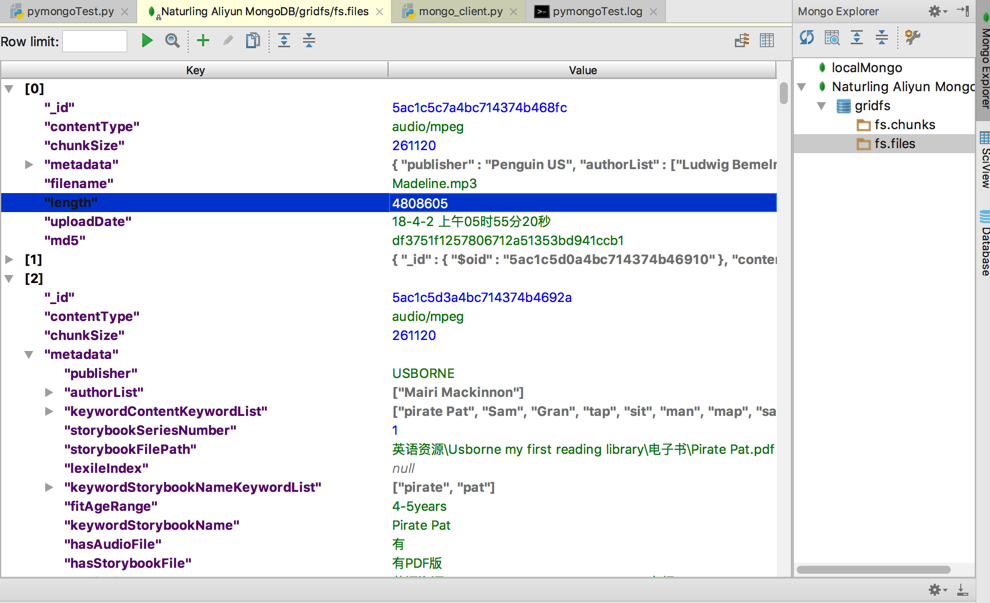
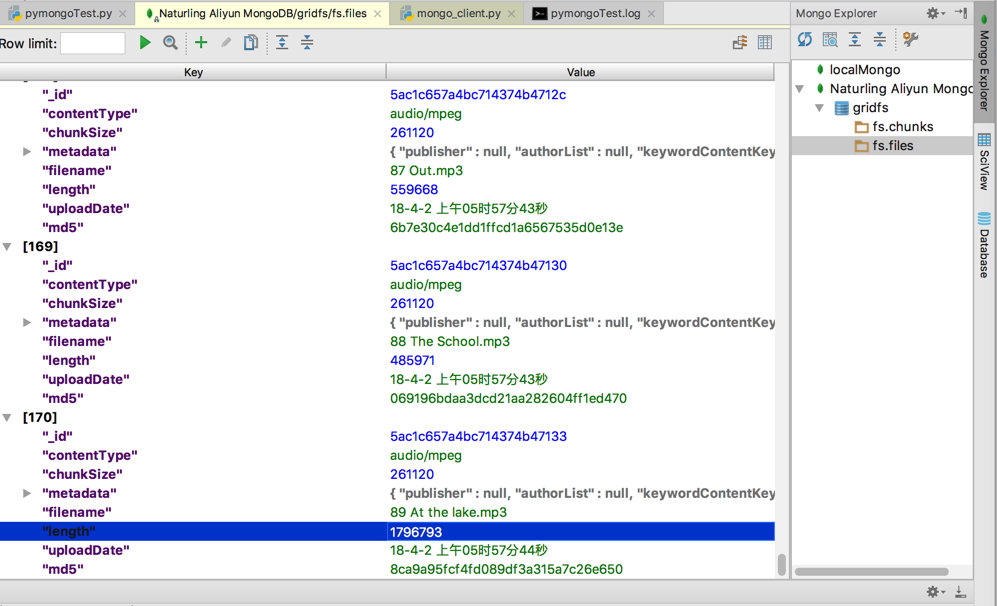
折腾:
期间,已经本地保存完毕了,把excel中提取出来的音频文件名,加上前缀,得到全部完整路径,保存到GridFS中去,一共171个,数据共700多MB
现在需要的是:
如何Mac本地写代码,连接远程的MongoDB数据库,把文件数据存储到远端GridFS中。
连接远程mongodb
使用MongoDB命令连接远程服务器的MongoDB数据库 – CSDN博客
使用MongoDB命令连接远程服务器的MongoDB数据库 – MongoDB频道_MongoDB基础_MongoDB教程_nosql – 360sdn.com_专业优秀的程序员网上知识家园
好像给出的例子都是 mongo这个命令行工具的,而不是api的
不过也可以先去试试mongo命令远程连接试试
再去试试 API去连接
MongoDB命令连接远程服务器的MongoDB数据库 – 奔赴de博客
然后接着要去搞清楚:
【已解决】阿里云ECS服务器中已有的MongoDB的用户名密码和端口
然后接着去试试Python的代码,用pymongo中的api操作,远程连接mongodb:
参考:
Tutorial — PyMongo 3.6.1 documentation
mongo_client – Tools for connecting to MongoDB — PyMongo 3.6.1 documentation
之前连接本地的是:
<code>mongoClient = MongoClient() </code>
【已解决】远程的mongoDB中GridFS报错:AttributeError GridFS object has no attribute totalSize
然后继续去试试,用PyCharm的Mongodb插件去打开远程服务器中mongo数据库试试:
【已解决】用PyCharm的MongoDB插件连接远程MongoDB数据库
【总结】
如此,即可正常的通过代码:
<code># -*- coding: utf-8 -*-
import pymongo
from pymongo import MongoClient
import gridfs
# from pymongo.objectid import ObjectId
# from pymongo import objectid
from bson.objectid import ObjectId
from gridfs import GridFS
# import pprint
import os
import logging
import sys
sys.path.append("libs/crifan")
import crifanLib
import re
import mime
from openpyxl import Workbook, load_workbook
################################################################################
# Global Config/Setting
################################################################################
StorybookSheetTitle = u"绘本"
EnglishStorybookRootPath = u"xxx/数据/FromMaggie"
ExcelFilename = u"英语绘本资源2018.3.28_forDebug.xlsx"
ExcelFullFilename = os.path.join(EnglishStorybookRootPath, ExcelFilename)
AudioFilePathPrefix = EnglishStorybookRootPath
# the real content start row number
realContentRowStartNum = 3
# each column number
StorybookSerieNumColNum = 1
KeywordStorybookSerieColNum = 2
KeywordStorybookNameColNum = 3
KeywordStorybookNameKeywordColNum = 4
KeywordMainActorColNum = 5
KeywordTopicColNum = 6
KeywordContentKeywordColNum = 7
FitAgeRangeColNum = 8
IsFictionColNum = 9
HasStorybookFileColNum = 10
StorybookFilePathColNum = 11
HasAudioFileColNum = 12
AudioFilePathColNum = 13
AuthorColNum = 14
ContentSimpleIntroColNum = 15
PublisherColNum = 16
ForeignCountryColNum = 17
AwardsColNum = 18
LexileIndexColNum = 19
################################################################################
# Global Value
################################################################################
gSummaryDict = {
"totalCostTime": 0,
"savedFile": {
"totalCount": 0,
"idNameList": []
}
}
################################################################################
