版本:v3.0
摘要
本文主要介绍了笔者crifan推荐的轻量级文本编辑器,Notepad最佳替代品:Notepad++,内容主要包含notepad,notepad2,notepad++,ultraEdit的比较,使用Notepad++前要了解的知识,Notepad++的插件,Notepad++的安装过程,Notepad++的各种常见和不常见的功能的详解
2013-12-15
| 修订历史 | ||
|---|---|---|
| 修订 3.0 | 2013-12-15 | crl |
| ||
| 修订 2.1 | 2013-09-04 | crl |
| ||
| 修订 1.0 | 2012-08-03 | crl |
| ||
版权 © 2013 Crifan, http://crifan.com
目录
- 正文之前
- 1. Notepad++的插件
- 1.1. Notepad++插件的存在形式与位置
- 1.2. Notepad++默认已经安装了的一些插件
- 1.3. Notepad++插件的下载与安装
- 1.4. Notepad++中常用的插件
- 2. Notepad++的安装过程
- 3. Notepad++的功能详解
- 3.1. Notepad++支持右击打开所选文件
- 3.2. Notepad++的语法高亮
- 3.3. Notepad++的多种编码支持
- 3.4. Notepad++的正则表达式替换和替换
- 3.5. Notepad++的计数功能
- 3.6. Notepad++的列编辑功能
- 3.7. Notepad++的代码折叠
- 3.8. Notepad++的自动完成
- 3.9. Notepad++的默认HTML查看器
- 3.10. Notepad++支持显示回车符,换行符,TAB键,行首,行尾等特殊字符
- 3.11. Notepad++支持插入特殊字符
- 3.12. Notepad++高亮所选关键字
- 3.13. Notepad++中Windows,Unix,Mac三种格式之间的转换
- 3.14. Notepad++高亮匹配的键对
- 3.15. Notepad++文件自动更新
- 3.16. Notepad++设置用空格取代TAB键
- 3.17. Notepad++给代码单行/批量,添加/取消注释
- 3.18. Notepad++的多主题
- 3.18.1. Notepad++主题: Default
- 3.18.2. Notepad++主题: Bespin
- 3.18.3. Notepad++主题: Black Board
- 3.18.4. Notepad++主题: Choco
- 3.18.5. Notepad++主题: Zenburn
- 3.18.6. Notepad++主题: Deep Black
- 3.18.7. Notepad++主题: Hello Kitty
- 3.18.8. Notepad++主题: Mono Industrial
- 3.18.9. Notepad++主题: Monokai
- 3.18.10. Notepad++主题: Obsidian
- 3.18.11. Notepad++主题: Plastic Code Wrap
- 3.18.12. Notepad++主题: Ruby Blue
- 3.18.13. Notepad++主题: Solarized-Light
- 3.18.14. Notepad++主题: Solarized
- 3.18.15. Notepad++主题: Twilight
- 3.18.16. Notepad++主题: Vibrant Ink
- 3.18.17. Notepad++主题: Vim Dark Blue
- 3.19. Notepad++的一些小功能
- 参考书目
插图清单
- 2.1. Notepad++的右击打开文件功能
- 2.2. Notepad++默认已安装了一些插件
- 3.1. XML文件中的Notepad++的代码折腾功能
范例清单
- 3.1. 在Notepad++中使用ISO-8859-1编码打开VirtualBox的Manual的HTML源码
- 3.2. 出现乱码,猜测出是西欧编码,切换到ISO 8859-1而消除乱码
- 3.3. Notepad++正则表达式替换举例:一次性替换多个文件的后缀
- 3.4. Notepad++正则表达式替换举例:一次性替换多个路径
- 3.5. Notepad++正则表达式替换举例:一次性替换多个listitem为sect4
- 3.6. Notepad++正则表达式替换举例:给每一行都添加AddIcon的前缀
- 3.7. Notepad++正则表达式替换举例:给book的标题和地址添加html代码
- 3.8. Notepad++正则表达式替换举例:查找单个的CR或LF
- 3.9. Notepad++正则表达式替换举例:去除href链接
- 3.10. Notepad++正则表达式替换举例:把标题和地址转换为link格式
- 3.11. Notepad++正则表达式替换举例:给关键字添加双引号,把逗号变成竖杠
- 3.12. Notepad++正则表达式替换举例:wlw中图片分行
- 3.13. Notepad++正则表达式替换举例:给sect2添加xml:id和title
- 3.14. Notepad++正则表达式替换举例:保持sect2和title添加xml:id
- 3.15. Notepad++正则表达式替换举例:去除单引号变成antlr的token
- 3.16. Notepad++正则表达式替换举例:将单引号加ID变成antlr的token的定义
- 3.17. Notepad++正则表达式替换举例:dd宏定义中去除多国语言字符串
- 3.18. Notepad++正则表达式替换举例:C宏定义转java变量定义
- 3.19. Notepad++正则表达式替换举例:docbook的link变bibliomixed
- 3.20. 列编辑:多行输入同样内容
- 3.21. 列编辑:删除多行内容
- 3.22. 列编辑:多行中插入相同或不同的内容
- 3.23. 列编辑:同时复制和粘贴多列
- 3.24. Notepad++可以查看特殊字符的用途举例
- 3.25. Notepad++可以插入特殊字符的用途举例
目录
此文所对应的,原先的旧帖为:[1]
因为Notepad++的确很好用,有很多优点,值得推荐给不熟悉的人。
关于Notepad++,先用几句话概述一下其特点:
- Notepad++是一个文本编辑工具,而且是免费的。
- Notepad++旨在替代Windows默认的Notepad而生,比notepad的功能强大很多很多。
- Notepad++比UltraEdit更加轻量级,比Notepad2等更强大好用。
- Notepad++本身的功能已经非常强大,且又支持插件,可以扩展更多的功能。并且已经有很多很有用和好用的插件可供选择使用。
在详细介绍Notepad++之前,先来解释一下,为何要选择Notepad++,即把常见的一些文本编辑器和Notepad++比较,看看其有哪点好:
常见的文本编辑器有很多,此处,只提及Notepad,Notepad2,Notepad++和UltraEdit。
对于这些文本编辑器,之前或多或少都曾用过,但是随着使用经验的增长,越加发现,Notepad++是最好用的。
目前,在Windows环境下,偶已完全抛弃除了Notepad++之外的其他文本编辑器了。
下面,就对这几种常见的文本编辑器,做个大概比较:
表 1. Notepad,Notepad2,Notepad++,UltraEdit之间的对比
| 文本编辑器 | 是否免费 | 功能强弱 | 易用性
|
资源消耗 | 启动和编辑速度
|
其他说明 |
|---|---|---|---|---|---|---|
| Notepad | 免费 | 非常弱 | 易用 | 很少 | 快 | Windows自带,免安装 |
| Notepad2 | 免费 | 强 | 易用 | 一般 | 快 | |
| Notepad++ | 免费 | 非常强 | 易用 | 稍多 | 快 | |
| UltraEdit | 收费 | 非常强 | 难用 | 非常多 | 慢 |
|
此处的易用性,主要指的是,有很多细节的功能上,虽然都支持某功能,但是是否方便用户使用。 比如,列编辑的功能,UltraEdit和Notepad++都支持,但是第 3.6 节 “Notepad++的列编辑功能”支持直接通过Alt+鼠标,就可以选择多列并拷贝粘贴了,很是方便使用。 |
|
此处主要是,对于大一点的文件,在编辑的时候,是否很快。 |
因此,根据启动速度,占用资源,功能支持等方面来综合衡量,对于notepad,notepad2,notepad++,ultraEdit来说,无疑notepad++是最好的选择了。
安装和使用Notepad++之前,需要了解一些相关的基本知识:
Notepad++中,改变某配置的值之后,(不像其他软件,需要点击“启用”或“确定”,才能看到效果,而是),立即生效,即可可以看到效果。
最明显的一个例子就是,当改变了Notepad++的主题后,即可可以看到当前主题的效果。详参:第 3.18 节 “Notepad++的多主题”
Notepad++有两个版本,一个是ANSI版本,一个是UNICODE版本。
![[提示]](http://www.crifan.com/files/res/docbook/images/tip.png) |
如何查看Notepad++的版本 | |
|---|---|---|
|
Notepad++中,点击:? → 关于Notepad++...F1
即可看到对应的标有Unicode,或者ANSI的字样,我这里的是Unicode的:
|


