折腾:
期间,对于同样的html内容:
<code><ul class="rank-list-ul" 0=""> <li id="s3170"> <h4><a href="//www.autohome.com.cn/3170/#levelsource=000000000_0&;pvareaid=101594">奥迪A3</a></h4><div>指导价:<a class="red" href="//www.autohome.com.cn/3170/price.html#pvareaid=101446">19.23-25.80万</a></div><div><a href="//car.autohome.com.cn/price/series-3170.html#pvareaid=103446">报价</a> <a id="atk_3170" href="//car.autohome.com.cn/pic/series/3170.html#pvareaid=103448">图库</a> <a data-value="3170" class="" href="//www.che168.com/110100/series3170/?pvareaid=100535">二手车</a> <a href="//club.autohome.com.cn/bbs/forum-c-3170-1.html#pvareaid=103447">论坛</a> <a href="//k.autohome.com.cn/3170/#pvareaid=103459">口碑</a></div> </li> ... </ul> </code>
如图:
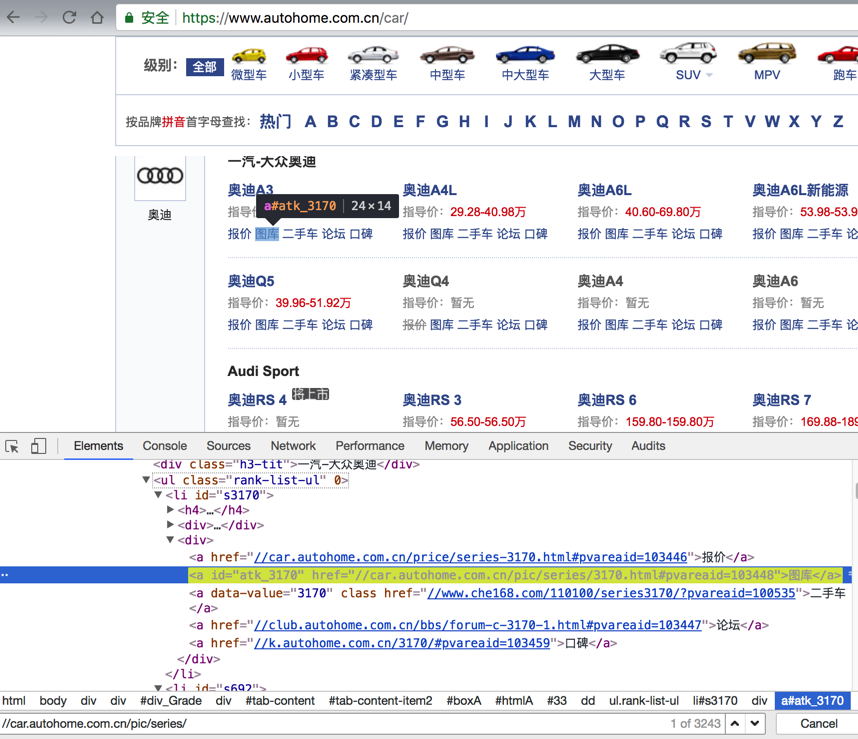
用css选择器:
<code>for each in response.doc('.rank-list-ul li div a[href^="//car.autohome.com.cn/pic/series/"]').items():
</code>结果不起效果。
但是换成:
<code>for each in response.doc('.rank-list-ul li div a[href*="/pic/series"]').items():
</code>就可以提取到元素了。
但是根据参考的:
CSS 选择器参考手册
http://www.w3school.com.cn/cssref/css_selectors.asp
a[src^=”https”] | 选择其 src 属性值以 “https” 开头的每个 <a> 元素。 | 3 | |
a[src$=”.pdf”] | 选择其 src 属性以 “.pdf” 结尾的所有 <a> 元素。 | 3 | |
a[src*=”abc”] | 选择其 src 属性中包含 “abc” 子串的每个 <a> 元素。 | 3 |
CSS selectors – CSS: Cascading Style Sheets | MDN
Attribute selector
Selects elements based on the value of the given attribute.
Syntax: [attr] [attr=value] [attr~=value] [attr|=value] [attr^=value][attr$=value] [attr*=value]
Example: [autoplay] will match all elements that have the autoplay attribute set (to any value).