# Local Function
################################################################################
def initLogging():
"""
init logging
:return: log file name
"""
global gCfg
# init logging
filenameNoSufx = crifanLib.getInputFileBasenameNoSuffix()
logFilename = filenameNoSufx + ".log"
crifanLib.loggingInit(logFilename)
return logFilename
def strToList(inputStr, seperatorChar=","):
"""
convert string to list by using seperator char
example:
u'Family members,Sick'
->
[u'Family members', u'Sick']
:param seperatorChar: the seperator char
:return: converted list
"""
convertedList = None
if inputStr:
convertedList = inputStr.split(seperatorChar) #<type 'list'>: [u'Family members', u'Sick']
return convertedList
def testGridfsDeleteFile(fsCollection):
# test file delete
# fileIdToDelete = "5abc96dfa4bc715f473f0297"
# fileIdToDelete = "5abc9525a4bc715e187c6d6d"
# fileIdToDelete = "ObjectId('5abc96dfa4bc715f473f0297')"
# fileIdToDelete = 'ObjectId("5abc8d77a4bc71563222d455")'
# fileIdToDelete = '5abc8d77a4bc71563222d455'
# logging.info("fileIdToDelete=%s", fileIdToDelete)
# foundFile = fsCollection.find_one({"_id": fileIdToDelete})
# foundFile = fsCollection.find_one()
# logging.info("foundFile=%s", foundFile)
# fileIdToDelete = foundFile._id
# logging.info("fileIdToDelete=%s", fileIdToDelete)
curNum = 0
for curIdx, eachFile in enumerate(fsCollection.find()):
curNum = curIdx + 1
# fileIdToDelete = eachFile._id
# fileObjectIdToDelete = ObjectId(fileIdToDelete)
fileObjectIdToDelete = eachFile._id
logging.info("fileObjectIdToDelete=%s", fileObjectIdToDelete)
# if fsCollection.exists(fileObjectIdToDelete):
fsCollection.delete(fileObjectIdToDelete)
logging.info("delete [%d] ok for file object id=%s", curNum, fileObjectIdToDelete)
# else:
# logging.warning("Can not find file to delete for id=%s", fileIdToDelete)
logging.info("Total deleted [%d] files", curNum)
################################################################################
# Main Part
################################################################################
initLogging()
# parse excel file
wb = load_workbook(ExcelFullFilename)
logging.info("wb=%s", wb)
# sheetNameList = wb.get_sheet_names()
# logging.info("sheetNameList=%s", sheetNameList)
ws = wb[StorybookSheetTitle]
logging.info("ws=%s", ws)
# init mongodb
# connect to local mongo
# mongoClient = MongoClient()
# connect to remote mongo
mongoClient = MongoClient(
host="x.x.x.x",
port=27017,
username="username",
password="P@wd"
)
logging.info("mongoClient=%s", mongoClient)
gridfsDb = mongoClient.gridfs
logging.info("gridfsDb=%s", gridfsDb)