对于大多数人把Notepad++作为notepad的增强版,而需要的普通应用的话,ANSI版本和UNICODE版本,其实没啥差别。
不过,就像[2]中所说的,如果不是非得用ANSI版本才支持的极个别插件的话,那么还是推荐大家使用Unicode版本的,其支持几乎所有的字符。
|
Unicode几乎包括了世界上的所有字符 |
|---|---|
|
如题,Unicode就是为了统一世界上如此多的字符而出现的,所以推荐使用Unicode版本的Notepad++。 关于Unicode更多的解释,请参看:[3] |
结论:不用管太多,记住用Unicode版本的Notepad++就行了。
目录
- 1.1. Notepad++插件的存在形式与位置
- 1.2. Notepad++默认已经安装了的一些插件
- 1.3. Notepad++插件的下载与安装
- 1.4. Notepad++中常用的插件
插件,意味着功能的扩展。
所以当你需要某些功能,而Notepad++本身没有提供此功能,此时就可以考虑插件了。
Notepad++不仅支持通过插件扩展已有功能,更主要的是目前已经有非常多的插件可供选择了。
而且很多功能都是很实用和很方便使用的。
你可以通过点击工具栏中的 插件(P),而找到目前已经安装了哪些可用的插件:
 |
下面对Notepad++的插件的各个方面,进行详细介绍:
Notepad++的插件是dll文件的形式存在的
比如16进制编辑器,HEX-Editor,对应的dll文件是:HexEditor.dll
插件是存放在安装目录下的plugins目录中,比如D:\Program Files (x86)\Notepad++\plugins
某些插件,由于某些原因,比如兼容性不够好的话,会在重新安装Notepad++的过程中,被Notepad++直接禁用掉。
比如,我最喜欢的其中一个插件,叫做HEX-Editor,由于兼容性不好而在安装过程中被禁用:
 |
被禁用的插件,其dll文件会被移至到disabled目录中,比如D:\Program Files (x86)\Notepad++\plugins\disabled
如图 2.2 “Notepad++默认已安装了一些插件”中所介绍,在安装Notepad++的过程中,默认已经安装了一些常用插件,这些插件的目前包括:
- Spell Checker
- NPP FTP
- NppExport: 第 1.4.3 节 “导出彩色代码为其他(word,HTML)格式的文件: NppExport”
- Plugin Manager: 第 1.4.1 节 “插件管理器: Plugin Manager”
- Converter
关于各插件的功能的详细介绍,请参考第 1.4 节 “Notepad++中常用的插件”
目前已知这些地方可以找到Notepad++的插件:
-
Notepad++的SourceForge的Plugins主页
里面可以直接下载对应的插件。不过需要注意的是,该页面中的插件数量,相对不多。
-
? ⇒ 获取插件
在Notepad++软件中,点击菜单栏左右边的那个问号,然后点击获取插件:

就可以自动帮你调用浏览器打开页面:[4]
该页面中,包含了对于每个插件的简单介绍,以及其所适用于的版本,是ANSI还是Unicode的。
对于想要找一些功能,但是连插件名都不知道的情况下,很适合去那里找找。
如同第 4.3 节 “Notepad++的版本:ANSI和Unicode”中的介绍,Notepad++插件也是分ANSI和Unicode版本的,所以,你下载插件的时候,记得要下载和你当前Notepad++版本所匹配的插件。
比如,[5]版本的[6]中就有:HexEditor_0_9_5_UNI_dll.zip和HexEditor_0_9_5_ANSI_dll.zip,所以,如果你用的是前面所推荐的Unicode版本的话,那么所需要下载的就是HexEditor_0_9_5_UNI_dll.zip。
Notepad++的插件有多种安装方法:
参考第 1.3.1 节 “去哪里下载Notepad++的插件”中的描述,去最全的Notepad++插件的官方主页中,找到自己想要的插件。该页面中同时也提供了下载地址。
把下载到的插件的dll文件,放到对应的安装目录下的plugins目录中即可。
个别的插件,还需要安装其他一些配置文件,比如一些xml配置文件等。具体如何操作,下载下来的插件压缩包中,都会有对应的提示的,按照提示安装即可。
关于如何通过使用Plugin Manager去安装插件,请参看第 1.4.1 节 “插件管理器: Plugin Manager”
![[注意]](http://www.crifan.com/files/res/docbook/images/note.png) |
插件安装完毕后,最好重启Notepad++ |
|---|---|
Notepad++插件安装完毕后,需要重启Notepad++,这样才能正确识别并可用。 |
插件功能:此插件可以帮你管理插件,包括查看当前已经安装的插件有哪些,以及自动帮你下载相应的插件。
插件用途:主要用于管理(安装和卸载)插件
插件安装:在安装过程中,默认已选择安装此插件:图 2.2 “Notepad++默认已安装了一些插件”
插件(P) → Plugin Manager → Show Plugin Manager → Avaliable,一栏显示当前可用的插件列表,选中你要的插件,然后点击下面的Install即可自动下载和安装对应插件,很是方便。
 |
其中,在Intalled一栏可以看到当前已经安装了的插件有哪些:
 |
下面以Light Explorer为例,说明如何通过Plugin Manager来安装插件:
通过第 1.4.1.1 节 “打开Plugin Manager”打开Plugin Manager后,找到并选中Light Explorer,然后点击Install:
 |
Plugin Manager就会帮你自动下载对应的插件并安装:
 |
安装完毕后,会提示你是否重启:
 |
选择“是”后,Notepad++会自动重启,并且会自动打开关闭前已打开的这些文件。
此时,就可以看到已经安装的插件了:
 |
插件功能:此插件主要提供了16进制查看与编辑的功能。
插件用途:以16进制模式查看和编辑文件。
插件安装:参考第 1.3 节 “Notepad++插件的下载与安装”去安装Hex Editor插件
HEX-Editor功能详解:



插件功能:导出已着色代码为其他格式的文件
插件用途:将彩色代码,导出为word文档(RFT)或网页(HTML)文件,或者将彩色代码(RTF格式或HTMl格式)拷贝到剪贴板,粘贴到别的(word文档,HTML网页)中去。
插件安装:在安装过程中,默认已选择安装此插件:图 2.2 “Notepad++默认已安装了一些插件”
NppExport功能详解:
对于选中的代码,将其对应的RTF格式的内容,复制到剪贴板:
 |
然后粘贴到新建的word文档中:
 |
想要获得彩色代码的人,对于此功能,相信会非常喜欢的。
|
直接拷贝代码,是没有彩色代码的效果的 | |
|---|---|---|
|
差点忘了说了,与此处的彩色代码拷贝功能相对应的是: 对于在普通文本编辑器中,包括当前的Notepad++编辑器,安装普通赋值操作去的拷贝的一段代码:
然后粘贴到别的地方,是没有彩色代码的效果的:
所以,有了对比,才知道此处彩色代码拷贝的好处。 |


对应的,想要将整个文件全部导出的话,就是:
插件(P) ⇒ NppExport ⇒ Export to RTF
 |
即可将当前已经语法高亮的彩色的xml代码:
 |
导出到word文件中了:
 |
很明显,如果你需要在word中粘贴此彩色代码,此功能,再好用不过了。
对于导出为HTML网页,做法是类似的:
 |
插件功能:轻量级的Explorer
插件用途:方便打开文件
插件安装:参考第 1.4.1.2 节 “通过Plugin Mangager安装插件”去安装Light Explorer插件。
Light Explorer功能详解:


之前就一直希望Notepad++拥有此功能,结果没找到选项,现在终于通过插件得以实现了。
是从Bracket autocompletion中得知的此插件XBracket Lite的。
插件功能:对于一些括号类的字符,比如单引号',双引号",圆括号(,大括号{,反括号[等,自动帮你实现自动补全
插件用途:减轻了写代码和编译xml类的文件时候的工作量
插件安装:参考第 1.4.1.2 节 “通过Plugin Mangager安装插件”去安装XBracket Lite插件,截图如下:
 |
XBracket Lite功能详解:
先去打开相应的设置:
 |
再根据自己的需要去设置:
 |
其中解释一下相应的选项的含义:
- Treat'' as brackets
把单引号',也看成是括号,这样以后输入单个单引号,也可以实现自动补全另一个单引号了。
- Treat< > as brackets
把尖括号也看成是括号的一类,这样就方便了在xml,html等文件中写tag的时候,自动帮你补全。
如果选择了: </>,那么输入了<后,就补全出来/>了。
如果选择了:Only if file extension contains,那么就只有当前是这些htm,xml等文件的时候,才对于尖括号使用自动补全。别的类型文件中,不去对尖括号实现补全操作。
- Skip escaped bracket characters:\[,\} etc.
当输入\[或者是\}的时候,就不自动补全。
因为在写代码时,很多时候反斜杠加上这些括号,本身就是想要表示单个字符而已,所以不需要补全。
- Autocomplete brackets([{""}])
即 是否启用此插件。
设置好之后,启用该插件,随便打开个文件,输入这些括号类字符的时候,就会发现,可以自动帮你实现自动补全了。
之前叫做NppScripting,后来改名为jN
插件功能:使得Notepad++中可以通过运行对应的javascript脚本,其会扩展一些额外功能,添加相应的菜单,提供各种功能
插件用途:使得你可以实现,自己写javascript脚本,几乎可以实现任何你想要的功能。而且本身其已经实现了很多常用的功能,供你使用。
插件安装:
参考第 1.3.2.1 节 “手动安装插件”下载jn.zip
解压后,把jN文件夹和jN.dll拷贝到Notepad++的plugin目录下即可。
更多的细节,参考【记录】利用Notepad++的jN插件中的URL编码解码插件,实现从错误的google地址中提取原始url的功能
插件功能:用于显示出函数的列表。支持很多种语言,包括C, C++, Resource File, Java, Assembler, MS INI File, HTML, Javascript, PHP, ASP, Pascal, Python, Perl, Objective C, LUA, Fortran, NSIS, VHDL, SQL, VB and BATCH
插件用途:这样以后打开Python等文件,就可以通过双击显示出来的函数列表中的某函数,实现快速定位到相应的位置了。
插件安装:
参考第 1.3.2.1 节 “手动安装插件”下载FunctionList_2_1_UNI_dll.zip
解压后,按照install.txt中的提示去:
把FunctionList.dll拷贝到 安装目录\Notepad++\plugin下
把Gmod Lua.bmp和C++.flb拷贝到 安装目录\Notepad++\plugin\config下
把FunctionListRules.xml拷贝到 %APPDATA%\Notepad++\plugins\config下
其中需要注意的是,此处的FunctionListRules.xml就是定义了各种语言的搜索函数的规则。必须把该文件拷贝到上述位置才可以。像我最开始的时候,拷贝到安装目录\Notepad++\plugin\config下是不可以的。
而%APPDATA%的位置,在我这里的是C:\Users\CLi\AppData\Roaming\Notepad++\plugins\config
之后通过 插件 ⇒ Function List ⇒ List...或者快捷键Ctrl+Alt+Shift+L,就可以打开当前文件的函数列表了:
 |
插件功能:包含三个功能:
- js代码压缩
- js代码格式化功能
- JSON代码查看器,以树状列表显示
插件用途:三和一功能的插件,很是方便使用。
插件安装:
参考第 1.3.2.1 节 “手动安装插件”,去JSMinNpp下载JSMinNPP.1.11.2.uni.zip,解压后把JSMinNPP.dll拷贝到plugin目录即可。
去试了试,真的很好用:
- js代码压缩

