之前已经实现了:
【已解决】Mac中用Selenium自动操作浏览器实现百度搜索
现在继续换用:puppeteer去实现同样效果。
先去看如何搭建环境:
【已解决】Mac中初始化搭建Python版puppeteer的pyppeteer的开发环境
然后再去看,如何定位元素:
【已解决】pyppeteer中如何定位查找百度搜索输入框
搞懂基本操作逻辑后,后续即可方便的实现后续逻辑了。
接下来是,触发搜索
方式1:点击 百度一下 按钮
方式2:输入回车键
分别去试试
【已解决】pyppeteer中如何模拟输入回车键
以及试试:定位 百度一下 按钮,并点击
先去看看元素
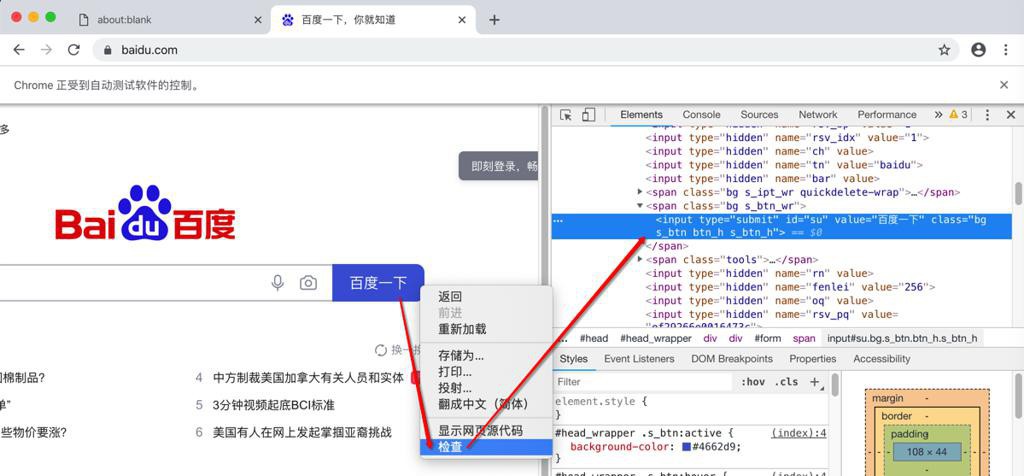
1 | <input type="submit" id="su" value="百度一下" class="bg s_btn"> |
去试试:
1 2 3 4 | SearchButtonSelector = "input[id='su']" searchButtonElem = await page.querySelector(SearchButtonSelector) print("searchButtonElem=%s" % searchButtonElem) searchButtonElem.click() |
但是没效果
看到警告:
1 2 | /Users/crifan/dev/dev_root/python/puppeteerBaiduSearch/puppeteerBaiduSearch.py:50: RuntimeWarning: coroutine 'ElementHandle.click' was never awaited searchButtonElem.click() |
所以要去加上await
1 | await searchButtonElem.click() |
结果:
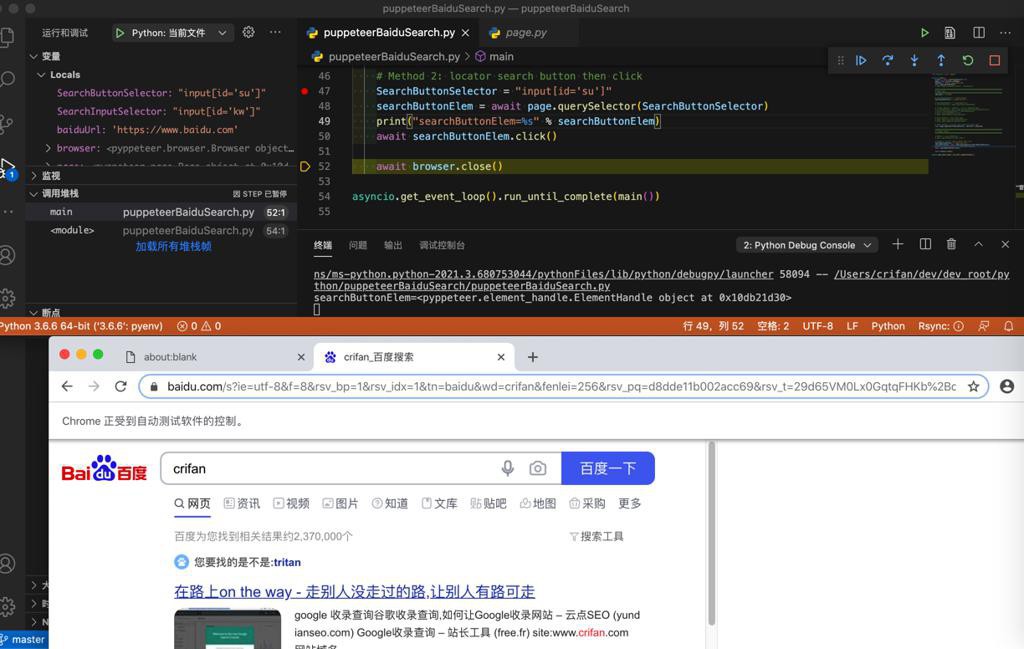
就可以了。
目前代码是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | ################################################################################ # Trigger search ################################################################################ # Method 1: press ENTER key # await page.keyboard.press('Enter') # Method 2: locator search button then click SearchButtonSelector = "input[id='su']" searchButtonElem = await page.querySelector(SearchButtonSelector) print("searchButtonElem=%s" % searchButtonElem) await searchButtonElem.click() |
即可。
另外看到
1 | await (await page.$('input[type="text"]')).press('Enter'); // Enter Key |
去试试
1 | await searchButtonElem.press("Enter") |
结果:
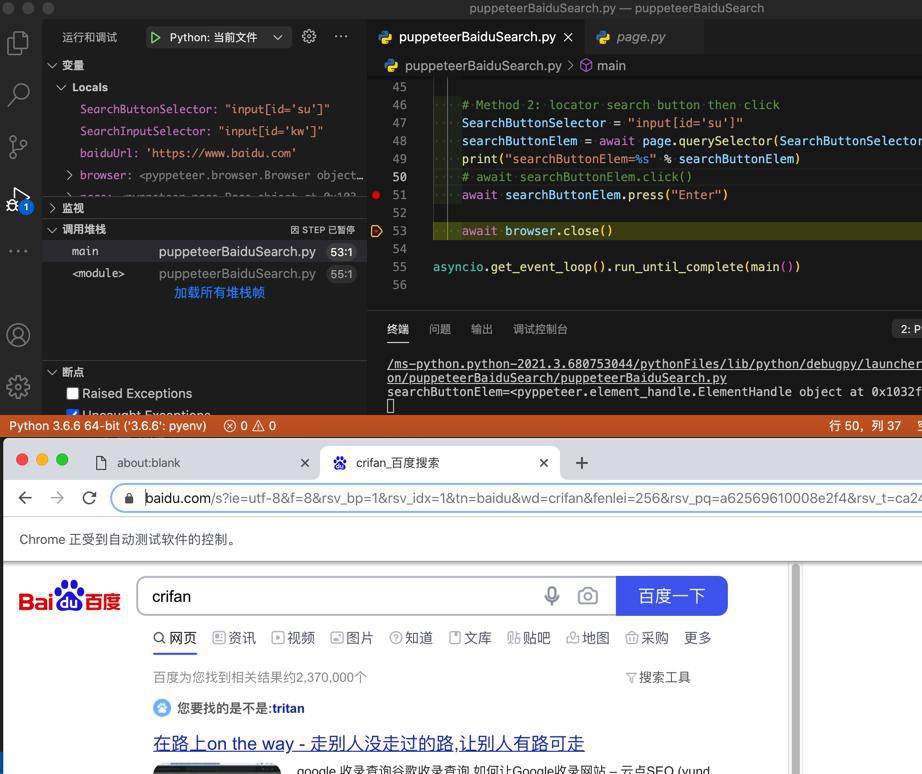
也是可以的。
即,点击某个按钮,可以用:
用该元素的click
1 | await searchButtonElem.click() |
