折腾:
期间,结果又出现:
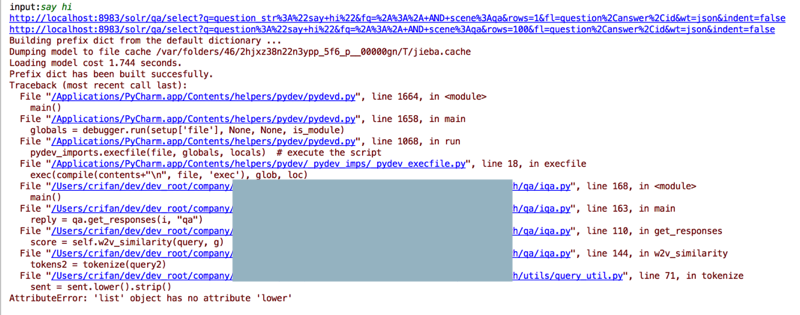
<code>input:say hi http://localhost:8983/solr/qa/select?q=question_str%3A%22say+hi%22&fq=%2A%3A%2A+AND+scene%3Aqa&rows=1&fl=question%2Canswer%2Cid&wt=json&indent=false http://localhost:8983/solr/qa/select?q=question%3A%22say+hi%22&fq=%2A%3A%2A+AND+scene%3Aqa&rows=100&fl=question%2Canswer%2Cid&wt=json&indent=false Building prefix dict from the default dictionary ... Dumping model to file cache /var/folders/46/2hjxz38n22n3ypp_5f6_p__00000gn/T/jieba.cache Loading model cost 1.744 seconds. Prefix dict has been built succesfully. Traceback (most recent call last): File "/Applications/PyCharm.app/Contents/helpers/pydev/pydevd.py", line 1664, in <module> main() File "/Applications/PyCharm.app/Contents/helpers/pydev/pydevd.py", line 1658, in main globals = debugger.run(setup['file'], None, None, is_module) File "/Applications/PyCharm.app/Contents/helpers/pydev/pydevd.py", line 1068, in run pydev_imports.execfile(file, globals, locals) # execute the script File "/Applications/PyCharm.app/Contents/helpers/pydev/_pydev_imps/_pydev_execfile.py", line 18, in execfile exec(compile(contents+"\n", file, 'exec'), glob, loc) File "/Users/crifan/dev/dev_root/xxx/search/qa/iqa.py", line 168, in <module> main() File "/Users/crifan/dev/dev_root/xxx/search/qa/iqa.py", line 163, in main reply = qa.get_responses(i, "qa") File "/Users/crifan/dev/dev_root/xxx/search/qa/iqa.py", line 110, in get_responses score = self.w2v_similarity(query, g) File "/Users/crifan/dev/dev_root/xxx/search/qa/iqa.py", line 144, in w2v_similarity tokens2 = tokenize(query2) File "/Users/crifan/dev/dev_root/company/xxx/projects/NLP/sourcecode/xxx/nlp/search/utils/query_util.py", line 71, in tokenize sent = sent.lower().strip() AttributeError: 'list' object has no attribute 'lower' </code>
算了,停止当前的调试,重新初始化试试
因为怀疑之前的solr是错误数据,然后启动了,导致连接find不到answer
现在刚重启solr,虽然可以建立cache,但是不是重头开始初始化的,难免可能哪里产生不良影响,所以去
停止并重启solr,然后重启此处对话代码调试
<code>➜ solr git:(master) ✗ solr stop -all
Sending stop command to Solr running on port 8983 ... waiting up to 180 seconds to allow Jetty process 46413 to stop gracefully.
➜ solr git:(master) ✗ solr start
Waiting up to 180 seconds to see Solr running on port 8983 [\]
Started Solr server on port 8983 (pid=46936). Happy searching!
