折腾:
【部分解决】Python中实现多线程或多进程中的单例singleton
期间,需要去在用gunicorn去部署Flask的情况下,对于基于threads的gunicorn,多个worker:
<code>[2018-08-29 17:14:57 +0800] [19328] [INFO] Starting gunicorn 19.9.0 [2018-08-29 17:14:57 +0800] [19328] [INFO] Listening at: http://0.0.0.0:32851 (19328) [2018-08-29 17:14:57 +0800] [19328] [INFO] Using worker: threads [2018-08-29 17:14:57 +0800] [19342] [INFO] Booting worker with pid: 19342 [2018-08-29 17:14:58 +0800] [19344] [INFO] Booting worker with pid: 19344 [2018-08-29 17:14:58 +0800] [19347] [INFO] Booting worker with pid: 19347 [2018-08-29 17:14:58 +0800] [19349] [INFO] Booting worker with pid: 19349 [2018-08-29 17:14:58 +0800] [19353] [INFO] Booting worker with pid: 19353 [2018-08-29 17:14:58 +0800] [19356] [INFO] Booting worker with pid: 19356 [2018-08-29 17:14:58 +0800] [19357] [INFO] Booting worker with pid: 19357 [2018-08-29 17:14:58 +0800] [19360] [INFO] Booting worker with pid: 19360 [2018-08-29 17:14:58 +0800] [19362] [INFO] Booting worker with pid: 19362 [2018-08-29 17:55:09 +0800] [25949] [INFO] Starting gunicorn 19.9.0 [2018-08-29 17:55:09 +0800] [25949] [INFO] Listening at: http://0.0.0.0:32851 (25949) </code>
中,如何共享数据,或者如何实现多线程/进程的单实例:
python gunicorn threads
Gunicorn’s settings – workers vs threads · Issue #1045 · benoitc/gunicorn
Gunicorn Workers and Threads – Stack Overflow
python – How to run Flask with Gunicorn in multithreaded mode – Stack Overflow
淺談 Gunicorn 各個 worker type 適合的情境 – Genchi Lu – Medium
python gunicorn multiple worker singleton
说是gunicorn有个preload_app:可以实现app运行之前,只初始化一次
Python class/singleton interaction with Django and gunicorn – Stack Overflow
说是:每个process进程有自己独立的内存,所以会有自己的实例
-》建议换用数据库或换成等方式去实现:多进程共享
python – Access app singleton instance in wsgi application – Stack Overflow
Django – gunicorn – App level variable (shared across workers) – Stack Overflow
Singletons and their Problems in Python | Armin Ronacher’s Thoughts and Writings
Shared data with multiple gevent workers · Issue #1026 · benoitc/gunicorn
“If you want to do this use case, I recommend you to use Redis or something like that between workers.”
还是建议多个worker之间共享数据用:redis
python multiple process singleton
python singleton into multiprocessing – Stack Overflow
说是:
最好是单独制定一个线程去处理数据,然后别人线程去从改线程去获取即可实现共享。
其中包括用IPC去通信获取数据。
另外方案:多个线程 share 数据
17.2. multiprocessing — Process-based parallelism — Python 3.7.0 documentation
python – Shared-memory objects in multiprocessing – Stack Overflow
flask gunicorn multiprocessing share data
Settings — Gunicorn 19.9.0 documentation
“preload_app
* –preload
* False
Load application code before the worker processes are forked.
By preloading an application you can save some RAM resources as well as speed up server boot times. Although, if you defer application loading to each worker process, you can reload your application code easily by restarting workers.”
Handle multiprocess setups using preloading and equivilents · Issue #127 · prometheus/client_python
I have never found a good example of a Python web server that provides some mech… | Hacker News
Python Multithreading Tutorial: Concurrency and Parallelism | Toptal
python – Sharing static global data among processes in a Gunicorn / Flask app – Stack Overflow
“Gunicorn can work with gevent to create a server that can support multiple clients within a single worker process using coroutines, that could be a good option for your needs.”
说是:其实可以换基于gevents的gunicorn,然后只是一个worker process然后内部多个coroutine
python – Gunicorn shared memory between multiprocessing processes and workers – Stack Overflow
python – Sharing Memory in Gunicorn? – Stack Overflow
如果只是初始化一次,可以考虑用gunicorn的:preload_app
也可以用:memory-mapped file
gevent with gunicorn
单process
python – Sharing static global data among processes in a Gunicorn / Flask app – Stack Overflow
用多线程,包括一个server和多个client,client从server中获取/更新数据,中间用IPC通信
用redis保存/更新数据
目前看起来,貌似用gunicorn的gevent最省事?
其次是mmap file
不过,先去改回之前的配置:
<code>import multiprocessing worker_class = 'sync' #默认的是sync模式 workers = multiprocessing.cpu_count() * 2 + 1 #进程数 threads = 2 #指定每个进程开启的线程数 </code>
用于去确认之前别人用:
<code>
class Singleton(type):
"""
reference: https://stackoverflow.com/questions/31875/is-there-a-simple-elegant-way-to-define-singletons
"""
_instances = {}
def __call__(cls, *args, **kwargs):
if cls not in cls._instances:
cls._instances[cls] = super(
Singleton, cls).__call__(*args, **kwargs)
return cls._instances[cls]
class SearchBasedQA(metaclass=Singleton):
...
</code>对于gunicorn的多worker/多线程中,是否能实现单例
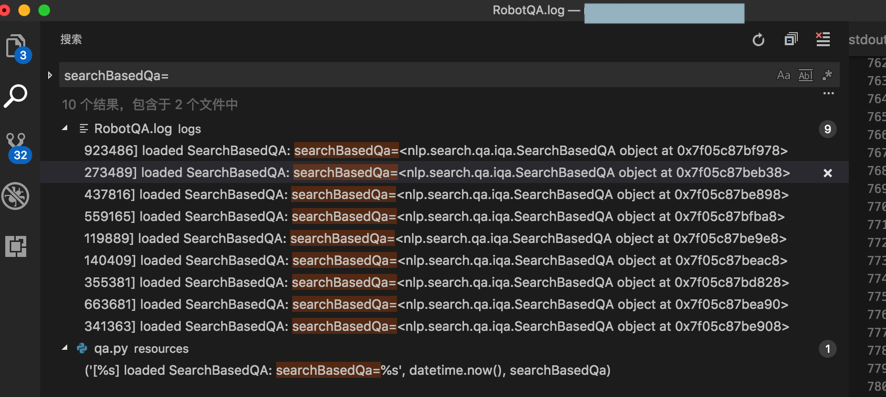
结果也是不行的:
<code>[2018-08-30 09:54:41,923 INFO qa.py:31 <module>] [2018-08-30 09:54:41.923486] loaded SearchBasedQA: searchBasedQa=<nlp.search.qa.iqa.SearchBasedQA object at 0x7f05c87bf978> [2018-08-30 09:54:46,273 INFO qa.py:31 <module>] [2018-08-30 09:54:46.273489] loaded SearchBasedQA: searchBasedQa=<nlp.search.qa.iqa.SearchBasedQA object at 0x7f05c87beb38> </code>
然后再去尝试gunicorn的gevent方法:
【已解决】用gunicorn的gevent解决之前多worker多Process线程的单例的数据共享
期间,有点理解逻辑了:
gunicorn中的worker=process=进程:相对最消耗资源
thread=线程:(内存等)资源消耗比process小
coroutine=协程:资源消耗比thread小
期间去:
【已解决】Flask的Celery的log中显示:Stale pidfile exists – Removing it和指定celerybeat.pid位置
虽然解决问题了,但是又出现其他相关的问题: