【记录】爬取CHILDES中的字幕和音视频文件
crifan 7年前 (2018-03-22) 2080浏览 0评论
根据需求,需要去爬取: Eng-NA Corpora Bilingual Corpora 中,对应的内容的: 字幕,去掉各种标注的 音频,如果有 视频,如果有 参考之前自己的: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕...
crifan 7年前 (2018-03-22) 2080浏览 0评论
根据需求,需要去爬取: Eng-NA Corpora Bilingual Corpora 中,对应的内容的: 字幕,去掉各种标注的 音频,如果有 视频,如果有 参考之前自己的: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕...
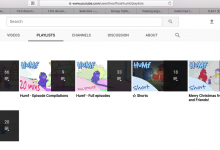
crifan 7年前 (2018-03-07) 5702浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,发现个问题: 对于原始的页面中的多个分组的内容: 结果最后抓取的内容,缺了很多: 比如: ☆ Shorts 中,本来有18个,但是实际上只爬取了8个: 缺了1...
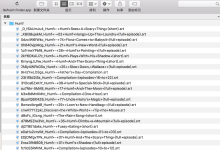
crifan 7年前 (2018-03-07) 4558浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,虽然已经用代码: <code># -*- coding: utf-8 -*- import scrapy # from scrapy import R...
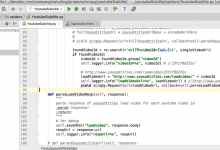
crifan 7年前 (2018-03-05) 4477浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,已经可以用scrapy去post某个url得到返回的部分的html的字符串了: {“id”:1637788,”title&#...
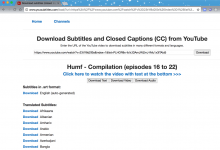
crifan 7年前 (2018-03-02) 3888浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间, 已经可以去用scrapy打开页面: http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtub...
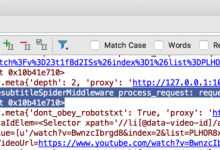
crifan 7年前 (2018-03-01) 5866浏览 0评论
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,去调用 http://www.yousubtitles.com 想办法下载字幕,结果无法提示: DEBUG: Forbidden by robots.txt 20...
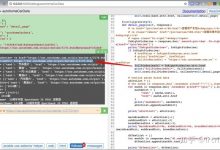
crifan 7年前 (2018-02-27) 6444浏览 0评论
pyspider vs scrapy pyspider 和 scrapy 比较起来有什么优缺点吗? – 知乎 “Pyspiders是国内某大神开发了个WebUI的[Pyspider](GitHub – binux/pyspid...
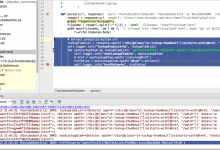
crifan 7年前 (2018-01-13) 5980浏览 0评论
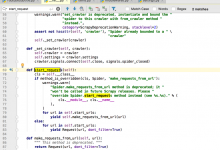
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,对于scrapy的response的xpath得到的Selector,如何获取其中的a中href的值 Scrapy 1.5 documentation — Scr...
crifan 7年前 (2018-01-13) 9784浏览 0评论
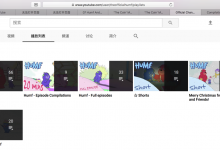
折腾: 【记录】用Python的Scrapy去爬取Youtube中Humf的字幕 期间,由于youtube网页本身需要翻墙才能打开。 而此处Mac中已有Shadowsocks-NG的ss代理了。 现在需要给Scrapy去添加代理。 scrapy ad...
crifan 7年前 (2018-01-13) 7062浏览 0评论
对于之前的手动操作去 找小毛怪 Humf 的字幕: 但是找到个好(工具)网站,支持提取youtube中视频的字幕的,具体步骤: 针对于Humf的youtube官网的每个系列: Humf – Official Channel – YouTu...