折腾:
期间,对于如下页面的数据:
此处是需要抓取:
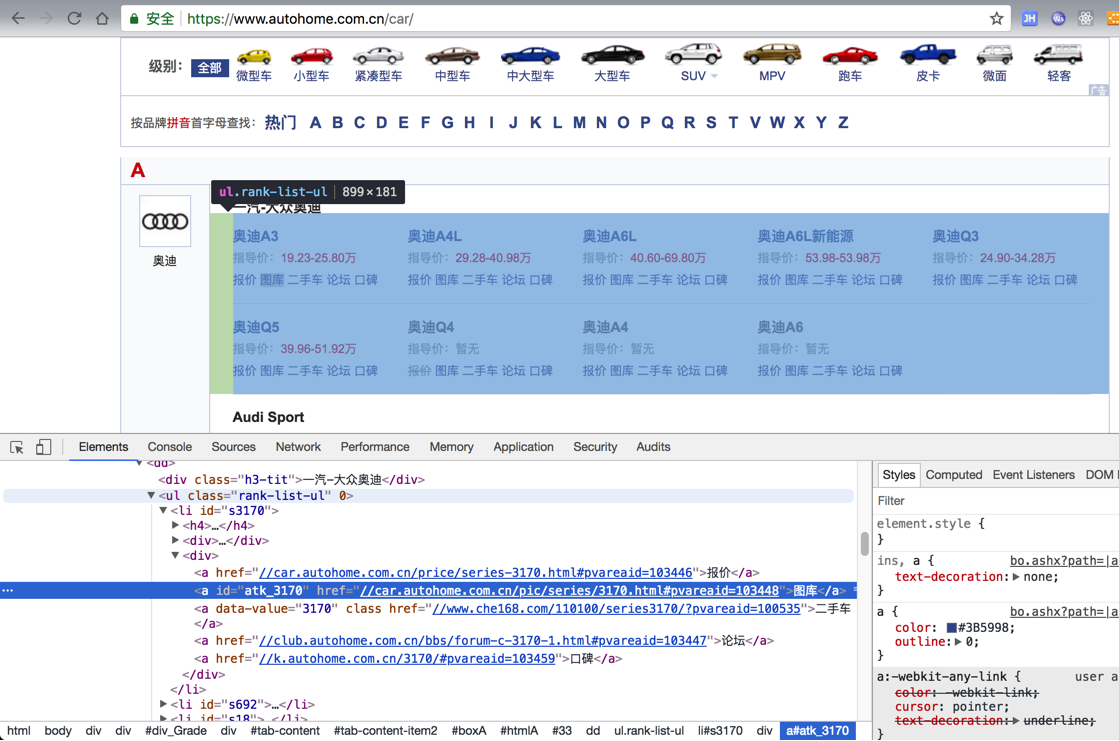
class=”rank-list-ul”
中的:
a中href类似于:
“//car.autohome.com.cn/pic/series/3170.html#pvareaid=103448“
“//car.autohome.com.cn/pic/series/692.html#pvareaid=103448”
“//car.autohome.com.cn/pic/series/2607.html#pvareaid=103448“
所以,先去写规则
