折腾:
【未解决】pyppeteer中提取百度搜索结果中的信息
期间,之前调试时可以获取到结果的代码:
1 2 | resultASelector = "h3[class^='t'] a" searchResultAList = await page.querySelectorAll(resultASelector) |
去直接运行,没加断点,结果就找不到结果了:
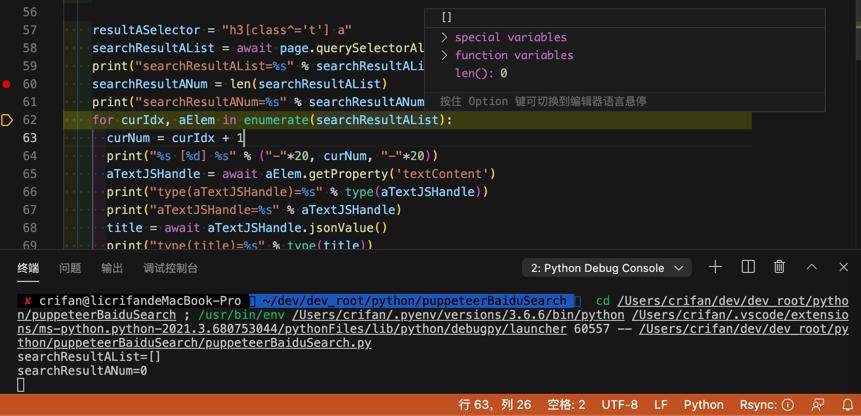
直接运行,会导致找不到数据
但是也加了await了啊
也没报警告啊
加了断点,等了点时间,就可以找到:
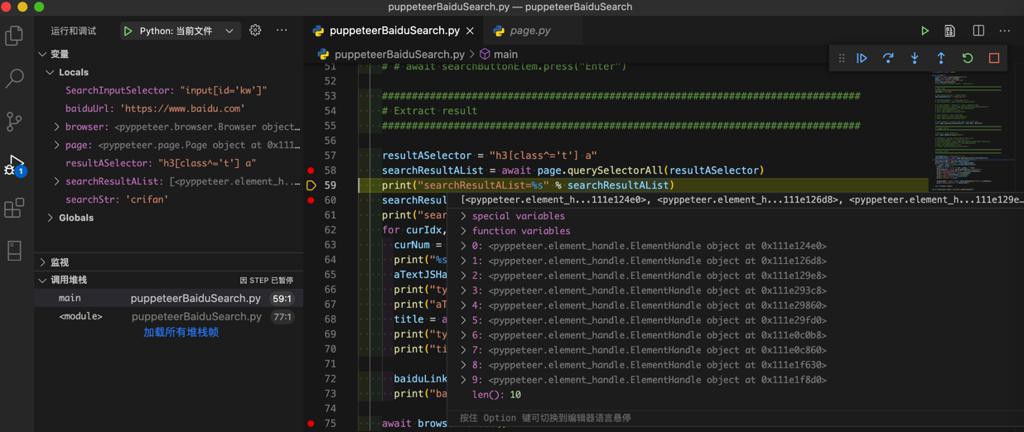
需要搞清楚原因
有个:page.waitForSelector
去看看
有:
“waitFor(selectorOrFunctionOrTimeout: Union[str, int, float], options: dict = None, *args, **kwargs) → Awaitable[T_co]”
和:
“waitForSelector(selector: str, options: dict = None, **kwargs) → Awaitable[T_co]”
但是没有希望的:
waitForSelectorAll
-》看来只能用:
waitForSelector 或 waitFor
去匹配之前的:
【整理】用Chrome或Chromium查看百度首页中各元素的html源码
的:
1 | <span class="nums_text">百度为您找到相关结果约2,370,000个</span> |
puppeteer querySelectorAll no result
puppeteer querySelector no result
1 | await page.waitForSelector('div.landscape h3.title'); // <-- add this line //updated from page.waitFor that is getting deprecated in 2020 |
去试试:
1 | await page.waitForSelector('span.nums_text') |
结果:
直接运行,是可以的
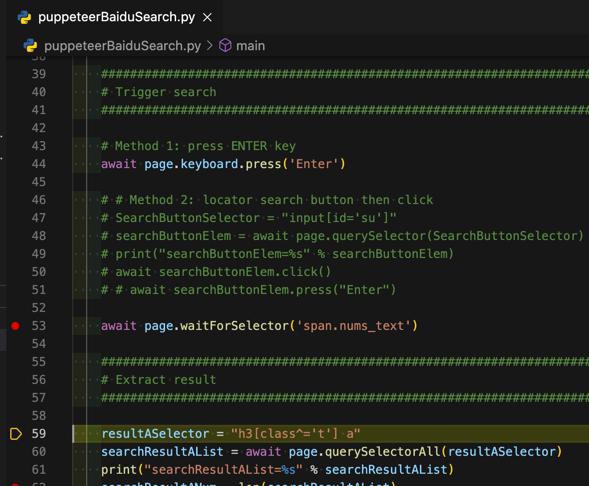
去看看源码:
/Users/crifan/.pyenv/versions/3.6.6/lib/python3.6/site-packages/pyppeteer/page.py
1 2 3 | def waitForSelector(self, selector: str, options: dict = None, **kwargs: Any) -> Awaitable: """Wait until element which matches ``selector`` appears on page. |
【规避解决】pyppeteer不调试直接运行waitForSelector报错:ElementHandleError Evaluation failed TypeError MutationObserver is not a constructor at pollMutation
此处用代码:
1 2 3 4 5 6 | # Method 2: wait element showing SingleWaitSeconds = 1 while not await page.querySelector(SearchFoundWordsSelector): print("Still not found %s, wait %s seconds" % (SearchFoundWordsSelector, SingleWaitSeconds)) await asyncio.sleep(SingleWaitSeconds) # pass |
算是实现了等待元素出现。
后续即可正常检测到想要的元素了。
【总结】
此处,之所以
1 | await page.querySelectorAll(resultASelector) |
获取结果为空
是由于页面还没加载出结果
所以要去等待页面内容,点击搜索按钮后,重启加载完毕
所以最后用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | ################################################################################ # Wait page reload complete ################################################################################ SearchFoundWordsSelector = 'span.nums_text' SearchFoundWordsXpath = "//span[@class='nums_text']" # await page.waitForSelector(SearchFoundWordsSelector) # await page.waitFor(SearchFoundWordsSelector) # await page.waitForXPath(SearchFoundWordsXpath) # Note: all above exception: 发生异常: ElementHandleError Evaluation failed: TypeError: MutationObserver is not a constructor # so change to following # # Method 1: just wait # await page.waitFor(2000) # millisecond # Method 2: wait element showing SingleWaitSeconds = 1 while not await page.querySelector(SearchFoundWordsSelector): print("Still not found %s, wait %s seconds" % (SearchFoundWordsSelector, SingleWaitSeconds)) await asyncio.sleep(SingleWaitSeconds) # pass |
即可实现,等待页面中:
1 | <span class="nums_text">百度为您找到相关结果约2,370,000个</span> |
的这种元素出现
此处意味着百度搜索结果加载完毕。
后续即可正常搜索到内容了。