mongodb 分库
mongodb 分库分表
“mongo有集群的功能,自动帮你分库分表。对你来说分库分表是透明的。”
“其实在该不该分表,分库上,mongo和传统的关系型数据库思维基本一致。
例如:
当你表的索引大到不能完全加载或快速地加载到内存的时候,你能不分表吗?
当你库内容大到一台DB撑不下的时候,你能不分库吗?
所以我认为,分表主要还是看单表的性能可以支撑得起来吗? 不行就分表。
具体如何判断单表是否能支撑的起来?
你可以预测下1~2年内业务可能会达到的最高的量。然后根据你预计的量做下DB压测。”
Mongodb高级篇-Replication & Sharding – 简书
此处的复制集,貌似不是自己目前关心的 分库
mongodb架构mongodb分片集群与简易搭建方案—ttlsa教程系列之mongodb(六) – 运维生存时间
分片集群,也不是要关心的。
“mongodb支持自动分片,集群自动的切分数据,做负载均衡。避免上面的分片管理难度。
分片适用场景:
1. 服务器磁盘不够用
2. 单个mongod不能满足日益频繁写请求
3. 将大量数据存放于内存中提高性能”
“所谓 sharding 就是将数据水平切分到不同的物理节点。这里着重点有两个,
一个是水平切分,
另一个是物理节点。
而物理节点,主要是和如 mysql 等提供的表分区区分。表分区虽然也对数据进行了划分,但是这些分区仍然是在同一个物理节点上。”
一般我们说数据库的分库分表有两种类型。
一种是水平划分,比如按用户 id 取模,按余数划分用户的数据,如博客文章等;
sharding 指的是水平划分。
另一种是垂直划分,比如把用户信息放一个节点,把文章放另一个节点,甚至可以把文章标题基本信息放一个节点,正文放另一个节点。
sharding
n. 分片;分区
replica set=复制集
“2.1 分库要自己代码实现
需要自己代码中实现根据不同的context访问不同的数据库,即实现根据分库的key,路由到不同的物理库上。”
微服务MySQL分库分表数据到MongoDB同步方案 | torry’s blog
mongodb还有分表的必要吗? – SegmentFault
“mongodb自带了autosharding,那么还有必要分表吗,加入一张表过亿级别?
意思是不用分表,自动sharding?
对,sharding是比分表更强(大部分场景下)的水平扩展方式。”
【总结】
MongoDB这个来源英文单词“humongous”
humongous:巨大的、奇大无比的
从MongoDB单词本身可以看出它的目标是提供海量数据的存储以及管理能力
MongoDB具备较好的扩展性以及高可用性
在数据复制方面,支持两种方式:
Master-Slaver(主从)
Replica-Set(副本集)
MongoDB特点:
NoSQL,Free Schema
丰富的查询支持
较多类型的索引支持
Auto-Sharding
库级Sharding
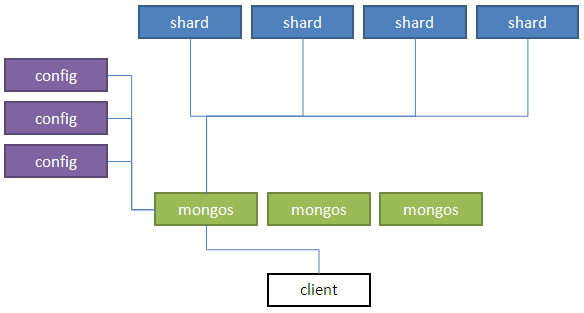
MongoDB集群部署:Sharding+Replica-Set的部署方式
Shard Server节点(存储节点,采用了Replica-Set的复制方式)
Config Server节点(配置节点)
Router Server(路由节点、Arbiter Server(投票节点)
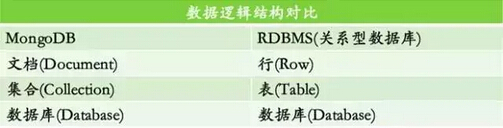
MongoDB三要素:
数据库(DataBase)
集合(Collection)
文档(Document)
分别对应RDBMS(比如MySQL)三要素:
数据库(DataBase)
表(Table)
行(Row)
MongoDB集群有多种方式可以监控:
mongosniff
mongostat
mongotop
db.xxoostatus
web控制台监控
MMS
第三方监控
转载请注明:在路上 » 【整理】mongodb分库