/ni_chen 竟然结果连...
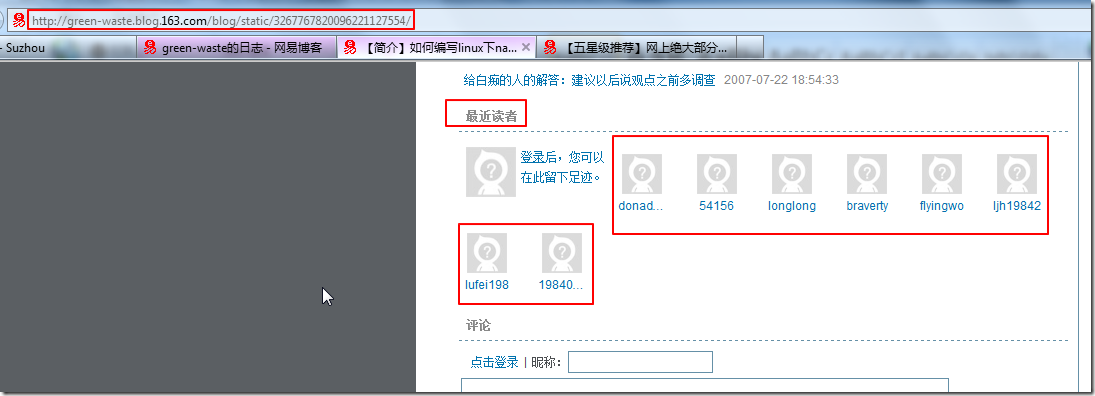
11年前 (2013-09-22) 9520浏览 9评论
背景 前面已经通过: 【教程】如何抓取动态网页内容 介绍了,关于抓取动态网页中的内容的逻辑过程。 下面通过具体的例子,来说明是如何实现此过程的。 前提知识 1.了解网页抓取等的基本背景知识 不了解的去参考: 【整理】关于抓取网页,分析网页内容,模拟登...