折腾:
【记录】爬虫 爬数据 义务教育教科书 义教教科书
期间,先去爬取:
义教教科书英语八年级下册
先去用Chrome去分析看看:
是否简单能找到api和请求
简单分析了下,貌似是:
第三张图片的thumb:
1 | https://bp.pep.com.cn/ebook/yybanjxc/files/thumb/3.jpg?200209175611 |
第三张图片的移动端的大图:
1 | https://bp.pep.com.cn/ebook/yybanjxc/files/mobile/3.jpg?200209175611 |
然后之后其他几张图片地址都是类似的:
1 2 3 4 5 6 | https://bp.pep.com.cn/ebook/yybanjxc/files/thumb/1.jpg?200209175611https://bp.pep.com.cn/ebook/yybanjxc/files/mobile/1.jpg?200209175611https://bp.pep.com.cn/ebook/yybanjxc/files/thumb/2.jpg?200209175611https://bp.pep.com.cn/ebook/yybanjxc/files/mobile/2.jpg?200209175611https://bp.pep.com.cn/ebook/yybanjxc/files/mobile/4.jpg?200209175611 |
然后去找找200209175611,是怎么得来的
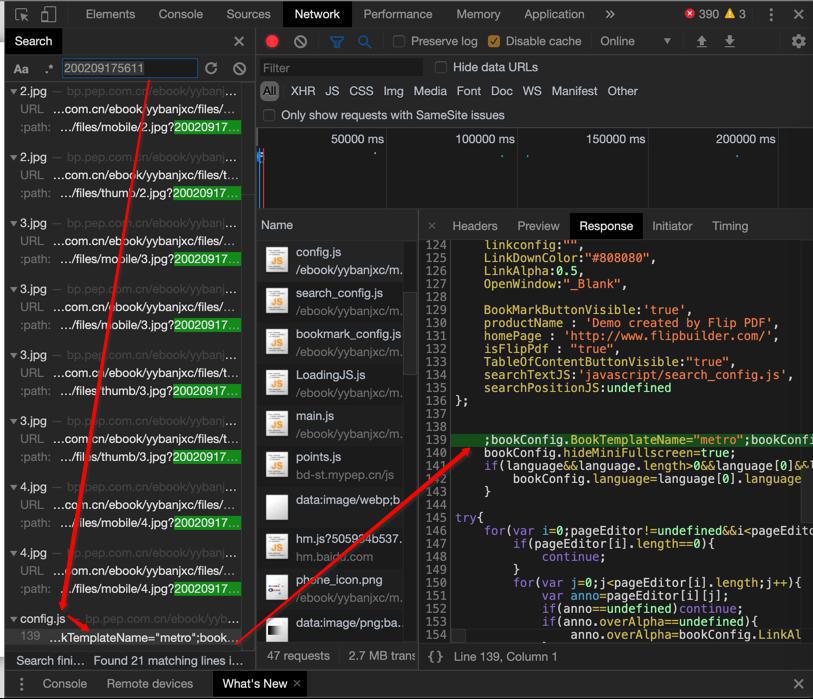
拷贝相关内容出来,放到VSCode中,搜索看看:
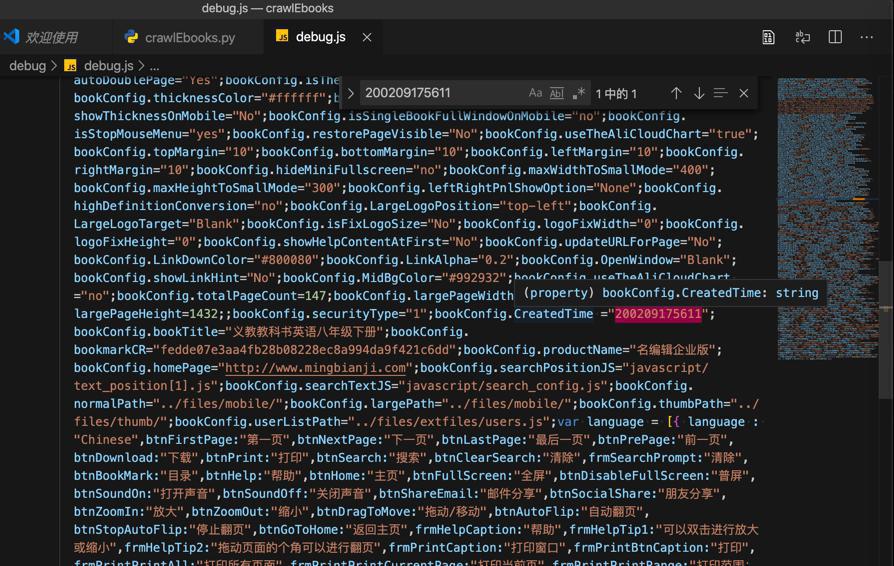
相关部分是:
1 2 3 4 5 6 7 8 | bookConfig.totalPageCount=147;bookConfig.largePageWidth=1024;bookConfig.largePageHeight=1432;;bookConfig.securityType="1";bookConfig.CreatedTime ="200209175611";bookConfig.bookTitle="义教教科书英语八年级下册";bookConfig.bookmarkCR="fedde07e3aa4fb28b08228ec8a994da9f421c6dd";bookConfig.productName="名编辑企业版"; |
去看看:
-》很明显,这个电子书就是这家公司,或相关技术制作的。
所以可以去爬取去试试了。
然后先去:
【已解决】Python的requests中如何下载二进制数据保存为图片文件
再去批量运行,也是OK的:
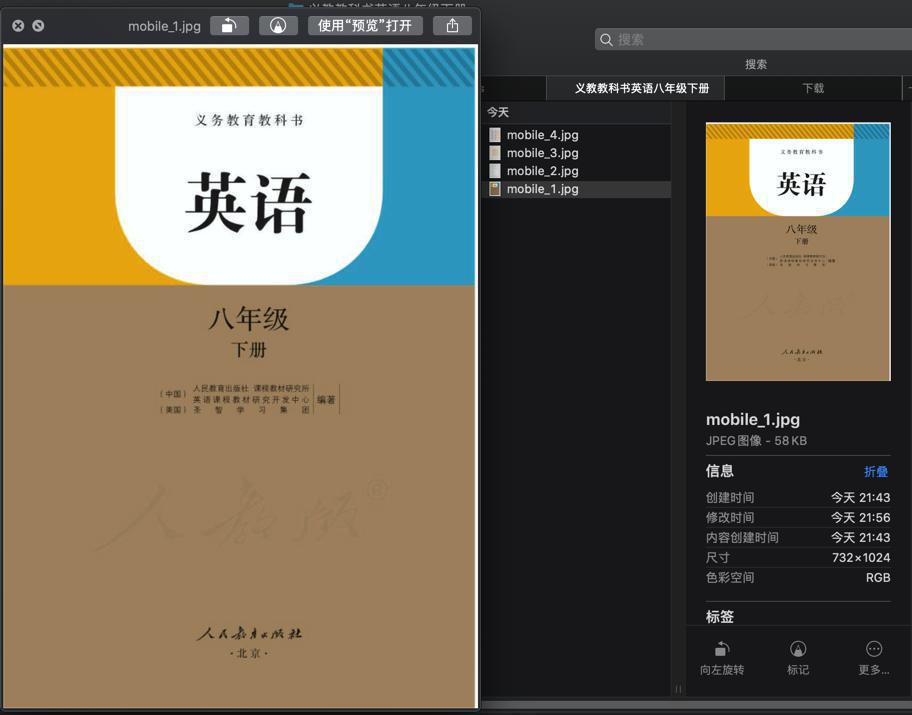
【总结】
最后完整代码是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | # 下载在线电子书:# 义教教科书英语八年级下册# 的图片# Author: Crifan Li# Update: 20200302import osimport requests# bookConfig.bookTitle="义教教科书英语八年级下册";gBookTitle = "义教教科书英语八年级下册"# bookConfig.CreatedTime ="200209175611";gCreateTimeStr = "200209175611"# bookConfig.totalPageCount=147;gTotalPageCount=147UserAgent_Mac_Chrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.122 Safari/537.36"gHeaders = { "User-Agent": UserAgent_Mac_Chrome,}gSaveFolder = os.path.join("output", gBookTitle)def createFolder(folderFullPath): """ create folder, even if already existed