应该是没有问题才对啊
难道是这里pyspider用到的pyquery
pyquery: a jquery-like library for python — pyquery 1.2.4 documentation
的bug或问题?
CSS — pyquery 1.2.4 documentation
pyquery css start with
pyquery – PyQuery complete API — pyquery 1.2.4 documentation
Attribute Starts With Selector [name^=”value”] | jQuery API Documentation
CSS [attribute^=value] Selector
jquery – Select an element when the class name starts with a certain word – Stack Overflow
Attribute Contains Selector [name*=”value”] | jQuery API Documentation
jQuery or CSS selector to select all IDs that start with some string – Stack Overflow
难道
[attr^=value]
中的value中间不能带斜杠?
为了确定开始的双斜杠不是Chrome的特殊显示,也去看了Safari,也是:
<code>href="//car.autohome.com.cn/pic/series/3170.html#pvareaid=103448" </code>
的:
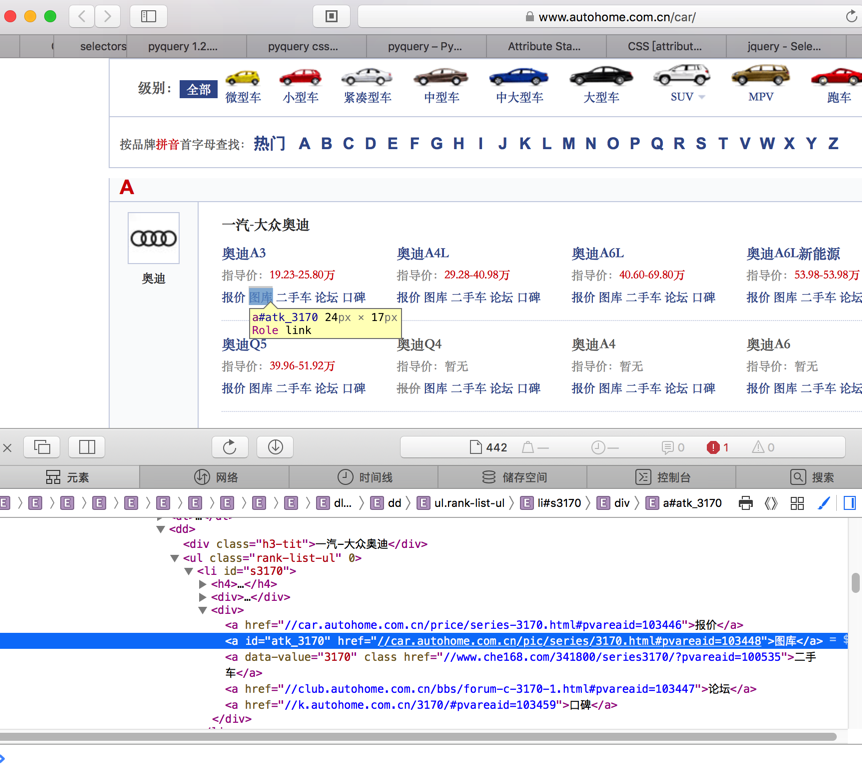
javascript – jquery selector for id starts with specific text – Stack Overflow
【总结】
暂时找不到原因,为何:
<code>a[href^="//car.autohome.com.cn/pic/series/"] </code>
不工作。
估计是pyspider或pyspieder中用到的pyquery的bug吧。
【后记 20180430】
后来才知道,原来是:
中说了
“ Links have made as absolute by default.”
所以,此处的html中看到的:
<code>href="//car.autohome.com.cn/pic/series/3170.html#pvareaid=103448" </code>
内部已经(被PySpider,估计是为了方便新手小白用户,而)变成了:
<code>href="https://car.autohome.com.cn/pic/series/3170.html#pvareaid=103448" </code>
所以才会出现,用:
<code>a[href^="//car.autohome.com.cn/pic/series/"] </code>
不起效果,而换成:
<code>a[href*="pic/series/"] </code>
才能找到。
详见:
转载请注明:在路上 » 【已解决】pyspider中的css选择器不工作