【无法解决】PySpider的部署运行而非调试界面上RUN运行
crifan 7年前 (2018-07-13) 4883浏览 0评论
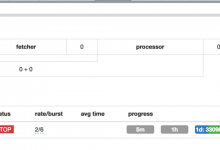
折腾: 【已解决】使用PySpider去爬取某网站中的视频 后,虽然可以打开: http://0.0.0.0:5000/ 在界面上把status改为DEBUG或RUN去运行,但是有些爬虫要爬完所有内容需要很长时间,比如此处:但是界面上调试运行,跑了好...
在路上on the way - 走别人没走过的路,让别人有路可走
crifan 7年前 (2018-07-13) 4883浏览 0评论
折腾: 【已解决】使用PySpider去爬取某网站中的视频 后,虽然可以打开: http://0.0.0.0:5000/ 在界面上把status改为DEBUG或RUN去运行,但是有些爬虫要爬完所有内容需要很长时间,比如此处:但是界面上调试运行,跑了好...
crifan 7年前 (2018-07-12) 852浏览 0评论
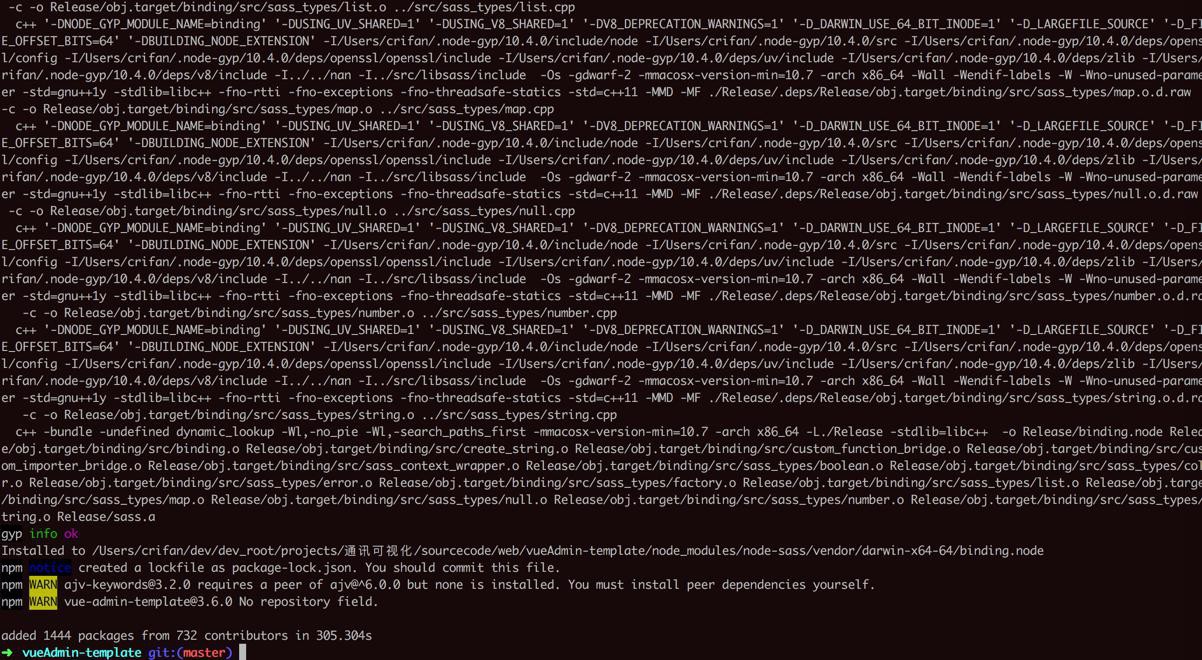
折腾: 【记录】本地用后台管理页面框架搭建图表原型 期间,去 -> /Users/crifan/dev/dev_root/projects/通讯可视化/sourcecode/web ➜ web git clone https://git...
crifan 7年前 (2018-07-12) 13016浏览 0评论
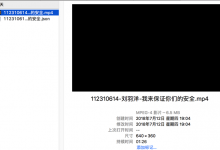
手上有个mp4的视频: 去看看能否提取出其中的字幕 但是如果是合并后的,字幕成为视频数据的一部分的,应该就无法提取了。 不过先去看看这个能否提取。 mac mp4 字幕提取 mac os中有什么办法可以将mkv视频中的字幕提取出来? –...
crifan 7年前 (2018-07-12) 4023浏览 0评论
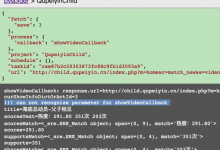
打算是用: xxx is str xxx is dict 去判断的: <code> def showVideoCallback(self, response): print("showVideoCallba...
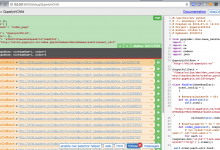
crifan 7年前 (2018-07-12) 4059浏览 0评论
PySpider中,通过一个函数,实现了根据当前页面号码,递归获取下一个页面: 相关部分代码是: <code> # @every(minutes=24 * 60) def on_start(self): s...
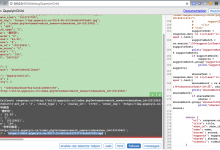
crifan 7年前 (2018-07-12) 3338浏览 0评论
折腾: 【已解决】使用PySpider去爬取某网站中的视频 期间,此处已经抓取到mp4视频地址了: showVideoCallback: response.url=http://xx.xx?m=home&c=match_...

crifan 7年前 (2018-07-12) 3877浏览 0评论
折腾: 【已解决】Mac中如何把图片中的文字识别转换出来 期间,去试试有道云笔记的OCR功能。 我花了一天,做了一款和「百度」比肩的 OCR 图片识字工具 iText – 掘金 有道云笔记上线OCR功能:轻松识别图片/PDF中文字(支持汉...

crifan 7年前 (2018-07-12) 6778浏览 0评论
Mac中,手上有些图片 希望识别出图片中的文字。 (注:另外后来还有PDF中的文字: 也希望识别出来) 之前知道有OCR软件的,现在去找找好用的 图片 OCR 识别文字 Mac Mac App Store 上的“iText – ...
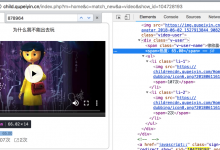
crifan 7年前 (2018-07-12) 3646浏览 0评论
折腾 【已解决】使用PySpider去爬取某网站中的视频 期间,需要去对于html: <code><div class="v-user"> <span class=&q...
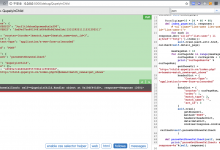
crifan 7年前 (2018-07-11) 4011浏览 0评论
折腾: 【已解决】使用PySpider去爬取某网站中的视频 期间,需要去搞清楚,PySpider中: 如何发送POST请求,且带格式为application/x-www-form-urlencoded的form data pyspider post ...