-》
深度学习:
- 需要:
- 大量的数据
- 大量的计算能力:GPU
- 目标:
- 从数据(图像、文本、信号等)中学习/提取信息
- 框架:
- 提供了灵活性
- 用来 设计 + 训练
- 自定义的 神经网络
- 提供接口
- 给常见编程语言
- 比如Python等
- 对于开发者:
- 提供了强大的工具和库
- 用于开发深度学习框架
- Caffe2
- Cognitive toolkit
- MXNet
- PyTorch
- TensorFlow
NVIDIA Deep Learning SDK包括:
(都是基于 CUDA的)
- cuDNN:
- Deep Learning Primitives
- High-performance building blocks for deep neural network applications including convolutions, activation functions, and tensor transformations
- TensorRT:
- Deep Learning Inference Engine
- High-performance deep learning inference runtime for production deployment
- DeepStream SDK
- Deep Learning for Video Analytics
- High-level C++ API and runtime for GPU-accelerated transcoding and deep learning inference
- cuBLAS
- Linear Algebra
- GPU-accelerated BLAS functionality that delivers 6x to 17x faster performance than CPU-only BLAS libraries
- cuSPARSE
- Sparse Matrix Operations
- GPU-accelerated linear algebra subroutines for sparse matrices that deliver up to 8x faster performance than CPU BLAS (MKL), ideal for applications such as natural language processing
- NCCL
- Multi-GPU Communication
- Collective communication routines, such as all-gather, reduce, and broadcast that accelerate multi-GPU deep learning training on up to eight GPUs
nvidia 深度学习
mac pro gpu

显卡:Intel Iris Graphics 6100 1536 MB
-》
k80 显卡
k80显卡 – 商品搜索 – 京东
https://search.jd.com/Search?keyword=k80显卡&enc=utf-8&spm=2.1.11
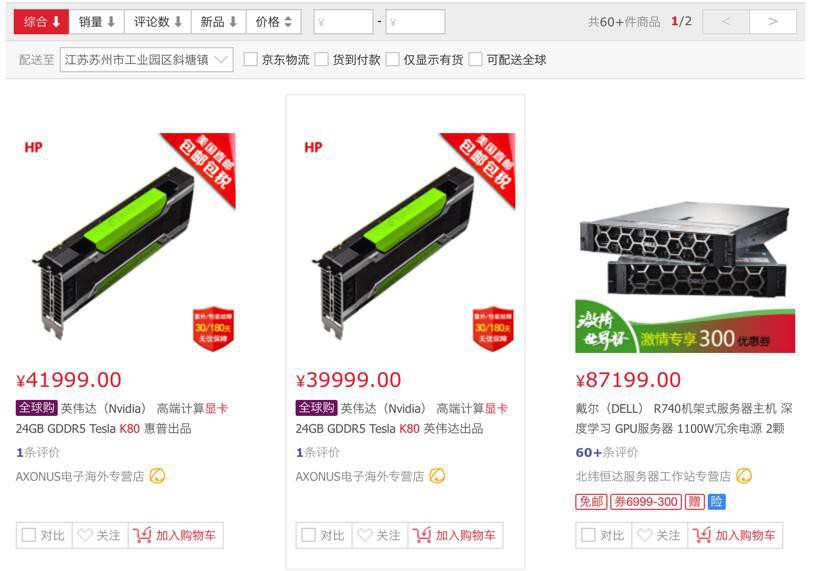
K80显卡价格:4万左右
【CUDA】
CUDA==Compute Unified Device Architecture==统一计算架构
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。
CUDA(Compute Unified Device Architecture,统一计算架构是由NVIDIA所推出的一种集成技术,是该公司对于GPGPU的正式名称。
通过这个技术,用户可利用NVIDIA的GeForce 8以后的GPU和较新的Quadro GPU进行计算。
- CPU=Central Processing Unit=中央处理器
- GPU=Graphics Processing Unit)=图形处理器
- GPGPU=General-purpose GPU=通用GPU=通用计算图形处理器
图形处理器通用计算 – 维基百科,自由的百科全书
https://zh.wikipedia.org/wiki/图形处理器通用计算
【cuDNN】
cuDNN
“The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks
cuDNN provides highly tuned implementations for standard routines such as forward and backward convolution, pooling, normalization, and activation layers. cuDNN is part of the NVIDIA Deep Learning SDK.”
