折腾:
【记录】学习tensorflow
期间,知道有个MNIST,去看看
是手写数字 handwritten digits的数据集
- 60000个用于训练
- 10000个用于测试
MNIST数据集
“MNIST 数据集已经是一个被”嚼烂”了的数据集, 很多教程都会对它”下手”, 几乎成为一个 “典范”. 不过有些人可能对它还不是很了解, 下面来介绍一下.
MNIST 数据集可在 http://yann.lecun.com/exdb/mnist/ 获取, 它包含了四个部分:
Training set images: train-images-idx3-ubyte.gz (9.9 MB, 解压后 47 MB, 包含 60,000 个样本)
Training set labels: train-labels-idx1-ubyte.gz (29 KB, 解压后 60 KB, 包含 60,000 个标签)
Test set images: t10k-images-idx3-ubyte.gz (1.6 MB, 解压后 7.8 MB, 包含 10,000 个样本)
Test set labels: t10k-labels-idx1-ubyte.gz (5KB, 解压后 10 KB, 包含 10,000 个标签)
MNIST 数据集来自美国国家标准与技术研究所, National Institute of Standards and Technology (NIST). 训练集 (training set) 由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局 (the Census Bureau) 的工作人员. 测试集(test set) 也是同样比例的手写数字数据.”
用于手写数字分类问题所要用到的(经典)MNIST数据集。
MNIST是在机器学习领域中的一个经典问题。该问题解决的是把28×28像素的灰度手写数字图片识别为相应的数字,其中数字的范围从0到9.
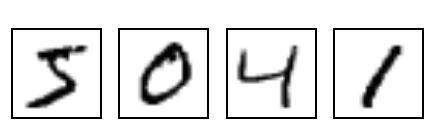
MNIST数据集是一个手写体数据集,简单说就是一堆这样东西

MNIST数据集(Mixed National Institute of Standards and Technology database)是美国国家标准与技术研究院收集整理的大型手写数字数据库,包含60,000个示例的训练集以及10,000个示例的测试集.

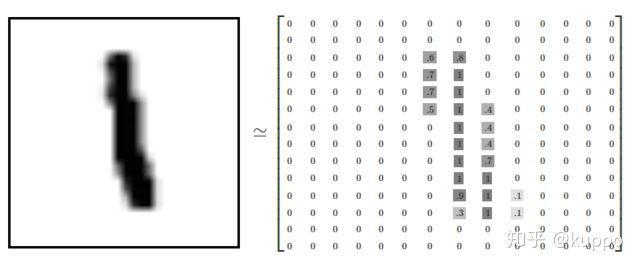
然后去学习:
【未解决】算法:One-Hot Encoding
转载请注明:在路上 » 【整理】用于训练人工智能算法的数据集:MNIST数据集