- js代码格式化功能

- JSON代码查看器,以树状列表显示

话说,装了这个插件之后,以前一直使用的,在线版本的HTML/JS代码格式化网站:Beautify JavaScript or HTML,就可以减少使用次数了。
因为javascript,json等代码,都可以使用此插件格式化并以树状显示了。
只不过,对于html代码的格式化,还是需要用到那个jsbeautifier的。
目录
其实关于Notepad++的安装,本身操作步骤简单,没有太多解释必要,但是对于安装过程中很多的参数,有必要解释一下:
下面就详细解释一下Notepad++的安装过程:
下载了notepad的可执行文件,比如npp.6.1.1.Installer.exe后,双击它,接着就可以安装了:





然后是“选择安装位置”的界面,对于其中的“目标文件夹”,可以使用默认设置的值,也可以选择一个别的路径,比如我此处改为了D盘的相应位置:D:\Program Files (x86)\Notepad++\
 |
再点击
出现“选择组件”的界面:
 |
可以看到,此处有好几个选项:
- Context Menu Entry
默认已勾选
其作用是添加右键快捷键。即,对于任何文件右击所出现的菜单中,都会有“Edit with Notepad++”:

其显而易见的好处是,可以很方便的启动Notepad++去打开相应的(任何)文件。
- Auto Complete Files
Notepad++安装选项:Auto Complete Files.

默认已勾选其作用是,对于各种语言或规范(C,C++,Docbook,Python等),支持第 3.8 节 “Notepad++的自动完成”的功能。
- Plugins
默认已勾选
其作用是,默认是否安装一些插件。当然,这些插件是足够的好用和常用,所以Notepad++才会默认将他们集成进来,默认勾选上的。
关于这些插件的详细功能的介绍,参见第 1.4 节 “Notepad++中常用的插件”
- Localization

默认无勾选
其作用是,在Notepad++的界面显示方面的对于各种语言的支持,即Notepad++本身软件的各个工具栏等部分的显示的文字所用的语言。
对应着Notepad++中的:设置(T) → 首选项... → 常用,中的“界面语言”:

此处可选可不选,因为本身除了当前中文和默认英文,其他的也基本遇不到。
- Themes

默认已勾选。即Notepad++中,是否支持各种主题。其对应着Notepad++中的:设置(T) → 语言格式设置...,中的“选择主题”:

关于每种主题的效果,可以参看第 3.18 节 “Notepad++的多主题”
- As default html viewer
Notepad++安装选项:As default html viewer.

默认无勾选。建议勾选。选上后,其就可以用作默认的HTML网页源码编辑器了,详情参看:第 3.9 节 “Notepad++的默认HTML查看器”
- Auto-Updater

默认已勾选。
作用为,安装此模块后,就可以支持Notepad++的自动更新了。
其对应着:设置(T) → 首选项... → 其他,中的“启用Notepad++自动更新”:

启用后,每次Notepad++启动时,都会去检测是否有更新。如果有,会跳出对话框提示你是否更新的。
- User Manual

默认已勾选。
作用是,安装本地的帮助文件。其是网页的形式。Notepad++中通过点击:? → 帮助 Shift+F1:

即可打开对应的网页文件:



根据需要,选择所需的组件后,点击"下一步"
会出现另外一些组件参数选择:
 |
其也有一些参数需要解释:
- Don't use %APPDATA%
默认没勾选。
作用是允许配置文件放在Notepad++的安装路径下。由此,可以实现支持把整个Notepad++都放到U盘中,到处带着跑了。
其用途主要是,如果本身自己对于Notepad++有很多自定义的配置,而换了个电脑,就得重新配置Notepad++,很是麻烦。
而此时,就可以在安装的时候,选择此项,这样以后所有的配置都是放在安装路径下,然后你可以把此Notepad++全部文件都放到U盘中。
这样,换了电脑,也都可以继续使用你自己的这个Notepad++了。
- Allow plugins to be loaded from %APPDATA%\\notepad++\\plugins
默认没勾选。
作用是不太了解。看起来好像是说,允许从%APPDATA%\\notepad++\\plugins的位置,载入插件,如此做法,有一定的安全隐患。
其估计指的是,有些不安全的插件,放到对应位置的话,其也会自动载入,所以可能会导致一些安全问题。
- Create Shortcut on Desktop
默认没勾选。
在桌面穿件一个Notepad++的快捷方式。
常见使用Notepad++的方式都是从文件右键中选择“Edit with Notepad++”,所以一般不需要在桌面创建快捷方式。
- Use the obsolete and monstrous icon
默认没勾选。
使用旧的风格的图标。
估计旧的风格的图标很难看,所以作者才说,即使你选择此项,其也不会责怪你的。要不然肯定是默认也勾选此项才对。
然后点击“安装”,即可。

至此,Notepad++安装完毕。
目录
- 3.1. Notepad++支持右击打开所选文件
- 3.2. Notepad++的语法高亮
- 3.3. Notepad++的多种编码支持
- 3.4. Notepad++的正则表达式替换和替换
- 3.5. Notepad++的计数功能
- 3.6. Notepad++的列编辑功能
- 3.7. Notepad++的代码折叠
- 3.8. Notepad++的自动完成
- 3.9. Notepad++的默认HTML查看器
- 3.10. Notepad++支持显示回车符,换行符,TAB键,行首,行尾等特殊字符
- 3.11. Notepad++支持插入特殊字符
- 3.12. Notepad++高亮所选关键字
- 3.13. Notepad++中Windows,Unix,Mac三种格式之间的转换
- 3.14. Notepad++高亮匹配的键对
- 3.15. Notepad++文件自动更新
- 3.16. Notepad++设置用空格取代TAB键
- 3.17. Notepad++给代码单行/批量,添加/取消注释
- 3.18. Notepad++的多主题
- 3.18.1. Notepad++主题: Default
- 3.18.2. Notepad++主题: Bespin
- 3.18.3. Notepad++主题: Black Board
- 3.18.4. Notepad++主题: Choco
- 3.18.5. Notepad++主题: Zenburn
- 3.18.6. Notepad++主题: Deep Black
- 3.18.7. Notepad++主题: Hello Kitty
- 3.18.8. Notepad++主题: Mono Industrial
- 3.18.9. Notepad++主题: Monokai
- 3.18.10. Notepad++主题: Obsidian
- 3.18.11. Notepad++主题: Plastic Code Wrap
- 3.18.12. Notepad++主题: Ruby Blue
- 3.18.13. Notepad++主题: Solarized-Light
- 3.18.14. Notepad++主题: Solarized
- 3.18.15. Notepad++主题: Twilight
- 3.18.16. Notepad++主题: Vibrant Ink
- 3.18.17. Notepad++主题: Vim Dark Blue
- 3.19. Notepad++的一些小功能
下面就来详细介绍Notepad++中的N多好用易用的功能:
下列功能的排名先后顺序,由个人所认为的该功能的重要性高低而决定
即,通过右击某文件,然后选择"Edit with Notepad++",就可以用Notepad++打开该文件了。
虽然此功能很简单,但是相当的实用,而且也是最常用的功能。
|
注意 |
|---|---|
|
此功能是由开始安装Notepad++的时候,选择是否安装此功能的。 Notepad++安装程序中,默认已选择开启该功能了。 |
 |
语法高亮,Syntax Highlight,也被叫做代码高亮
其实,其他很多文本编辑器也都支持此语法高亮功能,但是发现Notepad++支持的语言更多,更方便使用。
个人用过的,就有C,C++,Python,XML,HTML,xml,Javascript等,
甚至还支持一些相对很多人不是很常用的类型,比如makefile,tex/LaTex等。
而对于这些的支持,作为开发者的话,如果等你遇到了,有此需求了,就会发现,这些功能是多么有用。
Notepad++对于任何一个文件,想要实现对应的语法高亮的话,大概逻辑是:
先是根据该文件后缀,去判断该文件属于哪种类型的文件
然后再调用对应的语法高亮配置,给不同的关键字(和符合对应逻辑的代码),设置不同的属性,包括字体粗细,改变颜色等
最终得到我们所看到的语法高亮后的代码的效果。
因此,如果文件没有后缀,或者不支持该文件的后缀名,则Notepad++打开该文件后,也没法自动对其实现语法高亮。
比如对于一个文件,Makefile.mk,其是一个makefile文件,用Notepad++打开后,由于无法识别后缀,不知道是何种类型文件,所以无法语法高亮:
 |
而如何对不支持的文件类型实现语法高亮,就是下面第 3.2.2 节 “实现未知类型(不支持的后缀名)的文件的语法高亮”要介绍的内容了。
语言(L)⇒M⇒Makefile:
 |
即可看到语法高亮的效果了:
 |
|
注意 |
|---|---|
| 通过手动设置语言的方式实现语法高亮,只对当前打开的文件有效,关闭再打开,就失效了,就需要再手动操作一次,相对比较麻烦。推荐用下面的办法:第 3.2.2.2 节 “通过添加文件后缀名,实现未知类型文件的语法高亮” |
设置⇒语言格式设置⇒语言,选择Makefile
可以看到左下角有默认扩展名为mak,意思为,当Notepad++打开mak后缀的文件的时候,就识别为Makefile文件,调用Makefile的语法高亮设置,对此文件进行颜色设置。
对应的,想要支持mk后缀的Makefile文件的话,在自定义扩展名中,加上对应的mk
 |
同样可以实现对于后缀名为mk的文件,去实现对应的Makefile的语法高亮的效果。
|
提示 |
|---|---|
通过添加后缀名的方式,则可以实现之后的每次打开此后缀的文件名,都可以自动识别,并实现语法高亮的效果了。即一劳永逸的效果。 |
|
注意 |
|---|---|
|


在对什么字符编码,以及常见的一些字符编码,比如ISO 8859,UTF-8,GB2312,GBK等,有个最基本的了解之后,我们再来看看Notepad++在字符编码方面,有哪些功能:
对于想要知道当前文件所用的字符编码类型,可以如下操作:
选择 格式(M),然后就可以看到当前字符编码类型了:
 |
可以看到,当前xml文件所用字符编码类型为"以 UTF-8 无 BOM 格式编码"。
|
提示 |
|---|---|
| 关于UTF-8的BOM,不了解的可参考[9] |
需要提及的一些是,一般我们中文和英文,最常用的几个字符编码,大概有:
- 最通用的UTF-8,包含了(全世界几乎)所有的字符
- 双字节的Unicode/UTF-16/UCS-2 LE(Little Endian)
- 简体中文:GB18030 > GBK > GB2312
- 繁体中文:Big5
对应的编码,截图如下:
 |
当你打开某个文件时,可能会遇到一些乱码。
此时,如果知道当前文本本身是用的是何种编码,则可在Notepad++中选择对应编码打开,就可以正确显示文件内容了。
例 3.1. 在Notepad++中使用ISO-8859-1编码打开VirtualBox的Manual的HTML源码
比如,在打开VirtualBox官网中的用户手册(UserManual)的HTML源码的时候,默认是用ANSI编码打开的,所以会有乱码:
 |
|
提示 |
|---|---|
对于如何用Notepad++打开该HTML并高亮显示,可参考第 3.9 节 “Notepad++的默认HTML查看器” |
此时,注意到该HTML源码已经通过charset=ISO-8859-1标明了使用的编码是ISO-8859-1了,所以,此时可以去改为对应的ISO-8859-1编码:
 |
就可以看到对应的乱码的字符,都可以正常显示了:
 |
由此,就可以实现了,在Notepad++中,使用正确的编码打开相应的文件,解决了乱码显示问题。
如上所述,当HTML源码时,可以通过charset去得知文件编码。
但是,很多时候,我们去打开一个文件时,
可能会遇到乱码,但是由于未必立刻就已知其文件编码是什么
所以,只能去猜测其编码是什么,然后再切换到对应的编码类型,去查看内容是否可以正常显示。
例 3.2. 出现乱码,猜测出是西欧编码,切换到ISO 8859-1而消除乱码
比如遇到一个例子:
打开文件时,出现是乱码:
 |
看起来,就像是西欧类的字符,所以,去切换到对应的ISO 8859-1编码:
 |
然后真的就消除了乱码,可以正常显示出对应的一些特殊的西欧字符了:
 |
此处,很明显,由于对于编码稍微熟悉,所以一次就猜对了编码,而使得快速消除了乱码。
如果,你对于编码不是很熟悉,则可以多去尝试不同的编码,
最后,肯定也还是可以切换到正确的编码,可以正常显示字符的。
而随着对于字符编码的了解越来越深入,则自然会越加熟悉的,越容易一次或几次就猜对文件的正确的编码的。
很多时候,我们需要在不同字符编码之间,进行相互转换。
或者由于某些需要,要建立对应的编码的文件。
比如,写Python代码的时候,常需要文件本身的编码就是UTF-8的,
此时,就可以用Notepad++的字符编码转换方面的功能了。
比如,此处将本地一个UTF-8的xml文件:
 |
其中,中文字符所对应的16进制的如下:
 |
然后点击“转为 ANSI 编码格式”:
 |
即可转为ANSI编码了,此时文件已被修改,所以先保存一下该文件,然后再查看编码,就变为ANSI编码了:
 |
此时再去查看对应的中文字符所对应的16进制的值,就变了:
 |
而此处的ANSI编码,可以简单的理解为“本地”编码,而此处是本地编码是中文的GBK,所以此处ANSI即为GBK中文编码。
相应地,可以根据自己需要,在多个不同的字符编码之间互相转换。
当我们在Notepad++中新建一个文件时,可以通过第 3.3.1 节 “用Notepad++查看当前文件编码”看到新建的文件所使用的字符编码:
 |
此处为UTF-8。
而想要改变新建文件的默认所用字符编码,可以通过:
设置(T) ⇒ 首选项...
 |
新建,中的“编码”:
 |
然后设置为自己所需要的编码格式。
|
Notepad++的bug:有时候执行编码转换会导致内容丢失 |
|---|---|
|
我遇到过好多次了,在执行代码转换的时候,结果是当前Notepad++打开页面变成空白了,即内容瞬间丢失了,按Ctrl+Z,也无法撤销此操作。 如果不是有备份文件的话,则就会导致文件内容丢失。 如果是很重要的文件的话,文件内容丢失,损失还是很严重的。 尽管Notepad++此编码转换导致文件内容丢失的bug,出现的概率很小,但是也还是建议,对于重要文件的编码转换,转换之前,先备份一下。 |
下面就来详细介绍Notepad++中关于正则表达式的部分,主要是查找和替换。
对于替换功能,一般的文本编辑器,都具有此功能,但是对于高级的正则表达式替换,则很多都不支持。而此处Notepad++支持此功能。
正则表达式的替换,在很长一段时间内,我都没有用到过。而后来有此需求的时候,由于不熟悉,导致也没去折腾具体如何使用的。
后来有空去弄了下,终于搞懂了。对此类功能不了解的人,会没啥感觉,但是看了下面的介绍,你就会发现这类功能的强大之处。
例 3.3. Notepad++正则表达式替换举例:一次性替换多个文件的后缀
举例说明,此处我有个xml文件,其中原始的内容为:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/right_click_then_property.jpg" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/right_click_then_property.jpg" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/advance_enviroment.jpg" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/advance_enviroment.jpg" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
其中images/env_var/win/xxx.jpg出现的次数,有好几十处。
此处需要把images/env_var/win/xxx.jpg,全部替换为images/env_var/win/xxx.png,即替换文件的后缀。
但是呢,如果手动改的话,改动量很大,效率很低,所以要尽量避免手动改。
另外,此处也不能通过全局的那个替换功能,因为全局替换只适用于固定的文字xxx替换为yyy,而此处文件名都不一样,所以无法实现统一的替换。
此时,才会考虑用Notepad++的正则表达式替换,去实现复杂的,非规则性的替换功能。
而对于正则表达式的替换,最开始,由于不了解其语法,错写成:
查找目标 :
images/env_var/win/\w+\.jpg
替换为(P):
images/env_var/win/\w+\.png
则替换结果是错的,原来的文件名都被替换为w+这两个字符了:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/w+.png" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/w+.png" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/w+.png" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/w+.png" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
后来,参考了[10]
然后得知是用反斜杠,加上数字,实现向后引用(back reference)。
|
Notepad++的正则表达式的语法 |
|---|---|
|
不过后来也找到了其他更专业和全面的解释:[11]
|
|
注意 |
|---|---|
|
之前就知道Notepad++底层是使用SciTE的库的,也顺便找到了SciTE的关于正则表达式的解释[12] 不过其中关于backreference的解释很不清楚。 |
最后写出正确的语法:
查找目标 :
images/env_var/win/(\w+)\.jpg
替换为(P):
images/env_var/win/\1\.png
 |
可以成功替换为:
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/right_click_then_property.png" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/right_click_then_property.png" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
......
<informalfigure>
<mediaobject>
<imageobject role="html"><imagedata fileref="images/env_var/win/advance_enviroment.png" align="left" scalefit="0" width="100%"/></imageobject>
<imageobject role="fo"><imagedata fileref="images/env_var/win/advance_enviroment.png" align="center" scalefit="1" width="100%"/></imageobject>
</mediaobject>
</informalfigure>
如此,如果有类似需要,想要实现批量的,非规则性的替换,就可以好好利用Notepad++中的正则表达式去替换了。
例 3.4. Notepad++正则表达式替换举例:一次性替换多个路径
又比如,由于我把很多jpg,png等类型的图片,从images文件夹移动到了images下面的npp文件夹下了,
所以需要把一个文件中所有的:
images/xxx.yyy
其中xxx为文件名(此处文件名全部都是只包含字母和下划线),yyy=jpg或png,都替换为
images/npp/xxx.yyy
此时,就可以写成:
images/(\w+)\.(\w{3})
images/npp/\1\.\2
此处提示我成功替换了58处:
 |
相比之下,如果手动去改这58个地方,那真的是累死了不说,还容易由于手误而出错,效率太低。
通过正则表达式去替换,则是高效,又准确。
例 3.5. Notepad++正则表达式替换举例:一次性替换多个listitem为sect4
又比如,在docbook中,想要把原先的listitem部分的内容,都替换为sect4:
 |
并且也注意到,其中除了上层的listitem,其内部还有一些特殊的子listitem:
 |
需要在替换的时候,考虑到此点,不要将子listitem也替换掉了。
然后就是去想办法,写对应的正则表达式。
此时,注意到每个要替换的listitem的标题部分之后,是有回车和换行的,所以参考第 3.10 节 “Notepad++支持显示回车符,换行符,TAB键,行首,行尾等特殊字符”去"显示所有字符":
 |
这样就清楚,到底包含哪些字符,方便我们接下来去写正则表达式了。
经过折腾,用如下的正则表达式:
<listitem>(.+?)\r\n(.+?)\r\n\s+</listitem>\r\n
<sect4 xml:id="npp_"><title>\1</title>\r\n\2\r\n </sect4>\r\n
将原先内容:
 |
替换为:
 |
可以看到,成功替换了10个。
对应的,也可以看到,对于那些特殊的子listitem来说,也没有被替换掉:
 |
如此,就可以避免了手动的去一点点的修改了。
例 3.6. Notepad++正则表达式替换举例:给每一行都添加AddIcon的前缀
需要把每一行中的文件类型的图片名,替换成加上前缀和后缀。
然后就可以去写正则表达式了:
(\w+)\.png\s+\r\n
AddIcon http://www\.crifan\.com/files/res/apache/icons/20x22/\1\.png \.\1\r\n
就可以从:
 |
替换为:
 |
所以,如果能利用到此种功能,还是可以很大地提高工作效率的。
例 3.7. Notepad++正则表达式替换举例:给book的标题和地址添加html代码
又比如,对于原先是这样的代码:
 |
即,有很多组,每组分别是标题和地址。
而想要做的事情是,把对应的标题和地址,以及其中缩写,都提取出来,并且添加相关的html代码。
最后经过参考:[11]
而写出了相应的正则表达式:
(?<bookTitle>.+?)\r\n(?<wholeUrl>http://www\.crifan\.com/files/doc/docbook/(?<bookAbbrv>\w+)/release/html/(?&bookAbbrv)\.html)
<tr><td><a href="$+{wholeUrl}">$+{bookTitle}</a></td><td><a href="http://www.crifan.com/bbs/categories/$+{bookAbbrv}">$+{bookTitle}</td></tr>
然后就可以成功实现28处的替换,替换出来的效果为:
 |
替换后的html代码,再添加上相应的html代码:头部的:
<table border="1" cellspacing="0" cellpadding="0">
<tbody>
<tr><td><strong>单个Book</strong></td><td><strong>对应的讨论区</strong></td></tr>
和尾部的:
</tbody>
</table>
最终就可以实现需要显示出来的完整的表格信息了:
 |
则又一次地,极大地提高了工作效率。否则要一个个的复制和粘贴,累死了不说,也还容易出错。
例 3.8. Notepad++正则表达式替换举例:查找单个的CR或LF
后来一次,遇到一个需求是:对于单个文件中,查找所谓的不一致的换行符
去看了一下当前文件中,正常都是Windows类型的回车换行,CRLF
想要找到哪里出现了单个的CR或LF
而由于文件有很多行,里面有N个CRLF,而要一眼看出哪里有单个的CR或LF,很困难,或者说不可能,所以只能靠正则表达式去搜索寻找了
然后最终使用正则表达式是:
\r(?!\n)|(?<!\r)\n
然后找到了对应的2处,单个的CR或者LF:
 |
此处,顺便简单解释一下此处的正则表达式的含义:
例 3.9. Notepad++正则表达式替换举例:去除href链接
遇到一个问题是,想要把一个表格中的内容,粘贴到WLW中,结果由于其中N个内容,都包含了对应的链接,想要把链接去掉。
所以就去切换到源码模式,然后把html代码拷贝出来,然后用Notepad++去替换
所用正则是:
<p><a href="http://.+?/gpu\.php.+?">(<b>.+?</b>)</a></p>
<p>\1</p>
替换前是:
 |
替换后,变成这样的:
 |
效率不是一般的高。
例 3.10. Notepad++正则表达式替换举例:把标题和地址转换为link格式
遇到一个问题是,想要把对应的,帖子的标题和地址,变成docbook中的link格式,一般拷贝到Docbook的xml中直接使用,就省的自己一点点复制粘贴和修改了。
所用Notepad++的正则替换的如下:
([\S ]+)\s+(http://www\.crifan\.com/\w+)
<para><link xl:href="\2">\1</link></para>
替换前是:
 |
替换后,变成这样的:
 |
例 3.11. Notepad++正则表达式替换举例:给关键字添加双引号,把逗号变成竖杠
想要把:
XXX,
变为:
'XXX'|
所用Notepad++的正则替换表达式是:
([A-Z\_]+),?\s*
'\1'|
替换前:
 |
替换后:
 |
例 3.12. Notepad++正则表达式替换举例:wlw中图片分行
背景是,wlw编辑帖子,一次性导入70多个多个图片后,如果直接发布,则会导致图片之间没有换行,会横向接着排列,不好看。
想要在每两个图片之间,加上回车换行,即,对应的,对于html来说,是从:
<a href="$astronomy_dispel_trouble_20[2].jpg"><img title="astronomy_dispel_trouble_20" style="border-left-width: 0px; border-right-width: 0px; background-image: none; border-bottom-width: 0px; padding-top: 0px; padding-left: 0px; margin: 0px; display: inline; padding-right: 0px; border-top-width: 0px" border="0" alt="astronomy_dispel_trouble_20" src="$astronomy_dispel_trouble_20_thumb.jpg" width="960" height="720" /></a>
变成:
<p><a href="$astronomy_dispel_trouble_20[2].jpg"><img title="astronomy_dispel_trouble_20" style="border-left-width: 0px; border-right-width: 0px; background-image: none; border-bottom-width: 0px; padding-top: 0px; padding-left: 0px; margin: 0px; display: inline; padding-right: 0px; border-top-width: 0px" border="0" alt="astronomy_dispel_trouble_20" src="$astronomy_dispel_trouble_20_thumb.jpg" width="960" height="720" /></a></p>
而此转换,如果用手工去做,就只能在wlw中,手动输入回车换行,则至少需要按50多次的左右键加上回车,很是繁琐。
所以,就可以在wlw中,切换到源码,然后将html拷贝出来粘贴到notepad++中,利用notepad++中的正则,实现对应的替换。
对应的用的Notepad++的正则如下:
(<a[^<>]+?><img[^<>]+?/></a>)
<p>\1</p>\r\n
从:
 |
替换为:
 |
如此,高效的解决了问题。
例 3.13. Notepad++正则表达式替换举例:给sect2添加xml:id和title
背景是,为crosstool_ng写docbook的xml,然后想要对于之前的itemizedlist,改为sect2,已经手动替换itemizedlist为sect2了。
剩下的,还需要给sect2添加对应的xml:id和title,所以,就去Notepad++中写替换的正则
<sect2>(.+)$
<sect2 xml:id=""><title>\1</title>
将:
 |
替换为:
 |
如此,省去了几十次的,手动输入xml:id和title,以及复制和粘贴的繁琐工作。
简直就是一秒变格格的节奏啊,^_^
例 3.14. Notepad++正则表达式替换举例:保持sect2和title添加xml:id
在写Python教程的book的xml时,需要编辑对应的xml,涉及到处理sect2:
用正则:
<sect1><title>([^:]+:\s*)([a-zA-Z]+)</title>
<sect1 xml:id="\2"><title>\1\2</title>
将:
 |
替换为:
 |
又省去很多复杂的手动的复制粘贴的体力活了。
例 3.15. Notepad++正则表达式替换举例:去除单引号变成antlr的token
在折腾antlr的grammar时,将原先rule中有的literal都处理为token,所以去把部分单引号,都去掉,变成对应的token:
用正则:
'(\w+)'
\1
将:
 |
替换为:
 |
不用自己手动的去除对应的单引号了。
例 3.16. Notepad++正则表达式替换举例:将单引号加ID变成antlr的token的定义
在折腾antlr的grammar时,将原先单引号加上id的写法,直接变成对应的token的定义,并且加上对应的换行:
用正则:
'(\w+)'\s*\|?\s*
\1\t:\t'\1';\r\n
将:
 |
替换为:
 |
很明显,还是很帅的,一次性搞定去除引号,加上对应的token的定义,再加上对应的回车换行。
正则,就是高效率啊。
例 3.17. Notepad++正则表达式替换举例:dd宏定义中去除多国语言字符串
在折腾HART的EDDL文件时,将宏定义中多国语言字符串去除掉:
用正则:
("[^"]+")\s*"\|\w{2}\|""[^"]+"
\1
将:
 |
替换为:
 |
如此,省去了,一点点选择和删除对应的内容了。
例 3.18. Notepad++正则表达式替换举例:C宏定义转java变量定义
在折腾
【记录】给usb-serial-for-android中的Silicon Labs的CP2102中添加RTS和DTR的支持
时,将C语言中的宏定义,转换为对应的Java中的变量定义:
用正则:
#define\s+(\w+)\s+(0x\d+)
private static final int \1 = \2;
将:
 |
替换为:
 |
很是方便好用,不用自己一点点改代码了。
例 3.19. Notepad++正则表达式替换举例:docbook的link变bibliomixed
在写
时,将别的某个docbook的xml中已有的帖子链接,都是link形式的,去转换为bibliomixed的形式。
本来都是手动一点点复制粘贴,然后再修改ref的xml:id的值的,很是麻烦,现在去用正则,一次性处理:
.+(<link\s+xl:href="http://.+?/([\w_]+)/?">[^<>]+?</link>).+
<bibliomixed xml:id="ref.\2">\r\n <bibliosource>\1</bibliosource>\r\n <author>Crifan Li</author>\r\n</bibliomixed>
将:
 |
替换为:
 |
就可以免去手动的麻烦了。
对应的,就是把之前的link内容:
<para><link xl:href="http://www.crifan.com/summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input/">【整理】关于antlr中出错"The following token definitions can never be matched because prior tokens match the same input"的原因和解决思路</link></para>
就变成了:
<bibliomixed xml:id="ref.summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input">
<bibliosource><link xl:href="http://www.crifan.com/summary_antlr_the_following_token_definitions_can_never_be_matched_because_prior_tokens_match_the_same_input/">【整理】关于antlr中出错"The following token definitions can never be matched because prior tokens match the same input"的原因和解决思路</link></bibliosource>
<author>Crifan Li</author>
</bibliomixed>
之后,就可以直接拷贝bibliomixed的内容,到对应的docbook的book中的reference.xml中的bibliography中去了。
搜索(S) ⇒ 查找 Ctrl+F,可以打开查找对话框。
然后选择某个单词,短语等内容后,点击计数,就可以实现统计所选内容在当前文件出现的次数:
 |
即,计数的功能。
之前其实是一直没有注意有此功能的。
直到有一天,在某次开发过程中,想要知道当前文件,包含了多少个该docbook单词,即该单词出现了多少次,
而一般方法是用上下查找的办法,一点点自己去数,
而后来发现,Notepad++中的查找对话框中,有个”计数“按钮。
当你双击选择某个单词后,本身Notepad++就会自动帮你高亮对应单词,
然后再点击”计数“,就可以弹出对话框显示统计的结果,显示该单词一共出现了多少次。
然后不得不感叹,Notepad++真是很是方便使用啊。
下面来解释Notepad++中的强大且好用的列编辑功能。
普通编辑器,编辑文本的时候,选中一部分内容,都是在一行或多行的范围内操作,从左到右的,所以,可以看做是行模式。
与此相对应的,就是上下方向的列模式了。
进入列模式后,操作顺序和范围,是在所选范围内,从上到下的,比如全部插入某些字符等等,是在所选的列模式操作区域内,所涉及的每一行,都对应的插入这些字符。
当有些高级的操作,需要对不同的列,同时进行编辑的话,那么列编辑模式,就非常有用了。
在Notepad++中,按住Alt键之后,就处于列(编辑)模式了。
比如,按住Alt键,此处从上到下,选择多列:
 |