➜ solr git:(master) ✗ solr status
Found 1 Solr nodes:
Solr process 46936 running on port 8983
{
"solr_home":"/usr/local/Cellar/solr/7.2.1/server/solr",
"version":"7.2.1 b2b6438b37073bee1fca40374e85bf91aa457c0b - ubuntu - 2018-01-10 00:54:21",
"startTime":"2018-08-21T07:33:59.365Z",
"uptime":"0 days, 0 hours, 0 minutes, 38 seconds",
"memory":"24.1 MB (%4.9) of 490.7 MB"}
</code>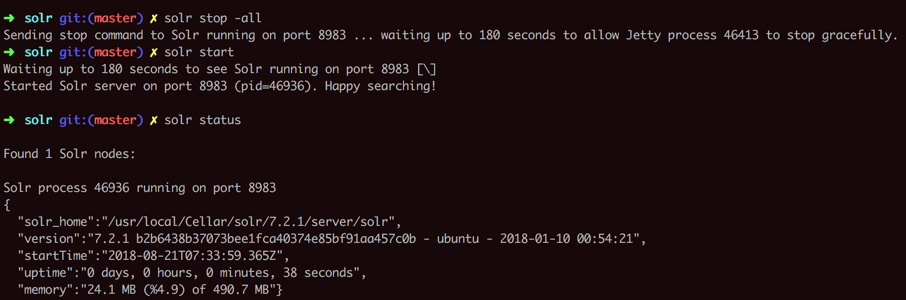
结果问题依旧:
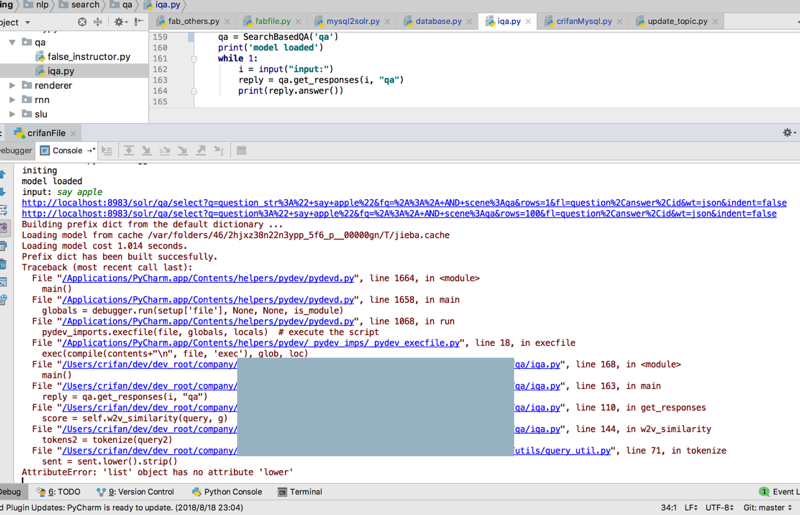
根据错误代码,去调试看看:
nlp/search/qa/iqa.py
<code>b = doc[self.answer_key] g = doc[self.question_key] score = self.w2v_similarity(query, g) </code>
看起来是:
g = doc[self.question_key]
返回一个list了,而正常希望是返回一个string
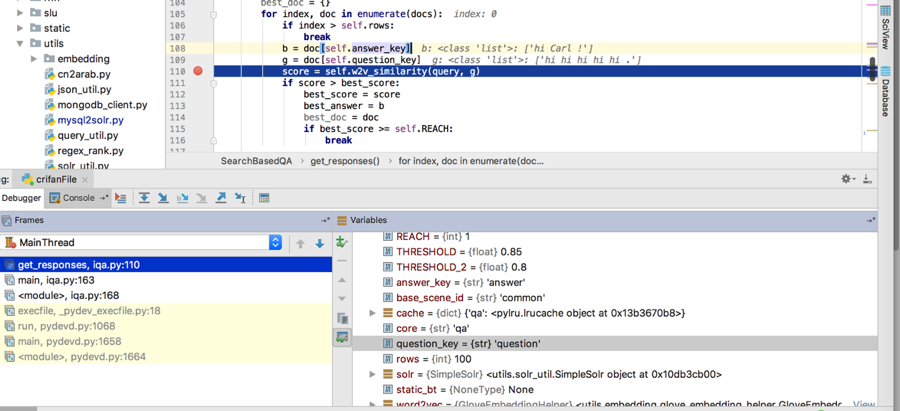
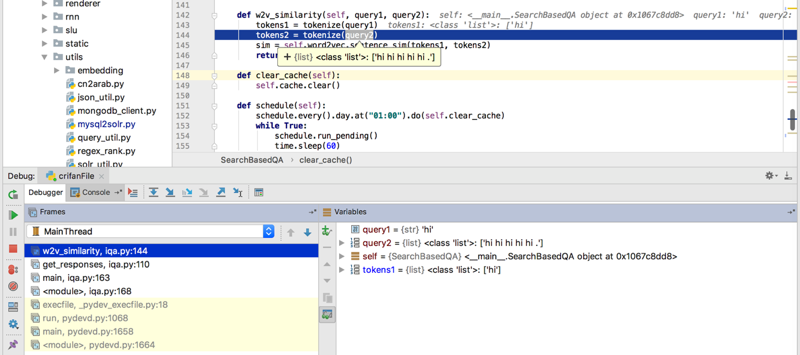
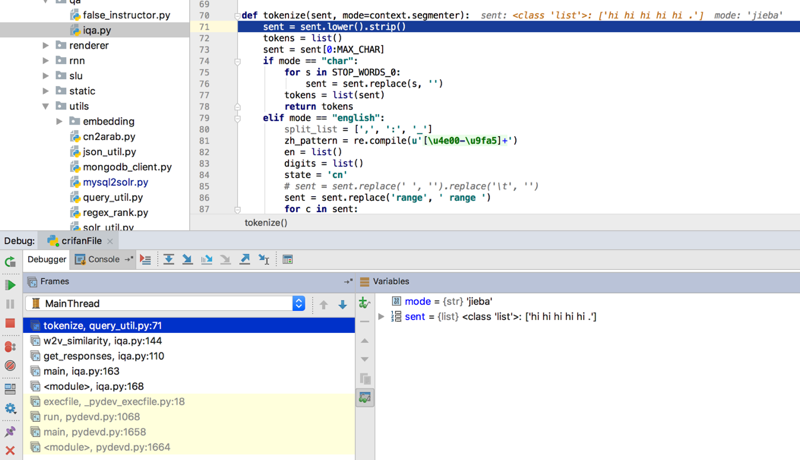
对list而不是str去lower,所以就报错了
那么自己擅自加上判断:
<code>def tokenize(sent, mode=context.segmenter): if isinstance(sent, list): sent = sent[0] sent = sent.lower().strip() </code>
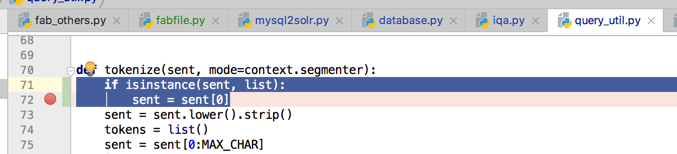
试试效果:
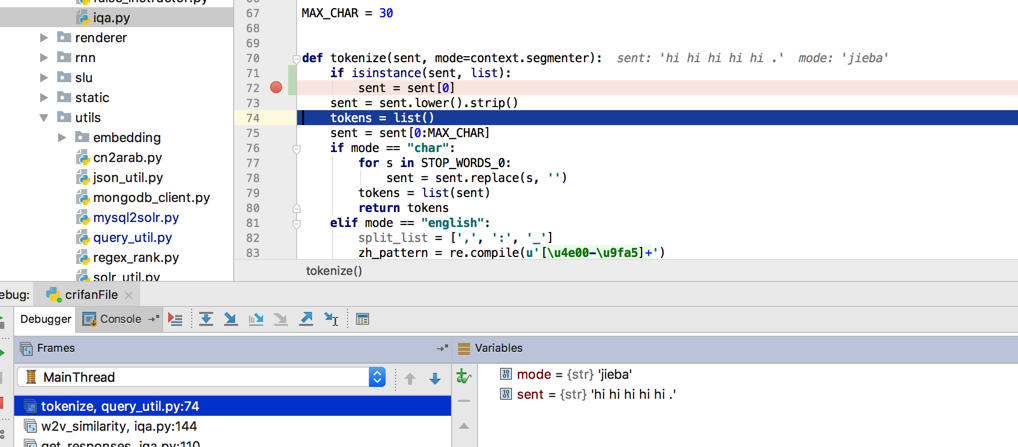
是可以规避这个问题的。
转载请注明:在路上 » 【已解决】调试基于solr的兜底对话出错:AttributeError: ‘list’ object has no attribute ‘lower’