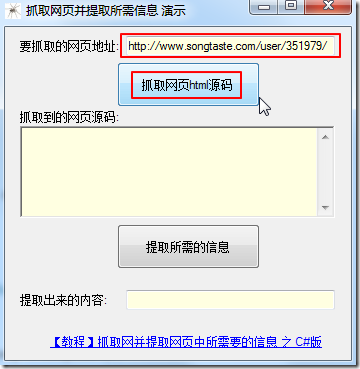
【教程】抓取网并提取网页中所需要的信息 之 C#版
crifan 13年前 (2012-11-23) 16190浏览 17评论
在通过: 【整理】关于抓取网页,分析网页内容,模拟登陆网站的逻辑/流程和注意事项 了解了抓取网页的一般流程之后,加上之前介绍的: 【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器 应该就...
all programming language, C/C++/C#/VB/VBA/VB.NET/Python/Ruby/PHP/Go/Perl/……
crifan 13年前 (2012-11-23) 16190浏览 17评论
在通过: 【整理】关于抓取网页,分析网页内容,模拟登陆网站的逻辑/流程和注意事项 了解了抓取网页的一般流程之后,加上之前介绍的: 【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器 应该就...

crifan 13年前 (2012-11-23) 19456浏览 22评论
在通过: 【整理】关于抓取网页,分析网页内容,模拟登陆网站的逻辑/流程和注意事项 了解了抓取网页的一般流程之后,加上之前介绍的: 【总结】浏览器中的开发人员工具(IE9的F12和Chrome的Ctrl+Shift+I)-网页分析的利器 应该就很清楚如...
crifan 13年前 (2012-11-23) 9398浏览 5评论
【BeautifulSoup最简介】 BeautifulSoup,是Python中的一个第三方库,用于帮助解析Html/XML等内容,便于实现后期的内容提取等方面的工作。 BeautifulSoup官网地址:http://www.crummy.com...
crifan 13年前 (2012-11-22) 2859浏览 0评论
声明: 1.本文不再更新。 2.本人内容,已合并到: 【总结】Python中常见字符编码和解码方面的错误及其解决办法 新帖子总结的更加全面,并且分析了原因,和总结了解决办法,还给出了示例代码。 3.这方面的内容,如有更新,也只会更新到上述新帖子中。 ...
crifan 13年前 (2012-11-21) 11050浏览 0评论
【背景】 之前就遇到过,现在又有人问这个问题,所以就总结一下: 类似于: \u3232\u6674 的字符串,转换为对应的unicode字符。 【解决过程】 对应的,可以通过Python的decode函数去解码,其中自定原始字符串位unicode-e...
crifan 13年前 (2012-11-19) 53075浏览 3评论
都差点忘了说了,在看下面所有的内容之前,对于python版本不了解的,请一定先看看这个: 【整理】总结Python2(Python 2.x版本)和Python3(Python 3.x版本)之间的区别 然后根据情况,选择自己需要的python版本,然...
crifan 13年前 (2012-11-19) 6181浏览 0评论
已经听说了,Python 3.x,对于文件的编码,支持的很好了,很多时候都可以自动检测,并正确存储为unicode字符串了。 并且在windows 的cmd中,也都可以正常输出显示,不会出现编码错误了。 所以,对此部分,特意去测试一下,通过代码,得到...
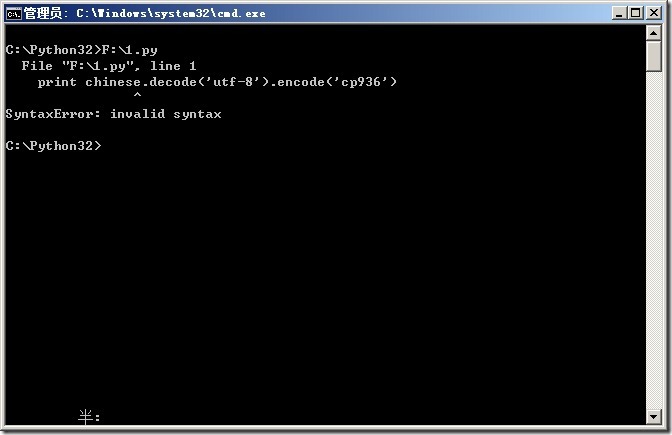
crifan 13年前 (2012-11-19) 13932浏览 1评论
【现象】 很多Python初学者,在安装了最新版本的Python 3.x版本,比如Python 3.2之后, 去参考别人的代码(基于Python 2.x写的教程),去利用print函数,打印输出内容时,结果却遇到print函数的语法错误: Synta...
crifan 13年前 (2012-11-19) 14204浏览 5评论
首先要说的是,Python的版本,目前主要分为两大类: Python 2.x的版本的,被称为Python2:是目前用的最广泛的,比如Python 2.7.3。 Python 3.x的版本的,被称为Python3:是最新的版本的,比如Python 3....
crifan 13年前 (2012-11-19) 5231浏览 0评论
【问题】 有人遇到类似问题: python,用: rs=open(‘filename’,‘w') 打开文件后,然后写入一定量的数据,再去关闭: rs.close() sleep(5) 但是问题在于,每次写入文件的数据,是不固定的,所以,不知道slee...