# collectionNames = gridfsDb.collection_names(include_system_collections=False)
# logging.info("collectionNames=%s", collectionNames)
# fsCollection = gridfsDb.fs
# fsCollection = gridfsDb["fs"]
fsCollection = GridFS(gridfsDb)
logging.info("fsCollection=%s", fsCollection)
# logging.info("fsCollection.stats()=%s", fsCollection.stats())
# logging.info("fsCollection.totalSize()=%s", fsCollection.totalSize())
testGridfsDeleteFile(fsCollection)
crifanLib.calcTimeStart("saveAllAudioFile")
# process each row in excel
for curRowNum in range(realContentRowStartNum, ws.max_row + 1):
logging.info("-"*30 + " row[%d] " + "-"*30, curRowNum)
hasAudioFileColNumCellValue = ws.cell(row=curRowNum, column=HasAudioFileColNum).value
logging.info("col[%d] hasAudioFileColNumCellValue=%s", HasAudioFileColNum, hasAudioFileColNumCellValue)
audioFilePathColNumCellValue = ws.cell(row=curRowNum, column=AudioFilePathColNum).value
logging.info("col[%d] audioFilePathColNumCellValue=%s", AudioFilePathColNum, audioFilePathColNumCellValue)
if not ((hasAudioFileColNumCellValue == u"有") and audioFilePathColNumCellValue and (audioFilePathColNumCellValue != u"")):
logging.warning("not found valid audio file for row=%d", curRowNum)
continue
logging.info("will save audio file %s", audioFilePathColNumCellValue)
# extract all column value
storybookSerieNumCellValue = ws.cell(row=curRowNum, column=StorybookSerieNumColNum).value
logging.info("col[%d] storybookSerieNumCellValue=%s", StorybookSerieNumColNum, storybookSerieNumCellValue)
keywordStorybookSerieCellValue = ws.cell(row=curRowNum, column=KeywordStorybookSerieColNum).value
logging.info("col[%d] keywordStorybookSerieCellValue=%s", KeywordStorybookSerieColNum, keywordStorybookSerieCellValue)
keywordStorybookNameColNumCellValue = ws.cell(row=curRowNum, column=KeywordStorybookNameColNum).value
logging.info("col[%d] keywordStorybookNameColNumCellValue=%s", KeywordStorybookNameColNum, keywordStorybookNameColNumCellValue)
keywordStorybookNameKeywordCellValue = ws.cell(row=curRowNum, column=KeywordStorybookNameKeywordColNum).value
logging.info("col[%d] keywordStorybookNameKeywordCellValue=%s", KeywordStorybookNameKeywordColNum, keywordStorybookNameKeywordCellValue)
keywordMainActorColNumCellValue = ws.cell(row=curRowNum, column=KeywordMainActorColNum).value
logging.info("col[%d] keywordMainActorColNumCellValue=%s", KeywordMainActorColNum, keywordMainActorColNumCellValue)
keywordTopicColNumCellValue = ws.cell(row=curRowNum, column=KeywordTopicColNum).value
logging.info("col[%d] keywordTopicColNumCellValue=%s", KeywordTopicColNum, keywordTopicColNumCellValue)
keywordContentKeywordColNumCellValue = ws.cell(row=curRowNum, column=KeywordContentKeywordColNum).value
logging.info("col[%d] keywordContentKeywordColNumCellValue=%s", KeywordContentKeywordColNum, keywordContentKeywordColNumCellValue)