例 3.21. 列编辑:删除多行内容
然后也可以同时删除多行内容:
先按住Alt键,选后同时选取多列:
 |
然后松掉Alt键,点击右键选择删除,或者直接按键盘上面的Delete键,都可以实现删除所选的多行中对应部分的内容:
 |
例 3.22. 列编辑:多行中插入相同或不同的内容
进入列编辑模式后,除了可以手动输入内容外,也可以通过插入,实现输入多行内容:
按住Alt键进入列编辑模式后:
 |
然后松掉Alt键,点击 编辑(E) ⇒ 列编辑 Alt+C:
 |
然后在“插入文本”处,填写你所要插入的内容:
 |
此处填入想要插入的内容,即可同时插入多行内容:
 |
同样,可以看到,上面还有个“插入数字”的功能,可以插入自己所想要的某种序列的数字:
 |
然后就可以看到插入了想要的数字了:
 |
虽然上面只是一些基本操作,但是对于很多人,如果需要用到此功能,也会觉得很方便了。
其实,列编辑的功能的好处,在于相对更加复杂一点的用法。
下面就介绍一下,我之前所遇到的情况,以及如何利用列编辑模式,来提高工作效率的:
例 3.23. 列编辑:同时复制和粘贴多列
比如,我之前,需要得到这样的xml内容:
 |
即,需要在多个entry中,一点点输入对应的数字和字母。
而数据来源,是来自另外已有的word文档中的表格:
 |
对此,一般传统的办法,那无外乎,一个个数字,和字母的从word中拷贝,然后粘贴到xml文件中对应的两个entry的位置中去。
此种方法,效率及其低下不说,还很容易出错,所以肯定不是好办法。
但是如果不会用列编辑的话,那么好像也只能用此很笨的办法,慢慢的去拷贝粘贴了。
下面就来看看,如果使用Notepad++的列编辑,是如何提高效率和准确度的:
首先当前是在目标xml文件中,已经有了对应的entry了:
然后,是想要通过列编辑的复制与粘贴,实现将word中对应表格中的内容,一列列粘贴过来的。
但是,之前由于对于列模式编辑不是很熟悉,导致直接从word中选中一列:
 |
然后在Notepad++中先进入列编辑模式:
 |
再直接去用Ctrl+V去粘贴,结果却只是粘贴到第一个entry中,而不是整个列分别粘贴到对应的位置:
 |
后来才知道,原来应该这么做:
同样先是去word中拷贝对应的列的内容:
|
然后在Notepad++中,新建一个页面,将拷贝的内容,粘贴到新建页面中:
 |
然后再用列模式去选取此部分内容:
 |
然后Ctrl+C复制所选内容,再回到要粘贴的地方,同样先是进入列模式:
|
然后再按Ctrl+V,这样才可以正确的将通过列模式选取的内容通过(Ctrl+V)粘贴到列模式所选取的范围内,即所选取的每一行的内容,粘贴到目标的每一行的位置:
 |
|
列模式粘贴的时候,会自动帮你去掉所选内容中的空白处,即可以调整被粘贴后的内容的宽度 | |
|---|---|---|
|
此处,可以注意到,原先列模式去选取内容的时候,0到9的那些行,(至少显示出来的效果中)是包含了多余的空格的:
以及0a到1f的行,是正常选取的全部内容,不包含空白的。 而粘贴出来的效果,可以看到,对应的0到9的行,是没有多余的空格,是一个字符的宽度的,没有被变成2个字符的宽度:
即,列编辑的时候,所选择的内容中,显示出来的效果中,好像是包含了空格,实际没有,所以在粘贴出来后,不会多余出于的空格的。 话句话说,列编辑模式下,选取内容,和粘贴内容,会自动帮你计算好对应的内容的,不会(像我以为的)多余的插入(那些在选取时显示出来的多余的)空格的 所以,这方面,个人觉得,其做得还是很人性化,或者说很符合用户需求的。 |


