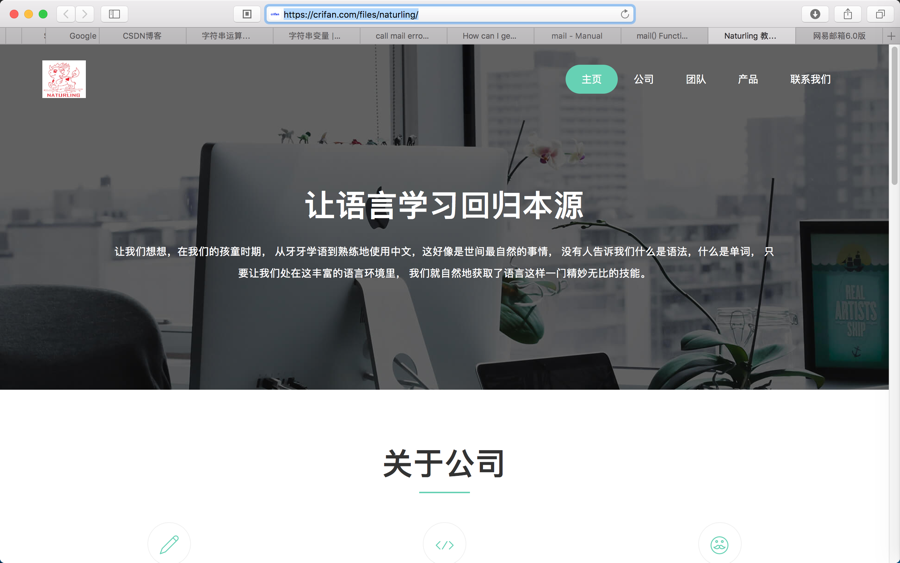
【记录】基于Html5模版搭建公司主页官网
crifan 7年前 (2018-03-08) 2581浏览 0评论
已经通过: 【整理】用什么技术实现公司网站官网首页H5页面 去找到了大概几个可以用来弄公司网站 官网 主页的html模版 H5模版了 现在就可以去弄试试了。 暂定去用: Mate – Parallax Website Template 去...
工作相关的技术文章
crifan 7年前 (2018-03-08) 2581浏览 0评论
已经通过: 【整理】用什么技术实现公司网站官网首页H5页面 去找到了大概几个可以用来弄公司网站 官网 主页的html模版 H5模版了 现在就可以去弄试试了。 暂定去用: Mate – Parallax Website Template 去...
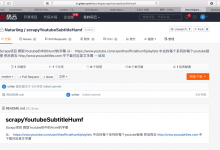
crifan 7年前 (2018-03-07) 13819浏览 0评论
背景是: 在gitee上已经新建了git的repo: 但是创建了一个README.md 而本地是用 git init git add git commit 然后去: ➜ youtubeSubtitle git:(master) ✗ git pus...
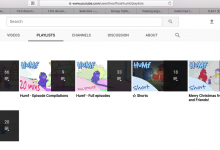
crifan 7年前 (2018-03-07) 5596浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,发现个问题: 对于原始的页面中的多个分组的内容: 结果最后抓取的内容,缺了很多: 比如: ☆ Shorts 中,本来有18个,但是实际上只爬取了8个: 缺了1...
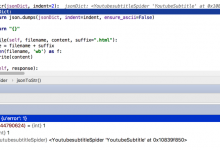
crifan 7年前 (2018-03-07) 8965浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,用代码: <code>class YoutubesubtitleSpider(scrapy.Spider): def jsonToStr(jso...
crifan 7年前 (2018-03-07) 4447浏览 0评论
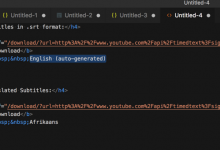
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,虽然已经用代码: <code># -*- coding: utf-8 -*- import scrapy # from scrapy import R...
crifan 7年前 (2018-03-06) 3014浏览 0评论
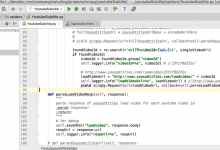
折腾: 【已解决】Scrapy的Python中如何解析部分的html字符串并格式化为html网页源码 期间, 对于: <code><h4>Subtitles in .srt format:</h4...
crifan 7年前 (2018-03-05) 4374浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了: {“id”:1637788,”title&#...
crifan 7年前 (2018-03-04) 2997浏览 0评论
之前已经实现了日期的选择,但是此处需要选择年月日时分秒: 所以去找找,Preact,或react js中的相关控件 react datetime picker YouCanBookMe/react-datetime: A lightweight b...
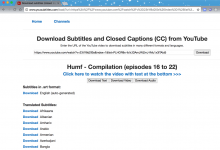
crifan 7年前 (2018-03-02) 3783浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间, 已经可以去用scrapy打开页面: http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtub...
crifan 7年前 (2018-03-01) 3641浏览 0评论
git 创建分支并提交 leonardyp.github.io/git/git-创建分支并提交到远程/ Git 本地创建分支并提交远程分支 – 简书 git提交本地分支到远程分支 – springbarley –...