pyquery: a jquery-like library for python — pyquery 1.2.4 documentation
css_selectors
css selector
CSS selectors – CSS: Cascading Style Sheets | MDN
此处的css选择器,好像是:
<code>.rank-list-ul li div a[href^="//car.autohome.com.cn/pic/series/"] </code>
然后再去试试对不对
修改了代码,去Save保存了代码,结果再去点击Run,结果找不到函数。
返回管理页面,重新进来,再去运行,没有提示出错,但是Run后没有返回任何follow
然后自己去看html,是有的啊:
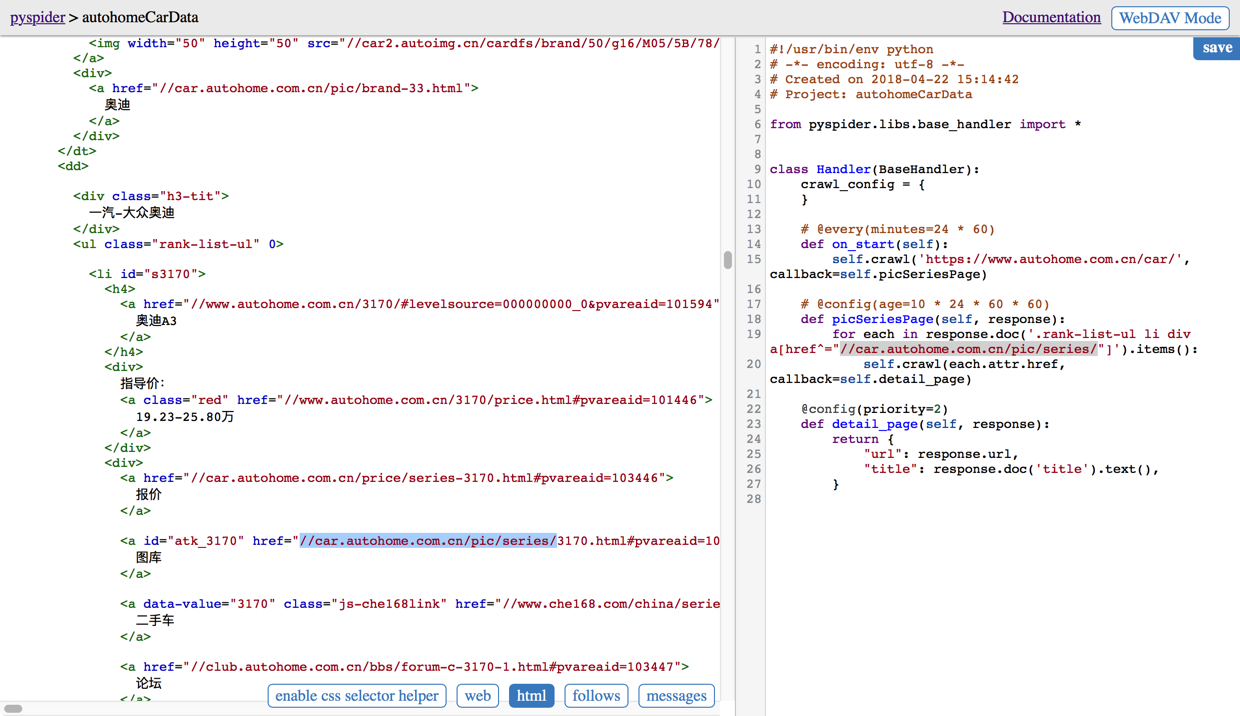
再去试了一遍,问题依旧:
点击第一个follow的Run按钮:
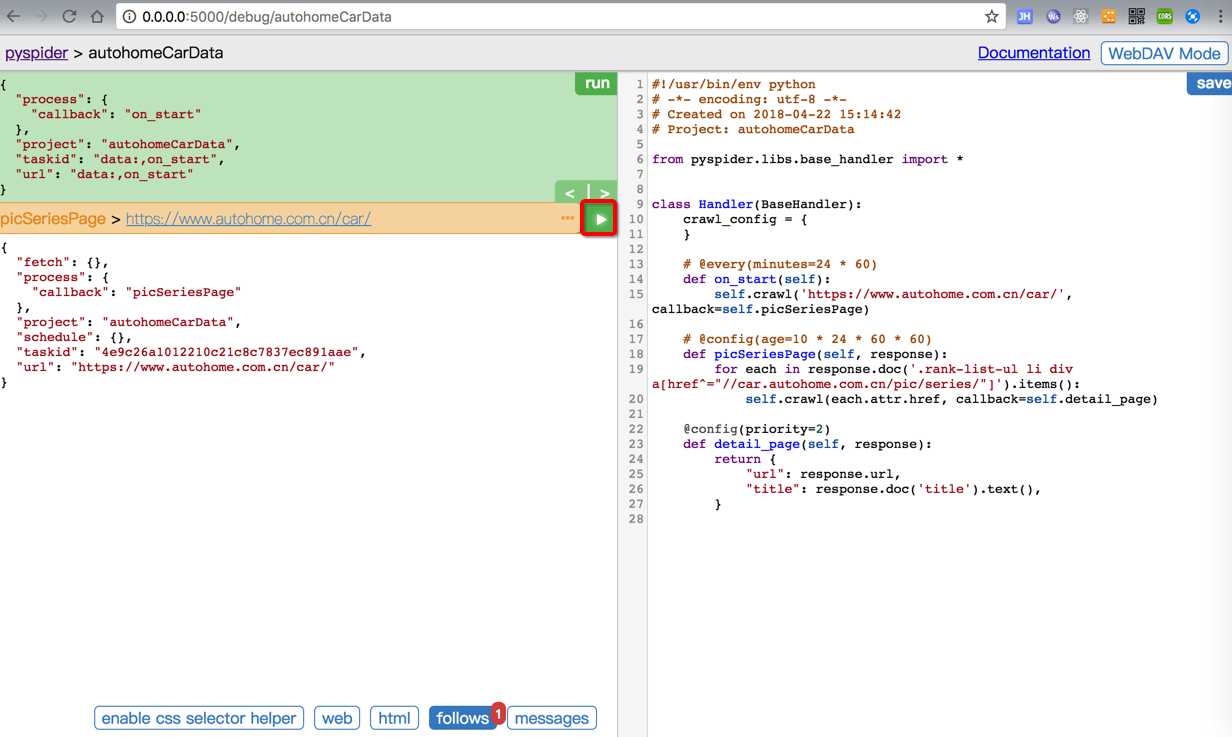
结果就没反应了,且第一个follow都没了:
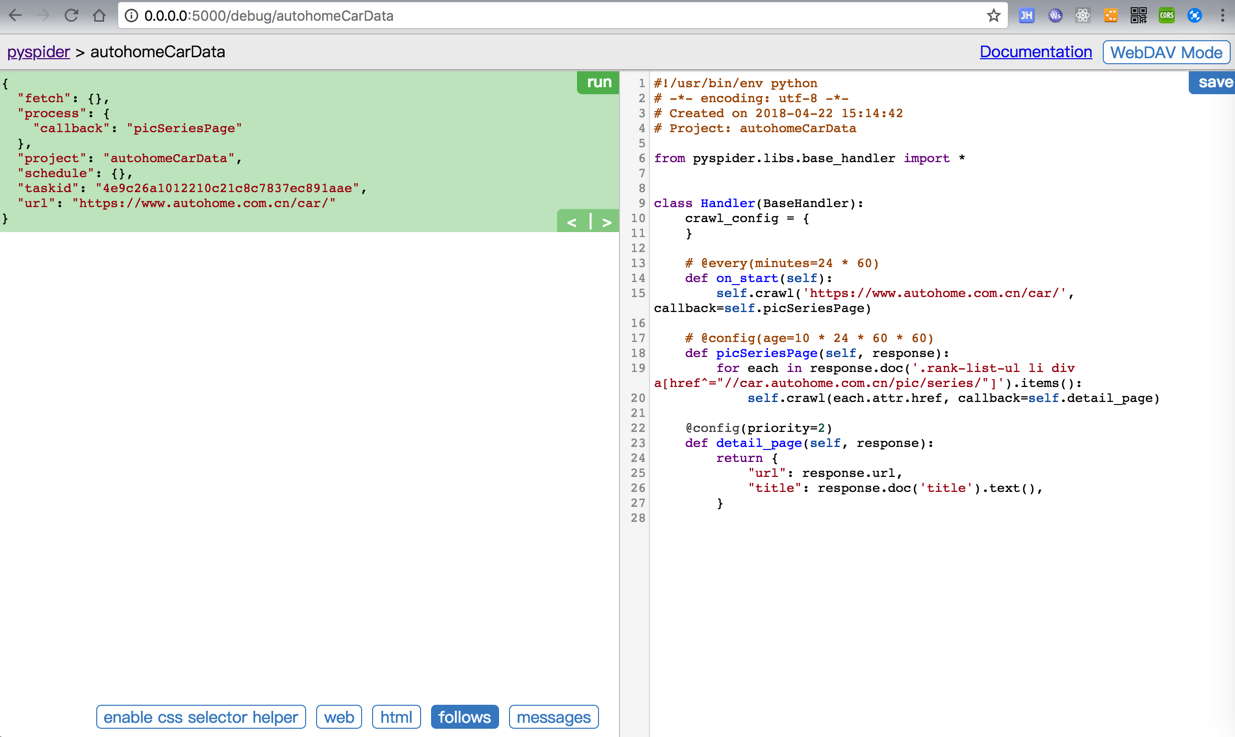
而点击html,也还是第一个主页的html的:
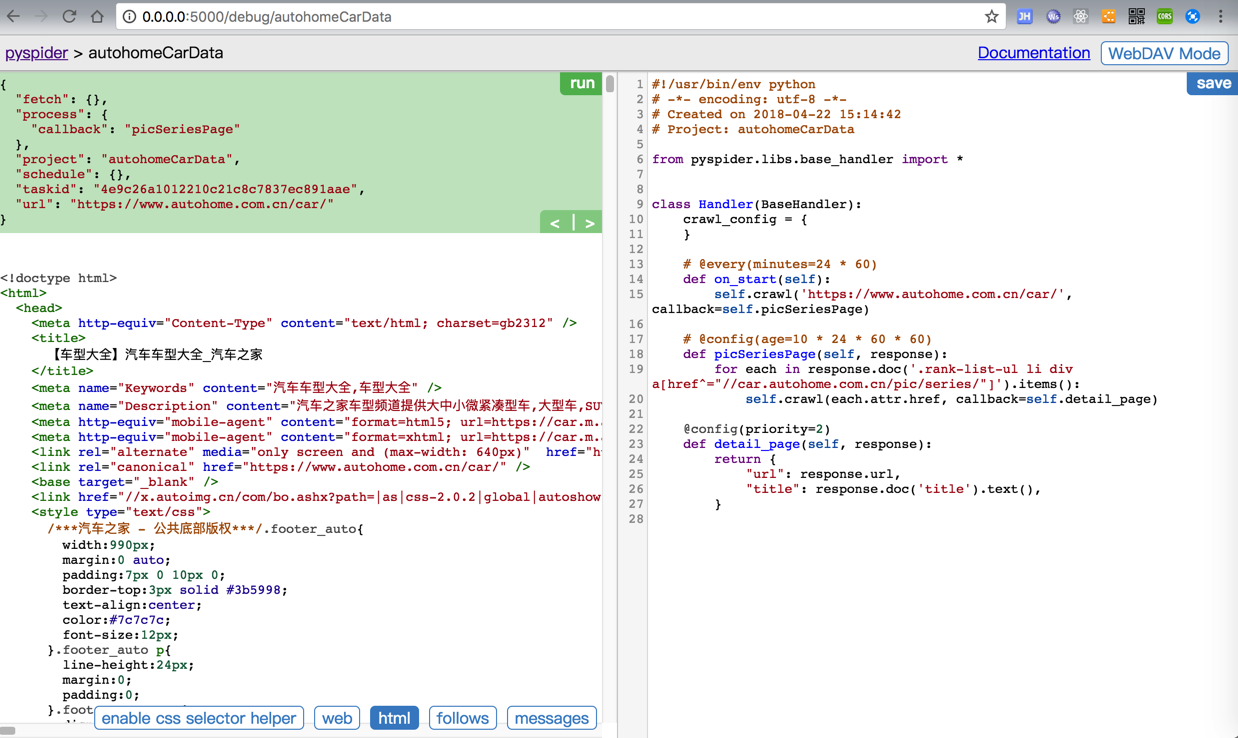
换成稍微简单点的:
<code> # for each in response.doc('.rank-list-ul li div a[href^="//car.autohome.com.cn/pic/series/"]').items():