按照上述方法,你可以去接着一列列的,去粘贴word中别的列的内容。
但是,如果你接着这么做的话,你却发现,有些问题了。
因为经过上面第一列的粘贴,上面的0到9的那些行是一个字符宽度,而0a到1f却是2个字符宽度,这导致接下来的想要选取第二列的所有的entry,以进入列编辑模式的话,就无法正确全部选择对应的位置了:
 |
即,0到9列,是可以正确的选择了两个"<entry>"中间的,但是0a到1f的列,却都选择了y和>之间了,位置错了。
如此,想要接着实现列拷贝粘贴的话,一般人所能想到的,那就只是,先拷贝粘贴0到9列的,然后再拷贝粘贴0a到1f列的。
如果这么做的话,其对于此处只是被分为2个不同的列的位置去操作,也还算能接受。
但是如果被粘贴的内容,像后面的同一列中,既有1个字符宽度的,又有2个和3个字符宽度的,甚至其他更多字符的,那么一个完全的列,就被分为多个不连续的,可供列编辑操作的列了。
那结果就又几乎回到了之前的手工慢慢的复制粘贴的效果了。
所以,还是要找到更好的解决办法,尽量实现尽可能多的列,都实现一次性的列操作,这样才能真正提高效率。
后来,偶发现了一个办法,那就是,可以先操作左右边的列,然后依次向左处理每一列,这样就可以避免此问题。
之所以想到如此去做,是因为,右边的列,即使每一列的内容宽度不同,但是不会影响到左边的列的对齐,所以,就可以规避此问题了。
其具体做法很简单,只是换个顺序处理而已:
在word中,先复制最后一列的内容:
 |
同样的,粘贴到新建的Notepad++的页面中,并以列模式去选取该内容:
 |
然后用快捷键Ctrl+C去复制此内容,再回到要粘贴的地方,先以列模式选择所要插入的位置:
 |
然后Ctrl+V去粘贴此内容:
 |
如此,就不会影响左边的列了。
然后依次方法,依次处理每一列。
不过,当你处理到40那列的时候,你会发现,有些内容,却折回到开始显示了,即内容显示出来,是换行的了:
 |
但是看起来也是不影响继续使用列模式的,但是当想要继续选择多列时,选中的效果却变成了隔行的效果:
 |
此处,看起来是隔行的列选择,实际仍是每个行的列选择,即,其实是不影响继续列操作的。
和上述的隔行选择的效果类似的,是处理到最后一列的时候:
 |
实际上,看起来“穿”过了字符串"entry",而实际上,是不影响的entry字符串内容的。
如此继续操作,就处理完毕所有的列了:
 |
这也就是我们最开始所看的效果。
而如此的列操作,其实只是对于每一列,去复制粘贴一下,就可以实现,整个列的内容录入了。
通过此列操作实现的多列同时录入,不仅效率很高,而且还不容易出错。
总之,有效利用列编辑模式,可以大幅度的提高做事情的效率和准确度。
代码折叠,即,Notepad++对于不同语言,在语法高亮基础上,还能检测出对应的C,Python等语言的单个的函数,xml等语言的标签,
然后对这些独立的代码部分,最开始端,有个加减号的可点击的小图标,对应的可以展开或折叠其对应的代码。
截图说明:

估计很多人可能和我最开始的想法一样,觉得此代码折叠功能,好像没啥实际用途。
直到有一天,我发现,代码折叠,至少对于更加清晰明确xml文件的架构和层次,有不小的帮助。
比如,我当前的xml文件,里面有很多个章节,很多行代码,而如果没有代码折叠,则每次定位到某个章节的时候,都需要找半天。
而有了代码折腾后,把其他暂时不关心的章节的内容,先折叠起来:
 |
这样,立刻就可以把几百行的内容,暂时隐藏起来,使得整个xml的架构层次,很清晰明了,方便后续的查看编辑相关的内容。
如此,越加发现,其实很多功能,真的得到你需要用到,才会发现如此的有用。
设置(T) ⇒ 首选项... ⇒ 备份 ⇒ 备份与自动完成 ⇒ 自动完成 ⇒ 勾选 "所有输入均启用自动完成","函数自动完成","输入时提示函数参数"
 |
我之前所用过的自动完成功能,至少包括:
-
docbook的自动完成的支持。各种标签(docbook中称为元素)的自动完成:

-
python的自动完成的支持,包括函数和库:

-
php中可以自动完成函数:

还有函数参数提示:

此自动完成的好处,还是很明显的:
至少不用让你完全记住每种语言的所有函数(关键字)的全部单词,只需要写出部分字母
剩下的字母就可以通过Notepad++帮你自动匹配,就可以通过上下键选择所需项,然后按Tab,实现自动补全了。
就不用全部一个个字母的输入了,还是很方便使用的。
|
Notepad++自动完成功能内在实现的逻辑 |
|---|---|
|
之前没太注意,所以也不太清楚,对于此自动完成的功能,到底是如何实现的,或者说,想要搞懂,Notepad++实现自动完成的大概逻辑是什么样的。 后来,才大概想明白: 因为在Notepad++在安装过程中,有个选项:Notepad++安装选项:Auto Complete Files 就是指的是自动完成的功能,需要支持哪些类型的文件。 此处,应该就是会去安装对应的数据库,然后对于打开的文件,通过文件名后缀(或者文件头的声明等),识别出当前文件的语言,比如c,Python,Docbook等, 之后,再根据当前所输入的字符,动态匹配当前语言的自动完成所涉及的数据库,显示出所匹配的函数,以及函数提示等。 至此,才清楚,其大概实现逻辑。 |
之前,是知道了有函数自动完成。不过后来,在折腾Sublime
【crifan推荐】一款相对不错的文本编辑器:Sublime Text 2
的过程中,发现其中有个很好用的功能:文件内的,函数,变量等内容的,自动完成。
之前不知道这个就个东东叫做,单词自动完成,现在才知道。
然后后来也发现了,Notepad++中,有个自动完成:
设置(T) ⇒ 首选项... ⇒ 备份 ⇒ 备份与自动完成 ⇒ 自动完成 ⇒ 勾选 "所有输入均启用自动完成","单词自动完成"
但是,由于当前所用的6.2.3中的版本的单次自动完成有bug,无法正常显示列表:
#4056 Word auto-completion is not working in NP++ 6.1.6 or late
使得无法使用。
但是巧的是,Notepad++最近又发布了6.2.3的版本,修复了此bug,所以,刚去更新了最新6.2.3,然后就可以实现单词的自动完成的效果了:
比如某个Python文件内的变量的自动完成:
 |
比如当前文件内部的,汉字都可以自动完成的:
 |
前面已经解释过了,在第 2.5 节 “Notepad++安装:选择组件”的时候,就有个参数选择,可以把Notepad++设置为默认HTML的查看器的:Notepad++安装选项:As default html viewer
这样,以后用浏览器查看某网页,想要查看其html源码的话,右键点击,选择 View Source:
 |
就可以用Notepad++来查看HTML源码了:
 |
可以看到,其显示出来的效果,没有HTML高亮,可以自己手动设置一下:
语言(L) ⇒ H ⇒ HTML
 |
就可以高亮的显示HTML文件了:
 |
将Notepad++用作为HTML默认编辑器,主要适合于网络相关开发人员。
Notepad++默认,也和其他编辑器一样,是不显示空格和TAB键的
,不过我最近在用Notepad++写Python脚本过程中,常需要显示空格键和TAB键
以避免两者混合缩进,所以去设置了,将空格键和TAB键也显示出来。
下面以某HTML源码为例:
视图(V) ⇒ 显示符号 ⇒ 显示空格与制表符
 |
这样,就可以将空格键显示出来了,效果是四个橘黄色的点点,TAB键是右向的橘黄色箭头。
就很方便的,很清楚的看到,哪些是空格,哪些是TAB了。
另外,可以根据需要,比如想要知道那些行,有回车换行,还是单个的回车,单个的换行等,可以设置将所有的字符都显示出来:
视图(V) ⇒ 显示符号 ⇒ 显示所有字符
 |
这样全部的回车换行符,CR和LF等,就都可以显示出来了。
例 3.24. Notepad++可以查看特殊字符的用途举例
有人也许会问,就算Notepad++能显示所有特殊字符,好像也没啥用啊。
那此处就给你举个实际我遇到的例子:
之前遇到的一个问题是,用python脚本导出某163博客的帖子为WXR(XML文件)
但是结果导入WXR到wordpress失败,最后找到原因是,WXR文件中存在一些控制字符,该WXR文件效果如下:
 |
其中包含很多DLE,ETX,EOT等控制字符,导致导入WXR到Wordpress失败。
而此时,就依靠了Notepad++的所能够查看到字符中的特殊的,不可显示的控制字符,才解决此问题的。
如果换做其他普通的编辑器,比如Notepad,则无法显示出对应的控制字符,也就无法找到原因,无法解决问题了。
所以,越加发现,Notepad++的功能,真的是太强大了。
Notepad++不仅可以实现第 3.10 节 “Notepad++支持显示回车符,换行符,TAB键,行首,行尾等特殊字符”,还可以实现插入特殊字符。
例 3.25. Notepad++可以插入特殊字符的用途举例
接着例 3.24 “Notepad++可以查看特殊字符的用途举例”继续说:
后来为了测试WXR中到底支持哪些控制字符
是不是所有的0-0x31都不支持,还是也支持一部分的控制字符,
这就需要输入这些不可显示的控制字符,用于代码测试。
然后才发现,原来Notepad++中,也是可以输入控制字符的:
编辑(E) ⇒ Character Panel
 |
然后就调出了ASCII Insertion Panel,显示了ASCII字符表,包括了控制字符:
 |
这样,双击ASCII Insertion Panel中任一(普通或控制)字符,比如DLE,DC1这两个控制字符,就可以插入对应的控制字符了。
而其他编辑器,好像没看到有这么好用的功能。
因此,不得不夸一句,Notepad++,真的是非常适合用来做文本编辑器,尤其是适合开发人员。

由于历史原因,导致Windows,Unix/Linux,Mac三者之间,对于文件中所用回车换行符,表示的方法,都不一样。
这就导致了很多人都会遇到回车换行符的困惑,和需要在不同格式间进行转换。
其中,关于回车换行符的详细解释,去看这里[13]
此处,介绍一下,如何通过Notepad++实现在这三者之间进行转换。








点击某个关键词后,会自动高亮显示其所匹配的键对:
 |
方便查看和编辑文件。
此功能很适合对于编辑xml,html等类型的文件,这样容易看清,哪个标签,关键字,所对应的关系。
另外,也适合用于查看代码中的,当前的代中括号,方括号,大括号所对应的那个括号在哪里:
 |
之前不了解,关于文件自动更新,原来也是可以根据需要设置不同更新模式的。
说个最实际的例子:
之前用写python脚本,在windows的cmd中输入脚本去执行,执行过程中,会生成一个log文件:xxx.log,
另外每次执行不同的命令,对应的log文件内容也会变化,
而该log文件以及对应的python脚本xxx.py文件,我都是用Notepad++打开的,
所以,执行完cmd中的python脚本后,想要回来再次去编辑xxx.py文件,就会先遇到,关于xxx.log被更新的提示:
 |
然后点击个yes,才能去编辑我想要编辑的xxx.py文件。
所以,每次都被这个提示框所打扰,觉得挺烦的。
后来,无意间,发现原来是可以取消此提示的:
设置(T) ⇒ 首选项... ⇒ 其他 ⇒ 自动检测文件状态,勾选 "启用", "自动更新文件"
 |
这样,每次xxx.log文件再被修改,就会自动更新内容,而没有了之前的跳出的那个对话框的提示了。
类似的,也可以通过勾选或取消”启用“,实现开启或关闭自动检测文件状态这个功能。
或者每次更新完文件,想要光标自动跳到文件末尾,那么就去选上"更新后定位到末位"。
设置(T) ⇒ 首选项... ⇒ 语言 ⇒ 标签设置,勾选 "以空格取代"
 |
这样,以后输入Tab键的时候就会自动以所设置的4个空格代替。
此功能的用途:
- 部分程序的需要
主要是有些情况下,比如写Python脚本的时候用到,以避免TAB键和空格键的混合缩进,其会导致Python 3.0等报错,而让输入的TAB键,自动变成空格键,则自动规避了此问题。
- 兼容不同平台
另外,此功能,也是出于兼容不同平台,TAB键的宽度不同的考虑
这样就可以避免不同平台下,不会因为TAB键是4个空格,还是2个空格等,而导致代码(文字)的对齐不匹配的现象了。
编辑(E) ⇒ 注释/取消注释 ⇒ 添加删除/单行注释 Ctrl+Q
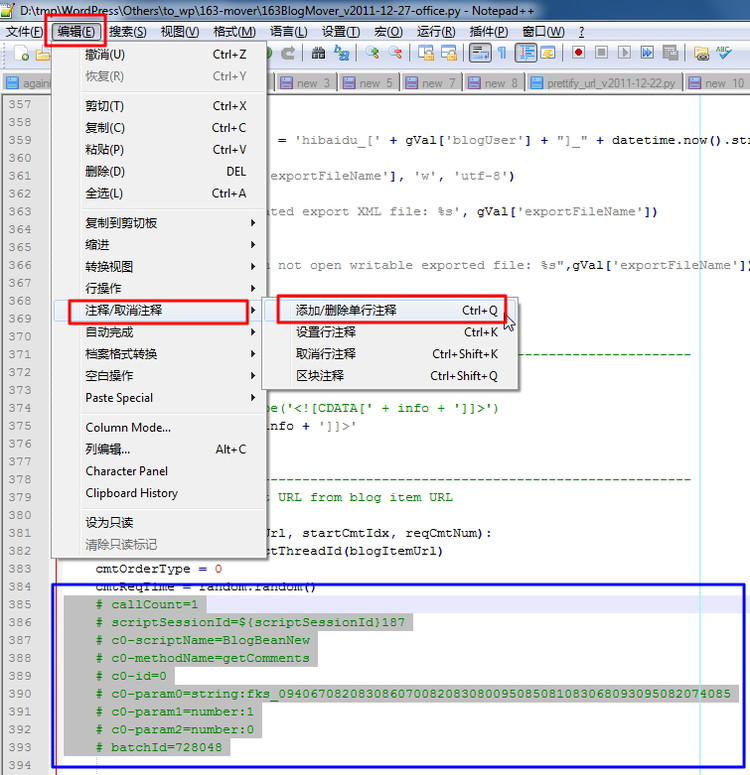 |
就可以实现对选中的多行Python代码,每行都添加对应的符号"#",实现对应的注释代码的功能了。
|
提示 | |
|---|---|---|
|
此功能,不仅方便一次性可以注释多行代码。更加强大的是,会根据不同的语言的代码,添加对应的注释前缀。 比如,Python语言,以井号"#"为前缀,表示注释,而c等语言,是以斜杠"/"为前缀,表示注释,而xml语言中,是以<!-- xxx -->表示对xxx进行注释,其都可以根据所识别出来的源码的类型,去添加相应的注释。 下面就是通过区块注释,实现对xml代码实现给一段代码,添加区块注释功能的:
添加注释后的效果:
|


在前面的安装过程中:Notepad++安装选项:Themes,已经介绍了其会安装一些主题。
此处,可以去:设置(T) ⇒ 语言格式设置...
 |
中,在“选择主题”部分,去设置不同的主题。
下面就来看看不同主题的效果如何:

















其他还有很多功能,由于个人觉得不是那么的重要,所以此处暂称其为小功能。
虽然此处称为小功能,但是真正等你需要用到的时候,也会发现,真的很贴心,很好用。
想要快速关闭某个文件,可以通过双击该文件的Tab:
 |
|
注意 |
|---|---|
|
不过需要注意的是,默认是关闭了此功能的,需要的话,去开启此功能: 设置(T) ⇒ 首选项... ⇒ 常用 ⇒ 标签栏 ⇒ 勾选 "双击关闭标签"
|



设置(T) ⇒ 首选项... ⇒ 打印 ⇒ 勾选 "打印行号"
这样,再去:文件 ⇒ 打印
 |
选择一个pdf打印机(BullZip PDF Printer),然后打印:
 |
输出的pdf中,就包括了行号了:
 |
|
提示 |
|---|---|
| 关于pdf打印机,不了解的可参考:[15] |
和Ultra Editor类似,Notepad++在编辑一个文件后,默认会生成.bak文件的。
不过对于notepad++来说,此功能默认是关闭的。需要的话可以去开启:
设置(T) ⇒ 首选项... ⇒ 备份 ⇒ 备份与自动完成 ⇒ 勾选 "简单备份"
 |
可见,另外还有禁止和复杂备份,可根据自己的实际情况而设置。
选择一段文字后,然后:运行(R) ⇒ Google Search Alt+F2
 |
就会调用google去搜索选定文字了:
 |
与google search的,还有类似的:
- Get php help Alt+F1: 调用php帮助,对查找php函数等有帮助
- Wikipedia Search :调用维基百科搜索选定文字
在同一界面的其他功能有:
- Open current dir cmd: 打开cmd且定位到当前文件夹,功能等价于:[14]
- Open cotaining folder: 打开当前文件所在文件夹


如果在查看文件的时候,暂时觉得需要将某些行隐藏掉,在需要的时候再正常显示,就可以先选中那些行,然后:
视图(V) ⇒ 隐藏行 Alt+H
 |
就可以实现暂时隐藏对应的行了:
 |
很明显,点击对应的蓝色三角型,就又可以恢复显示该行了。



设置(T) ⇒ 首选项... ⇒ 编辑 ⇒ 列边界设置 ⇒ 勾选 "显示列边界"和"边界线模式"
 |
此时,文件中,宽度100的位置,就会有对应的一条竖线提示:
 |
这样,如果代码是否超过便捷,就很容易看清了。
|
列边界功能的由来 |
|---|---|
|
此功能的出现,主要是由于对于写代码的人,一个良好的习惯是,不要让代码太长。 一般的列宽限制,都定位80个字符。 超过的部分的代码,应该养成好习惯,以多行显示。 |
可以看到,另一种配置是把超过列边界的内容加上一定的底色,效果如下:
 |
如果需要的话,可以设置文字右对齐。
默认的快捷键是:Ctrl+Alt+R
设置(T) ⇒ 管理快捷键... ⇒ Menu ⇒ 文字方向从右向左
 |
 |
想要取消右对齐,可以使用快捷键Ctrl+Alt+L,就可以恢复到默认的左对齐了。


用Notepad++自带的功能,和其他第三方的插件,可以实现,针对不同的格式的文件的格式化,下面依次分别介绍:

Notepad++中,支持拷贝单行或选中的多行的功能
对应的快捷键是:Ctrl+D
之前,想要复制某一行,或某几行的话,都是:
用鼠标选中某行或某几行,然后Ctrl+C
然后光标再点击到下一行的行首,或者是多行的后面,
再去用Ctrl+V去粘贴
而后来,发现了Notepad++中,有个Ctrl+D的快捷键,
可以更加方便的实现同样的效果:
Ctrl+D支持:
对于你当前所在的行,直接去用Ctrl+D
然后就可以复制出当前行的内容
比如,就在此刻,写docbook的xml源码时,对于:
<para></para>
鼠标放在中间:
 |
然后按Ctrl+D,就可以直接再复制出当前行了:
 |
如此,一下子,想要多复制个10行8行的,多按几次Ctrl+C就可以了。
就免去了之前繁琐的:赋值,移动光标,粘贴,的复杂操作了。