fitAgeRangeColNumCellValue = ws.cell(row=curRowNum, column=FitAgeRangeColNum).value
logging.info("col[%d] fitAgeRangeColNumCellValue=%s", FitAgeRangeColNum, fitAgeRangeColNumCellValue)
isFictionColNumCellValue = ws.cell(row=curRowNum, column=IsFictionColNum).value
logging.info("col[%d] isFictionColNumCellValue=%s", IsFictionColNum, isFictionColNumCellValue)
hasStorybookFileColNumCellValue = ws.cell(row=curRowNum, column=HasStorybookFileColNum).value
logging.info("col[%d] hasStorybookFileColNumCellValue=%s", HasStorybookFileColNum, hasStorybookFileColNumCellValue)
storybookFilePathColNumCellValue = ws.cell(row=curRowNum, column=StorybookFilePathColNum).value
logging.info("col[%d] storybookFilePathColNumCellValue=%s", StorybookFilePathColNum, storybookFilePathColNumCellValue)
authorColNumCellValue = ws.cell(row=curRowNum, column=AuthorColNum).value
logging.info("col[%d] authorColNumCellValue=%s", AuthorColNum, authorColNumCellValue)
contentSimpleIntroColNumCellValue = ws.cell(row=curRowNum, column=ContentSimpleIntroColNum).value
logging.info("col[%d] contentSimpleIntroColNumCellValue=%s", ContentSimpleIntroColNum, contentSimpleIntroColNumCellValue)
publisherColNumCellValue = ws.cell(row=curRowNum, column=PublisherColNum).value
logging.info("col[%d] publisherColNumCellValue=%s", PublisherColNum, publisherColNumCellValue)
foreignCountryColNumCellValue = ws.cell(row=curRowNum, column=ForeignCountryColNum).value
logging.info("col[%d] foreignCountryColNumCellValue=%s", ForeignCountryColNum, foreignCountryColNumCellValue)
awardsColNumCellValue = ws.cell(row=curRowNum, column=AwardsColNum).value
logging.info("col[%d] awardsColNumCellValue=%s", AwardsColNum, awardsColNumCellValue)
lexileIndexColNumCellValue = ws.cell(row=curRowNum, column=LexileIndexColNum).value
logging.info("col[%d] lexileIndexColNumCellValue=%s", LexileIndexColNum, lexileIndexColNumCellValue)
# test read existed file info
# someFile = fsCollection.files.find_one()
# someFile = fsCollection.find_one()
# logging.info("someFile=%s", someFile)
# # ottoTheCatFile = fsCollection.files.find_one({"filename": "Otto the Cat-withMIME.MP3"})
# ottoTheCatFile = fsCollection.find_one({"filename": "Otto the Cat-withMIME.MP3"})
# logging.info("ottoTheCatFile=%s", ottoTheCatFile)
# put/save local file to mongodb
# curAudioFilename = "英语资源\All Aboard Reading\音频\Lots of Hearts.mp3"
# curAudioFilenameFiltered = re.sub(r"\\", "/", curAudioFilename) #'英语资源/All Aboard Reading/音频/Lots of Hearts.mp3'
curAudioFilenameFiltered = re.sub(r"\\", "/", audioFilePathColNumCellValue) # u'英语资源/Madeline/音频/Madeline.mp3'