for each in response.doc('.rank-list-ul li div a[href*="/pic/series"]').items():
</code>结果还真的可以抓取出来了:
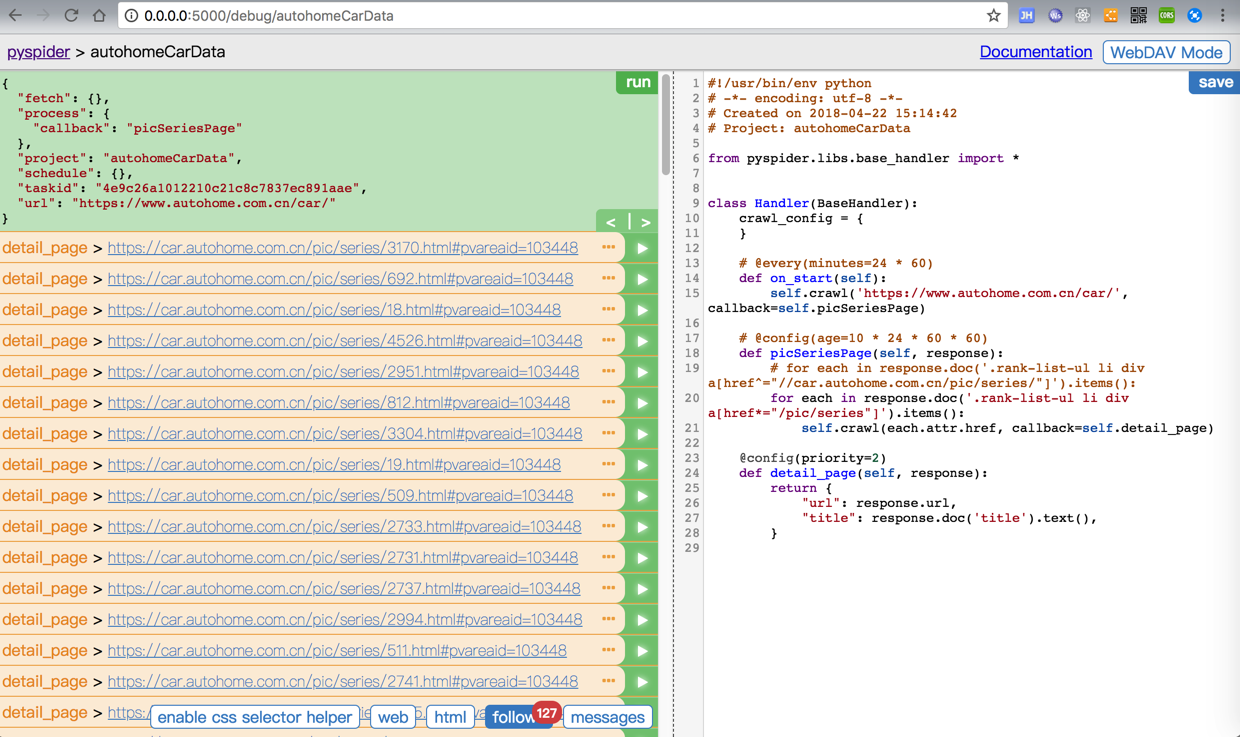
所以接着需要:
搞清楚:
<code>.rank-list-ul li div a[href^="//car.autohome.com.cn/pic/series/"] </code>
这个css selector为何不工作:
【总结】
此处,去提取想要的的内容:
<code><ul class="rank-list-ul" 0=""> <li id="s3170"> ... <div> ... <a id="atk_3170" href="//car.autohome.com.cn/pic/series/3170.html#pvareaid=103448">图库</a> ... </div> </li> ... </ul> </code>
的css选择器的写法是:
<code>for each in response.doc('.rank-list-ul li div a[href*="/pic/series"]').items():
</code>转载请注明:在路上 » 【已解决】pyspider中如何写规则去提取网页内容