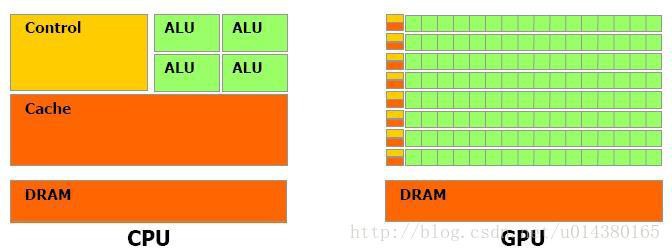
- GPU就像成千上万的苦力,每个人干的都是类似的苦力活,相互之间没有依赖,都是独立的,简单的人多力量大;
- CPU就像包工头,虽然也能干苦力的活,但是人少,所以一般负责任务分配,人员调度等工作。
CUDA=
a general purpose parallel computing platform and programming model that leverages the parallel compute engine in NVIDIA GPUs to solve many complex computational problems in a more efficient way than on a CPU.
换句话说CUDA是NVIDIA推出的用于自家GPU的并行计算框架,也就是说CUDA只能在NVIDIA的GPU上运行,而且只有当要解决的计算问题是可以大量并行计算的时候才能发挥CUDA的作用。
在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端:
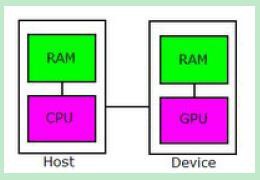
- Host 端是指在 CPU 上执行的部份
- 而 device 端则是在显示芯片上执行的部份。
- Device 端的程序又称为 “kernel”。
- -》通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
【总结】
cuDNN= CUDA Deep Neural Network
【TensorRT】
【讲座通知】如何构建高效的深度学习开发环境
-》
TensorRT
“NVIDIA TensorRT
Programmable Inference Accelerator”
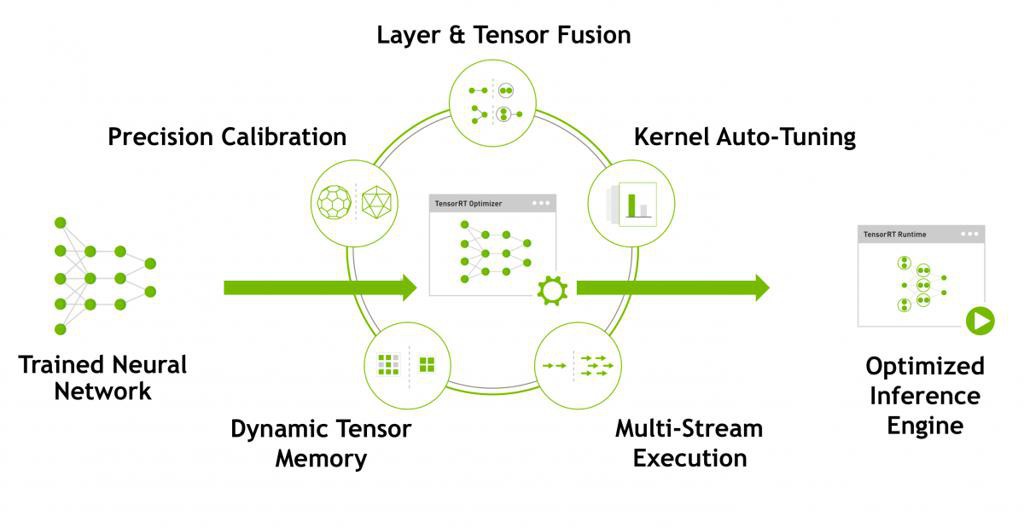
几种平台产品:
- embedded platforms:Jetson
- datacenter:Tesla GPUs
- autonomous driving platforms:NVIDIA DRIVE
生产环境的话,推荐:
- Tesla V100, P100, P4, and P40 GPUs
“NVIDIA TensorRT™ is a high-performance deep learning inference optimizer and runtime that delivers low latency, high-throughput inference for deep learning applications.”
转载请注明:在路上 » 【整理】NVIDIA Deep Learning SDK