也可以用:
用该元素去触发回车键:
1 | await searchButtonElem.press("Enter") |
至此,已经可以触发搜索了。
接着再去看看,如何提取搜索结果标题和链接:
【已解决】pyppeteer中提取百度搜索结果中的信息
最终代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 | # Function: pyppeteer (python version puppeteer) do baidu search# Author: Crifan Li# Update: 20210330import asynciofrom pyppeteer import launchasync def main(): browser = await launch(headless=False) page = await browser.newPage() await page.setJavaScriptEnabled(enabled=True) await page.goto(baiduUrl) # await page.screenshot({'path': 'baidu.png'}) ################################################################################ # Input text ################################################################################ searchStr = "crifan" # SearchInputSelector = "input[id=kw]" SearchInputSelector = "input[id='kw']" # SearchInputXpath = "//input[@id='kw']" # searchInputElem = page.xpath(SearchInputXpath) # # Input method 1: selector + click + keyboard type # searchInputElem = await page.querySelector(SearchInputSelector) # print("searchInputElem=%s" % searchInputElem) # await searchInputElem.click() # await page.keyboard.type(searchStr) # Input method 2: focus then type # await page.focus(SearchInputSelector) # await page.keyboard.type(searchStr) # Input method 3: selector and input once using type await page.type(SearchInputSelector, searchStr, delay=20) ################################################################################ # Trigger search ################################################################################ # Method 1: press ENTER key await page.keyboard.press('Enter') # # Method 2: locator search button then click # SearchButtonSelector = "input[id='su']" # searchButtonElem = await page.querySelector(SearchButtonSelector) # print("searchButtonElem=%s" % searchButtonElem) # await searchButtonElem.click() # # await searchButtonElem.press("Enter") ################################################################################ # Wait page reload complete ################################################################################ SearchFoundWordsSelector = 'span.nums_text' SearchFoundWordsXpath = "//span[@class='nums_text']" # await page.waitForSelector(SearchFoundWordsSelector) # await page.waitFor(SearchFoundWordsSelector) # await page.waitForXPath(SearchFoundWordsXpath) # Note: all above exception: 发生异常: ElementHandleError Evaluation failed: TypeError: MutationObserver is not a constructor # so change to following # # Method 1: just wait # await page.waitFor(2000) # millisecond # Method 2: wait element showing SingleWaitSeconds = 1 while not await page.querySelector(SearchFoundWordsSelector): print("Still not found %s, wait %s seconds" % (SearchFoundWordsSelector, SingleWaitSeconds)) await asyncio.sleep(SingleWaitSeconds) # pass ################################################################################ # Extract result ################################################################################ resultASelector = "h3[class^='t'] a" searchResultAList = await page.querySelectorAll(resultASelector) # print("searchResultAList=%s" % searchResultAList) searchResultANum = len(searchResultAList) print("Found %s search result:" % searchResultANum) for curIdx, aElem in enumerate(searchResultAList): curNum = curIdx + 1 print("%s [%d] %s" % ("-"*20, curNum, "-"*20)) aTextJSHandle = await aElem.getProperty('textContent') # print("type(aTextJSHandle)=%s" % type(aTextJSHandle)) # type(aTextJSHandle)=<class 'pyppeteer.execution_context.JSHandle'> # print("aTextJSHandle=%s" % aTextJSHandle) # aTextJSHandle=<pyppeteer.execution_context.JSHandle object at 0x10309c9b0> title = await aTextJSHandle.jsonValue() # print("type(title)=%s" % type(title)) # type(title)=<class 'str'> print("title=%s" % title) baiduLinkUrl = await (await aElem.getProperty("href")).jsonValue() print("baiduLinkUrl=%s" % baiduLinkUrl) await browser.close()asyncio.get_event_loop().run_until_complete(main()) |
输出:
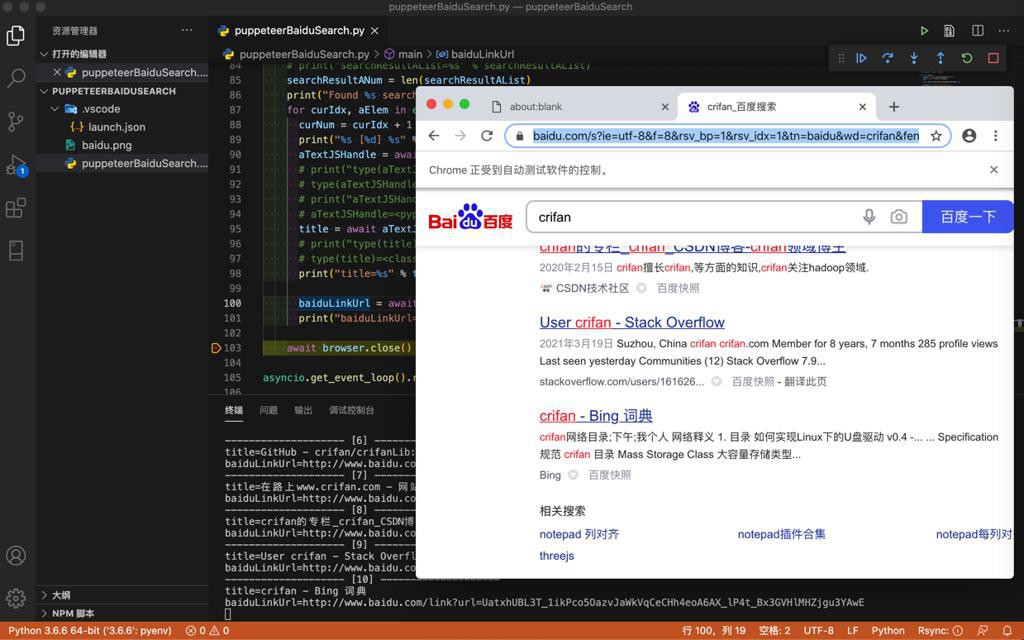
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 | Still not found span.nums_text, wait 1 secondsFound 10 search result:-------------------- [1] --------------------title=在路上on the way - 走别人没走过的路,让别人有路可走baiduLinkUrl=http://www.baidu.com/link?url=eGTzEXXlMw-hnvXYSFk8t4VSZPck1dougn7YhfCwBf3ZzGJEHdZYsoAQK-4GBJuP-------------------- [2] --------------------title=crifan – 在路上baiduLinkUrl=http://www.baidu.com/link?url=l6jXejlgARrWj34ODgKWZ9BeNKwyYZLRhLb5B8oDFVqNpHoco8a_qbAdD1m-t_cf-------------------- [3] --------------------title=crifan简介_crifan的专栏-CSDN博客_crifanbaiduLinkUrl=http://www.baidu.com/link?url=IIqPM5wuVE_QP7S357-1bJWGGU1kpFcAZ945BaXUQNpaDzXihf_98wAVi05Gk6-8Qu4aGLv2Rv65WJm6Qr5kk_-------------------- [4] --------------------title=crifan的微博_微博baiduLinkUrl=http://www.baidu.com/link?url=NnqeMlu4Jr_Ld-zoui8pbQO4eRMMO9pLd_DHXagqcdZ46NF4CSuyEziKSTpqCNEi-------------------- [5] --------------------title=Crifan的电子书大全 | crifan.github.iobaiduLinkUrl=http://www.baidu.com/link?url=uOZ-AmgNBNr3mGdETezIjTvtedH_ueM6-LNOc2QxbjcNeS8LuVBY-kirwogX7qLl-------------------- [6] --------------------title=GitHub - crifan/crifanLib: crifan's librarybaiduLinkUrl=http://www.baidu.com/link?url=t42I1rYfn32DGw9C6cw_5lB-z1worKzEuROOtWj-Jyf1l2IBNBcz-l85hSKv9s9T-------------------- [7] --------------------title=在路上www.crifan.com - 网站排行榜baiduLinkUrl=http://www.baidu.com/link?url=WwLwfXA72vK08Obyx2hwqA3-wmq8jAisi4VVSt2R0Ml3ccCy_yxeYfxD2xouAX-i5AyUU1U_2EghwVbJ2p-ipa-------------------- [8] --------------------title=crifan的专栏_crifan_CSDN博客-crifan领域博主baiduLinkUrl=http://www.baidu.com/link?url=Cmcn2mXwiZr87FBGQBq85Np0hgGTP_AK2yLUW6GDeA21r7Q5WvUOUjaKZo5Jhb0f-------------------- [9] --------------------title=User crifan - Stack OverflowbaiduLinkUrl=http://www.baidu.com/link?url=yGgsq1z2vNDAAeWY-5VDWbHv7e7zPILHI4GVFPZd6MaFrGjYHsb3Onir1Vi6vvZqD7QAGJrZehIYZpcBfh_Gq_-------------------- [10] --------------------title=crifan - Bing 词典baiduLinkUrl=http://www.baidu.com/link?url=UatxhUBL3T_1ikPco5OazvJaWkVqCeCHh4eoA6AX_lP4t_Bx3GVHlMHZjgu3YAwE |
效果:
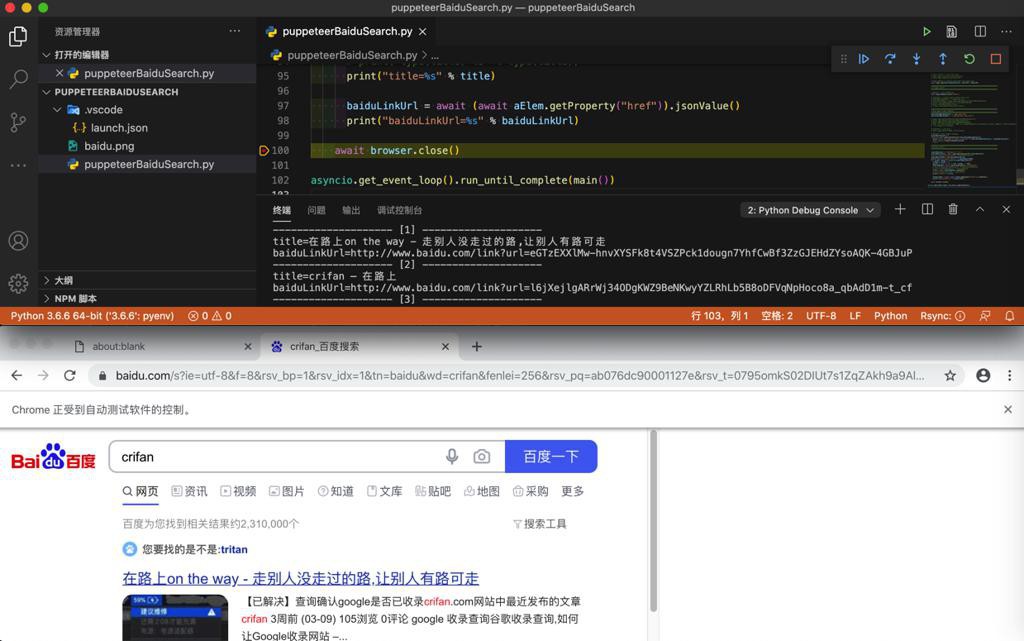
附录:
官网资料:
- 谷歌的JS的Puppeteer
- Quick start | Tools for Web Developers | Google Developers
- Python的pyppeteer
- 旧的:miyakogi
- miyakogi/pyppeteer: Headless chrome/chromium automation library (unofficial port of puppeteer)
- Pyppeteer’s documentation — Pyppeteer 0.0.25 documentation
- API Reference — Pyppeteer 0.0.25 documentation
- 新的:pyppeteer
- pyppeteer/pyppeteer: Headless chrome/chromium automation library (unofficial port of puppeteer)
- Pyppeteer’s documentation — Pyppeteer 0.0.25 documentation
其他:
如何写Selector可参考:
转载请注明:在路上 » 【已解决】Mac中用puppeteer自动操作浏览器实现百度搜索