Note: for Python 3.2+ """ os.makedirs(folderFullPath, exist_ok=True)createFolder(gSaveFolder)for curPageIdx in range(gTotalPageCount): curPageNum = curPageIdx + 1 # curImageType = "thumb" curImageType = "mobile" curPictureUrl = "https://bp.pep.com.cn/ebook/yybanjxc/files/%s/%d.jpg?%s" % (curImageType, curPageNum, gCreateTimeStr) print("[%d] url=%s" % (curPageNum, curPictureUrl)) saveFilename = "%s_%d.jpg" % (curImageType, curPageNum) saveFullPath = os.path.join(gSaveFolder, saveFilename) resp = requests.get(curPictureUrl, headers=gHeaders) if resp.ok: with open(saveFullPath, 'wb') as saveFp: saveFp.write(resp.content) print("Saved to %s" % saveFullPath) else: print("!!! fail to open url: %s, reason: %s, status_code" % (curPictureUrl, resp.reason, resp.status_code)) |
{kind=link}
{kind=link}
{kind=link}
继续运行后,即可下载全部147张图片:
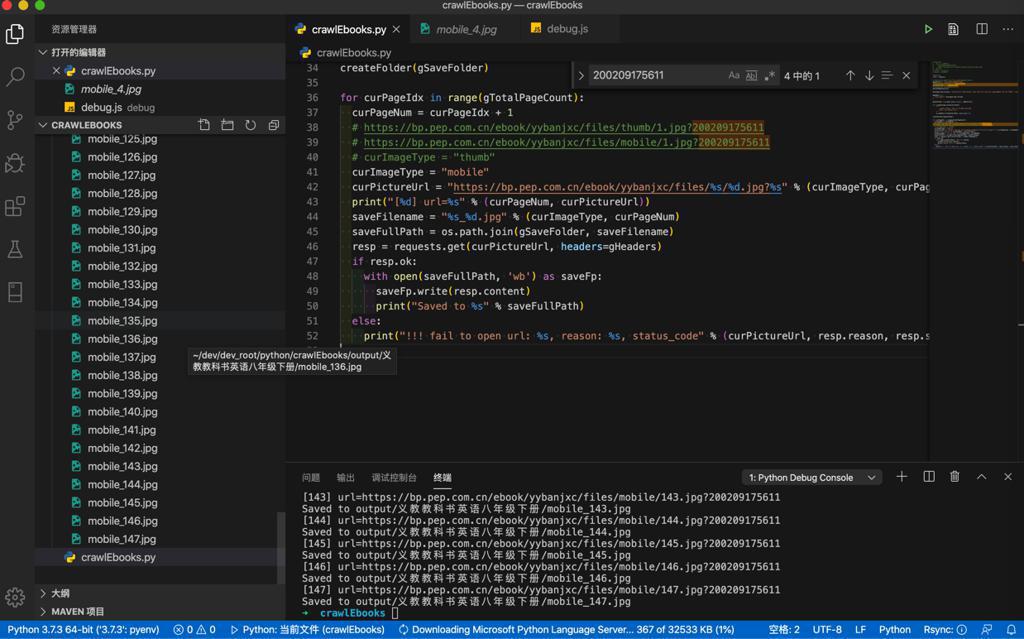
效果不错。
转载请注明:在路上 » 【已解决】爬取bp.pep.com.cn中的义务教育教科书资源