# curAudioFullFilename = "xxx/FromMaggie/" + curAudioFilename
curAudioFullFilename = os.path.join(AudioFilePathPrefix, curAudioFilenameFiltered) #u'xxx/数据/FromMaggie/英语资源/Madeline/音频/Madeline.mp3'
if not os.path.isfile(curAudioFullFilename):
logging.error("Can not find file: %s", curAudioFullFilename)
continue
curFilename = crifanLib.getBasename(curAudioFullFilename) #u'Madeline.mp3'
logging.info("curFilename=%s", curFilename)
# extarct MIME
# fileMimeType = mime.MIMETypes.load_from_file(curFilename)
# fileMimeType = mime.MimeType.fromName(curFilename)
fileMimeType = mime.Types.of(curFilename)[0].content_type
logging.info("fileMimeType=%s", fileMimeType) #'audio/mpeg'
metadataDict = {
"type": "storybook",
"storybookSeriesNumber": storybookSerieNumCellValue,
"keywordStorybookSeries": keywordStorybookSerieCellValue,
"keywordStorybookName": keywordStorybookNameColNumCellValue,
"keywordStorybookNameKeywordList": strToList(keywordStorybookNameKeywordCellValue),
"keywordMainActorList": strToList(keywordMainActorColNumCellValue),
"keywordTopicList": strToList(keywordTopicColNumCellValue),
"keywordContentKeywordList": strToList(keywordContentKeywordColNumCellValue),
"fitAgeRange": fitAgeRangeColNumCellValue,
"isFiction": isFictionColNumCellValue,
"hasStorybookFile": hasStorybookFileColNumCellValue,
"storybookFilePath": storybookFilePathColNumCellValue,
"hasAudioFile": hasAudioFileColNumCellValue,
"audioFilePath": audioFilePathColNumCellValue,
"authorList": strToList(authorColNumCellValue),
"contentSimpleIntro": contentSimpleIntroColNumCellValue,
"publisher": publisherColNumCellValue,
"foreignCountry": foreignCountryColNumCellValue,
"awards": awardsColNumCellValue,
"lexileIndex": lexileIndexColNumCellValue
}
logging.info("metadataDict=%s", metadataDict)
with open(curAudioFullFilename) as audioFp:
audioFileObjectId = fsCollection.put(
audioFp,
filename=curFilename,
content_type=fileMimeType,
metadata=metadataDict)
logging.info("audioFileObjectId=%s", audioFileObjectId)
# readOutAudioFile = fsCollection.get(audioFileObjectId)
# logging.info("readOutAudioFile=%s", readOutAudioFile)
# audioFileMedata = readOutAudioFile.metadata
# logging.info("audioFileMedata=%s", audioFileMedata)
audioFileIdStr = str(audioFileObjectId)
gSummaryDict["savedFile"]["totalCount"] += 1
idNameDict = {
"fileId": audioFileIdStr,
"fileName": curFilename
}
gSummaryDict["savedFile"]["idNameList"].append(idNameDict)
gSummaryDict["totalCostTime"] = crifanLib.calcTimeEnd("saveAllAudioFile")
logging.info("="*30 + " Summary Info " + "="*30)
logging.info("gSummaryDict=%s", gSummaryDict)
logging.info("%s", crifanLib.jsonToPrettyStr(gSummaryDict))
</code>把本地的音频文件:
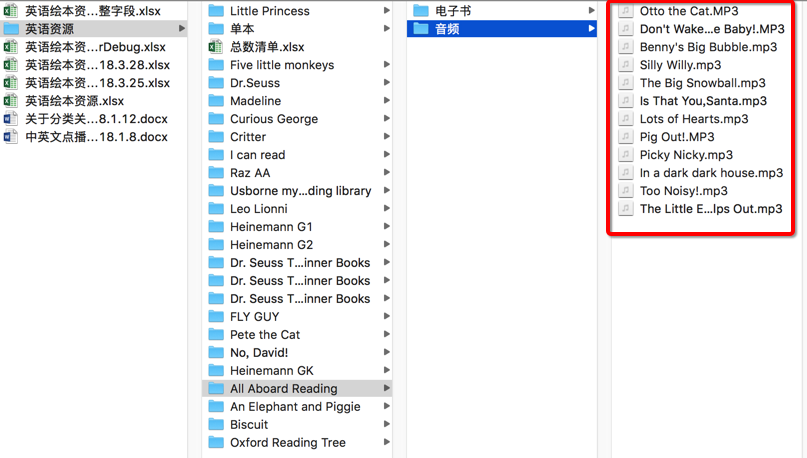
上传到在线的MongoDB中了: