折腾:
期间,现在需要去Django中自定义返回分页数据,以便于前后端搭配,实现返回需要的数据
所以,现在就是去想办法让返回的数据,在当传入:
scripts/?page=2&page_size=20
时,不是返回所有的数据,而只是返回第一页的20个的数据
所以去后台Django中,去改代码
后端代码原先是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | def list(self, request, *args, **kwargs): """ 获取 script list,取 author=request.user。按历史记录 version 最新的一个script, 组成列表 """ logger.info("ScriptViewSet list: request=%s", request) filterAuthorList = [] reqUser = request.user logger.info("reqUser=%s", reqUser) if reqUser.is_superuser : # is superuser, means get all script list, so not filter himself filterAuthorList = [] else: filterAuthorList = [reqUser] # if pass in author_id or group_id, take precedence for filter author over request user authorId = request.query_params.get('author_id', '') groupId = request.query_params.get('group_id', '') logger.info("authorId=%s, groupId=%s", authorId, groupId) if authorId: passInAuthor = User.objects.get(pk=authorId) logger.info("passInAuthor=%s", passInAuthor) if passInAuthor: filterAuthorList = [passInAuthor] elif groupId: passInGroup = FunctionGroup.objects.get(pk=groupId) logger.info("passInGroup=%s", passInGroup) if passInGroup: membersRelatedManager = passInGroup.members logger.info("membersRelatedManager=%s", membersRelatedManager) logger.info("type(membersRelatedManager)=%s", type(membersRelatedManager)) memberList = membersRelatedManager.all() logger.info("memberList=%s", memberList) filterAuthorList = memberList logger.info("len=%d, filterAuthorList=%s", len(filterAuthorList), filterAuthorList) userFilter = Q() if filterAuthorList: userFilter = Q(author__in=filterAuthorList) logger.info("userFilter=%s", userFilter) filterByUserScriptList = Script.objects.filter(userFilter) logger.info("filterByUserScriptList=%s", filterByUserScriptList) filterByUserScriptListLen = len(filterByUserScriptList) logger.info("filterByUserScriptListLen=%s", filterByUserScriptListLen) filter_condition = self.generateQueryFilterCondiction(request) logger.info("filter_condition=%s", filter_condition) result = [] historyIdList = [] for curScriptIdx, singleScript in enumerate(filterByUserScriptList): logger.info("---[%d] singleScript=%s", curScriptIdx, singleScript) scriptHistoryId = singleScript.history_id logger.info("scriptHistoryId=%s", scriptHistoryId) if scriptHistoryId not in historyIdList: historyIdList.append(singleScript.history_id) logger.info("historyIdList=%s", historyIdList) historyIdListLen = len(historyIdList) logger.info("historyIdListLen=%s", historyIdListLen) for curHisotryIdIdx, eachHistoryId in enumerate(historyIdList): logger.info("===[%d] eachHistoryId=%s", curHisotryIdIdx, eachHistoryId) history = History.objects.get(pk=eachHistoryId) logger.info("history=%s", history) orderedScriptAllHistory = history.script_history.all().order_by('version') logger.info("orderedScriptAllHistory=%s", orderedScriptAllHistory) lastHistory = orderedScriptAllHistory.last() logger.info("lastHistory=%s", lastHistory) result.append(lastHistory.id) logger.info("result=%s", result) resultLen = len(result) logger.info("resultLen=%s", resultLen) queryset = Script.objects.filter(pk__in=result).filter(filter_condition).order_by('-created_at') logger.info("queryset=%s", queryset) page = self.paginate_queryset(queryset) logger.info("page=%s", page) serializer = ScriptSerializer(queryset, many=True) logger.info("after ScriptSerializer serializer=%s", serializer) serializedData = serializer.data logger.info("serializedData=%s", serializedData) respData = None if page is not None: respData = self.get_paginated_response(serializedData) else: respData = Response(serializedData) logger.info("respData=%s", respData) return respData |
现在要去改为支持传入的page和pagesize,返回对应page的值
经过调试发现返回的:
1 2 | INFO|20180810 17:22:02|views:list:186|serializedData=[OrderedDict([('id', 'cb54d47d-6e9c-4ec2-8666-eb97df30e654'), ('place', 'cort'), ('title', 'play body'), ('topic', 'Shopping'), ('second_level_topic', 'cake shop'), ('age_start', 3), ('version', 1), ('age_end', 5), ('author', 'Maggie'), ('joinedScriptGroup', {'groupId': 5, 'groupName': 'maggie剧本组'}), ('publish_status', '未发布'), ('edit_status', '未提交'), ('review', None), ('dialog_count', 6), ('created_at', '2018-08-10 14:42:01'), ('updated_at',... |
就是一个数组,然后调用了:self.get_paginated_response
所以要去搞清楚:get_paginated_response
Django get_paginated_response
现在需要实现:
返回的数据中包含:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | { "totalCount": 519, "currentPageCount": 20, "currentPageNumber": 4, "maxPageNumber": 26, "next": "https://api.example.org/accounts/?page=5", "previous": "https://api.example.org/accounts/?page=3", "results": [ {}, {}, {} ]} |
而现有的pagination的class是:
/apps/core/pagination.py
1 2 3 4 5 6 | from rest_framework.pagination import PageNumberPaginationclass StandardResultsSetPagination(PageNumberPagination): page_size = 20 page_size_query_param = 'page_size' max_page_size = 1000 |
需要去改造
且只返回当前页的数据
想要参考代码去自定义,但是需要获取当前page的值
搜到paginator去参考代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | page = request.query_params.get('page', 1) page_size = request.query_params.get('page_size', 20) p = Paginator(file_list, page_size) count = p.count current_page = p.page(page) if current_page.has_next(): next = api_url + str(current_page.next_page_number()) else: next = None if current_page.has_previous(): previous = api_url + str(current_page.previous_page_number()) else: previous = None current_page_object = current_page.object_list format_current_page_object = [] for j in current_page_object: item = {} item['id'] = j[0] item['name'] = j[1] format_current_page_object.append(item) return Response({ "count": count, "next": next, "previous": previous, "results": format_current_page_object }, status=status.HTTP_200_OK) |
去找找如何写代码,获取current的page
django pagination get current page number
实在不行,就自己参考上面的自己去返回自己要的效果
【已解决】Django中获取当前配置的参数出错:AttributeError dict object has no attribute
然后想要通过:
/apps/core/pagination.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | from rest_framework.pagination import PageNumberPaginationfrom rest_framework.response import Responseimport logginglogger = logging.getLogger('django')class StandardResultsSetPagination(PageNumberPagination): page_size = 20 page_size_query_param = 'page_size' max_page_size = 1000class CustomPagination(PageNumberPagination): page_size = 20 page_size_query_param = 'page_size' max_page_size = 1000 def get_paginated_response(self, data, curPageNum): # respDict = { # 'next': self.get_next_link(), # 'previous': self.get_previous_link(), # 'count': self.page.paginator.count, # 'results': data # } logger.info("CustomPagination get_paginated_response: self=%s,data=%s,curPageNum=%s", self, data, curPageNum) logger.info("type(self)=%s", type(self)) logger.info("type(data)=%s", type(data)) logger.info("self.page=%s", self.page) logger.info("self.page.paginator=%s", self.page.paginator) totalCount = self.page.paginator.count logger.info("totalCount=%s", totalCount) maxPageCount = self.page.paginator.num_pages logger.info("maxPageCount=%s", maxPageCount) curPage = self.page.paginator.page(curPageNum) logger.info("curPage=%s", curPage) logger.info("type(curPage)=%s", type(curPage)) curPageItemList = curPage.object_list logger.info("curPageItemList=%s", curPageItemList) currentPageCount = len(curPageItemList) logger.info("currentPageCount=%s", currentPageCount) nextPageUrl = self.get_next_link() previousPageUrl = self.get_previous_link() respDict = { "totalCount": totalCount, "maxPageCount": maxPageCount, "currentPageNumber": curPageNum, "currentPageCount": currentPageCount, "next": nextPageUrl, "previous": previousPageUrl, "results": curPageItemList } return Response(respDict) |
然后去调用:
apps/script/views.py
1 2 3 4 | def list(self, request, *args, **kwargs): if paginatedQueryset is not None: # respData = self.get_paginated_response(serializedData) respData = self.get_paginated_response(serializedData, page) |
结果提示出错:
1 2 3 | File "/Users/crifan/dev/dev_root/company/xxx/projects/xxx/server/xxx/apps/script/views.py", line194, in list respData = self.get_paginated_response(serializedData, page)TypeError: get_paginated_response() takes 2 positional arguments but 3 were given |
因为是继承的函数只有2个参数:
/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rest_framework/generics.py
1 2 3 4 5 6 7 8 | class GenericAPIView(views.APIView): def get_paginated_response(self, data): """ Return a paginated style `Response` object for the given output data. """ assert self.paginator is not None return self.paginator.get_paginated_response(data) |
所以没法添加当前page的number
感觉只能放弃这条路。
django pagination return current page data
好像只能用Paginator只能去生成结果了?
django paginate current page data
好像自定义Pagenation的类中,可以获取request?
这样就可以获取page参数了。
去试试
然后发现了:
/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/site-packages/rest_framework/generics.py
1 2 3 4 5 6 7 | def paginate_queryset(self, queryset): """ Return a single page of results, or `None` if pagination is disabled. """ if self.paginator is None: return None return self.paginator.paginate_queryset(queryset, self.request, view=self) |
即:paginate_queryset带了self.request-》可以获取到page参数的
不过还是之前的代码,发现在CustomPagination的get_paginated_response中,是可以获得当前page的:
1 2 3 4 5 6 | INFO|20180810 21:51:34|pagination:get_paginated_response:28|type(self)=<class 'apps.core.pagination.CustomPagination'>INFO|20180810 21:51:34|pagination:get_paginated_response:29|type(data)=<class 'rest_framework.utils.serializer_helpers.ReturnList'>INFO|20180810 21:51:34|pagination:get_paginated_response:31|self.page=<Page 1 of 26>INFO|20180810 21:51:34|pagination:get_paginated_response:32|self.page.paginator=<django.core.paginator.Paginator object at 0x109bb1e48>INFO|20180810 21:51:34|pagination:get_paginated_response:35|totalCount=519INFO|20180810 21:51:34|pagination:get_paginated_response:37|maxPageCount=26 |
那么后面就可以去只返回当前page的数据了。
而当前的page页数,可以通过:
“Attributes¶
Page.object_list¶
The list of objects on this page.
Page.number¶
The 1-based page number for this page.
Page.paginator¶
The associated Paginator object.”
的.number去获得
结果返回:
1 2 3 4 5 6 7 8 9 10 11 12 | curPageItemList = curPage.object_listlogger.info("curPageItemList=%s", curPageItemList) respDict = { "totalCount": totalCount, "maxPageCount": maxPageCount, "currentPageNumber": curPageNum, "currentPageCount": currentPageCount, "next": nextPageUrl, "previous": previousPageUrl, "results": curPageItemList } |
结果报错:
1 2 3 | File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/json/encoder.py", line 180, in default o.__class__.__name__)TypeError: Object of type 'Script' is not JSON serializable |
而改为:
1 2 3 4 | curPageItemList = datalogger.info("curPageItemList=%s", curPageItemList)currentPageCount = len(curPageItemList)logger.info("currentPageCount=%s", currentPageCount) |
结果虽然没报错,又是回到了之前:返回了所有的数据
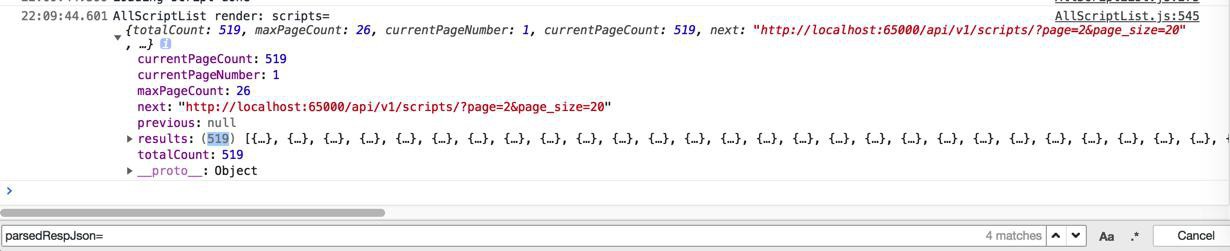
而如果想要在get_paginated_response中调用此处的
1 2 3 4 | serializer = ScriptSerializer(queryset, many=True)logger.info("after ScriptSerializer serializer=%s", serializer)serializedData = serializer.datalogger.info("serializedData=%s", serializedData) |
去序列化-》则又会出现:
不知道实际上是哪个类的Serializer
而且本身很麻烦,干脆直接放弃get_paginated_response,自己用Paginator就好了
【总结】
目前把代码改为:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 | from django.core.paginator import Paginatorfrom rest_framework.response import Response serializer = ScriptSerializer(queryset, many=True) logger.info("after ScriptSerializer serializer=%s", serializer) serializedData = serializer.data logger.info("serializedData=%s", serializedData) # respDict = None # if paginatedQueryset is not None: # respDict = self.get_paginated_response(serializedData) # # respDict = self.get_paginated_response(serializedData, page) # else: # respDict = Response(serializedData) # logger.info("respDict=%s", respDict) # return respDict curPaginator = Paginator(serializedData, page_size) logger.info("curPaginator=%s", curPaginator) totalCount = curPaginator.count logger.info("totalCount=%s", totalCount) maxPageCount = curPaginator.num_pages logger.info("maxPageCount=%s", maxPageCount) curPageNum = page logger.info("curPageNum=%s", curPageNum) curPage = curPaginator.page(curPageNum) logger.info("curPage=%s", curPage) logger.info("type(curPage)=%s", type(curPage)) curPageItemList = curPage.object_list logger.info("curPageItemList=%s", curPageItemList) currentPageCount = len(curPageItemList) logger.info("currentPageCount=%s", currentPageCount) # nextPageUrl = self.get_next_link() # previousPageUrl = self.get_previous_link() nextPageUrl = None previousPageUrl = None respDict = { "totalCount": totalCount, "maxPageCount": maxPageCount, "pageSize": page_size, "currentPageNumber": curPageNum, "currentPageCount": currentPageCount, "next": nextPageUrl, "previous": previousPageUrl, "results": curPageItemList } return Response(respDict, status=status.HTTP_200_OK) |
可以对于:
127.0.0.1 – – [10/Aug/2018 22:39:20] “GET /api/v1/scripts/?page=3&page_size=20 HTTP/1.1” 200 –
返回:
当前页,只有20个数据:
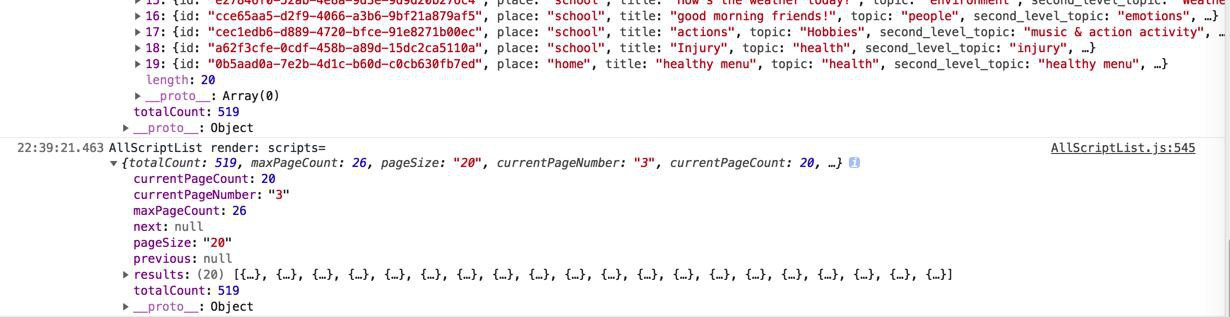
而不是所有的数据。
暂时凑合满足需求了。
转载请注明:在路上 » 【已解决】Django中如何自定义返回分页数据