折腾:
【已解决】PySpider用json.loads字符串出错:json.decoder.JSONDecodeError: Invalid \escape: line 5 column 179 (char 269)
期间,需要把字符串:
1 | Chrysanthemum loves her name — until she starts kindergarten, which is an unfamiliar world full of short names like Sue, Bill, Max, Sam, and Joe. But it\x27s Victoria who really makes Chrysanthemum wilt, offering that she was named after her grandmother, which is much more important than being named after a flower. Though Chrysanthemum\x27s parents try to soothe her wounded soul with \x26quot;hugs, kisses, and Parcheesi,\x26quot; it\x27s not easy to find solace (and regain lost self\u002Desteem) with all the girls on the playground threatening to \x26quot;pluck\x26quot; and \x26quot;smell\x26quot; you. |
去处理一下,把html中的:
\x27
\x26quot;
\u002
等entity,再去去除掉
python remove html entities
去试试html.unescape:
1 2 3 4 5 6 | descriptionValueFiltered = descriptionValue.replace("\/", "/")print("descriptionValueFiltered=%s" % descriptionValueFiltered)descriptionStr = htmlToString(descriptionValueFiltered)print("descriptionStr=%s" % descriptionStr)description = html.unescape(descriptionStr)print("description=%s" % description) |
问题依旧:
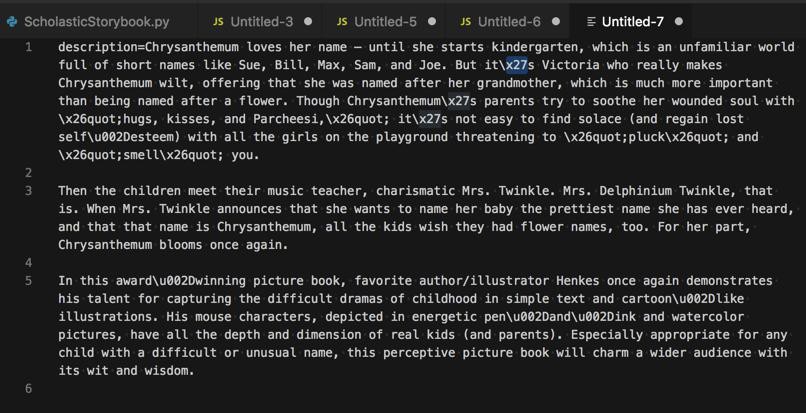
好像不是entity,而是unicode解码?
python3 unicode escape
好像直接decode即可
试试:
s.encode(‘unicode-escape’).decode(‘utf-8’)
如果还不行,再去试试codecs
结果:
1 | descriptionEscaped = descriptionStr.decode('unicode_escape') |
提示str没有decode方法?
然后:
1 | descriptionEscaped = descriptionStr.encode('unicode_escape') |
虽然可以,但是输出:
1 | descriptionEscaped=b'Chrysanthemum loves her name \\u2014 until she starts kindergarten, which is an unfamiliar world full of short names like Sue, Bill, Max, Sam, and Joe. But it\\\\x27s Victoria who really makes Chrysanthemum wilt, offering that she was named after her grandmother, which is much more important than being named after a flower. Though Chrysanthemum\\\\x27s parents try to soothe her wounded soul with \\\\x26quot;hugs, kisses, and Parcheesi,\\\\x26quot; it\\\\x27s not easy to find solace (and regain lost self\\\\u002Desteem) with all the girls on the playground threatening to \\\\x26quot;pluck\\\\x26quot; and \\\\x26quot;smell\\\\x26quot; you.\\n\\nThen the children meet their music teacher, charismatic Mrs. Twinkle. Mrs. Delphinium Twinkle, that is. When Mrs. Twinkle announces that she wants to name her baby the prettiest name she has ever heard, and that that name is Chrysanthemum, all the kids wish they had flower names, too. For her part, Chrysanthemum blooms once again.\\n\\nIn this award\\\\u002Dwinning picture book, favorite author/illustrator Henkes once again demonstrates his talent for capturing the difficult dramas of childhood in simple text and cartoon\\\\u002Dlike illustrations. His mouse characters, depicted in energetic pen\\\\u002Dand\\\\u002Dink and watercolor pictures, have all the depth and dimension of real kids (and parents). Especially appropriate for any child with a difficult or unusual name, this perceptive picture book will charm a wider audience with its wit and wisdom.' |
后续
1 | description = html.unescape(descriptionEscaped) |
也报错:
1 2 3 4 5 6 7 8 9 10 11 12 | [E 181011 17:27:17 base_handler:203] a bytes-like object is required, not 'str' Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 176, in _run_task return self._run_func(function, response, task) File "/Users/crifan/.local/share/virtualenvs/crawler_scholastic_storybook-ttmbK5Yf/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 155, in _run_func ret = function(*arguments[:len(args) - 1]) File "<ScholasticStorybook>", line 132, in singleBookCallback File "/usr/local/Cellar/python/3.6.4_4/Frameworks/Python.framework/Versions/3.6/lib/python3.6/html/__init__.py", line 130, in unescape if '&' not in s: TypeError: a bytes-like object is required, not 'str' |
再去试试:
1 2 3 4 5 6 7 8 9 10 | descriptionValueFiltered = descriptionValue.replace("\/", "/")print("descriptionValueFiltered=%s" % descriptionValueFiltered)descriptionStr = htmlToString(descriptionValueFiltered)print("descriptionStr=%s" % descriptionStr)# descriptionEscaped = descriptionStr.decode('unicode_escape')# descriptionEscaped = descriptionStr.encode('unicode_escape')descriptionEscaped = descriptionStr.encode('utf-8').decode('unicode_escape')print("descriptionEscaped=%s" % descriptionEscaped)description = html.unescape(descriptionEscaped)print("description=%s" % description) |
结果,是可以得到了基本上正常的字符串了:

但是还是有个 短横线-,变成了:â,很是奇怪
后来才发现:
原来上面的 看起来是和输入的短横线一样的字符
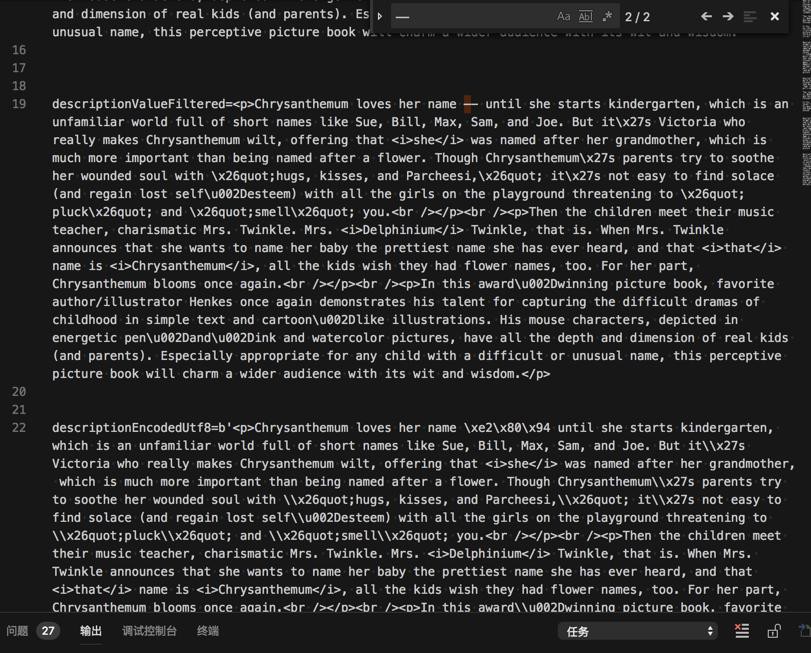
其实不是同一个:
这个是字符串中的 短横线
这个是我自己键盘输入的英文的短横线:
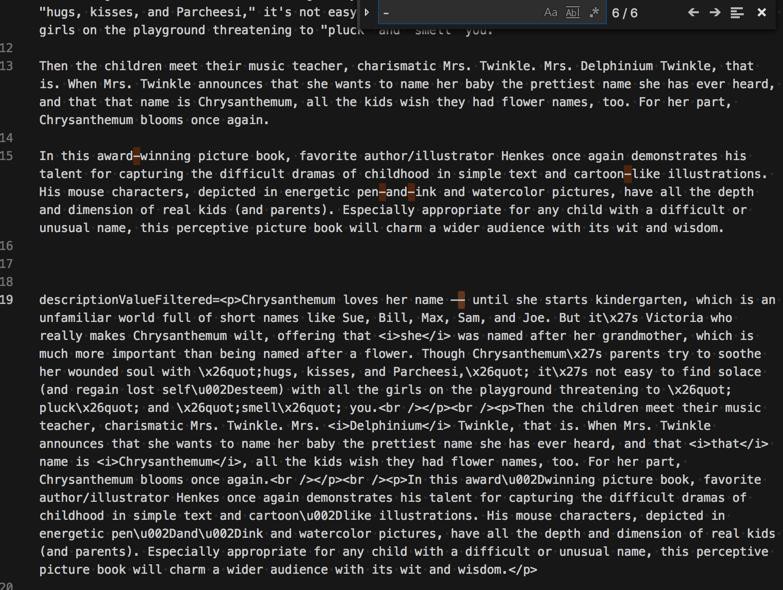
-》很明显这段文字中,多数都是英文短横线
-》而前面的—,就是一个特殊的短横线,所以被utf-8都没法编码识别的。
此处通过调试:
1 2 | descriptionEncodedUtf8 = descriptionValueFiltered.encode('utf-8')descriptionUnicodeEscaped = descriptionEncodedUtf8.decode('unicode_escape') |
而看到此特殊短横线的utf8编码值是:
1 | \xe2\x80\x94 |
-》不过,不用继续深究,那去替换掉即可:
最终用代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 | import reimport jsonimport lxmlfrom bs4 import BeautifulSoupdef htmlToString(htmlText, retainNewLine=True): if retainNewLine: htmlText = htmlText.replace("<br>", '\n') htmlText = htmlText.replace("<br/>", '\n') htmlText = htmlText.replace("<br />", '\n') print("htmlText=%s" % htmlText) soup = BeautifulSoup(htmlText, "lxml") print("soup=%s" % soup) pureText = soup.text # pureText = soup.get_text() # pureText = soup.get_text('\n') print("pureText=%s" % pureText) return pureText descriptionValueFiltered = descriptionValue.replace("\\/", "/") print("descriptionValueFiltered=%s" % descriptionValueFiltered) # replace special '—', not normal (english) '-' descriptionValueFiltered = descriptionValueFiltered.replace("—", "-") print("descriptionValueFiltered=%s" % descriptionValueFiltered) descriptionEncodedUtf8 = descriptionValueFiltered.encode('utf-8') print("descriptionEncodedUtf8=%s" % descriptionEncodedUtf8) descriptionUnicodeEscaped = descriptionEncodedUtf8.decode('unicode_escape') print("descriptionUnicodeEscaped=%s" % descriptionUnicodeEscaped) # descriptionHtmlEscaped = html.unescape(descriptionUnicodeEscaped) # print("descriptionHtmlEscaped=%s" % descriptionHtmlEscaped) descriptionStr = htmlToString(descriptionUnicodeEscaped) print("descriptionStr=%s" % descriptionStr) productJsonFiltered = productJsonFiltered.replace(descriptionValue, "") print("productJsonFiltered=%s" % productJsonFiltered) |
处理得到正常的:
没有异常字符的
有回车的
没有\uxxx, \xx
没有html的entity:"
的字符串:
1 | descriptionStr=Chrysanthemum loves her name - until she starts kindergarten, which is an unfamiliar world full of short names like Sue, Bill, Max, Sam, and Joe. But it's Victoria who really makes Chrysanthemum wilt, offering that she was named after her grandmother, which is much more important than being named after a flower. Though Chrysanthemum's parents try to soothe her wounded soul with "hugs, kisses, and Parcheesi," it's not easy to find solace (and regain lost self-esteem) with all the girls on the playground threatening to "pluck" and "smell" you.Then the children meet their music teacher, charismatic Mrs. Twinkle. Mrs. Delphinium Twinkle, that is. When Mrs. Twinkle announces that she wants to name her baby the prettiest name she has ever heard, and that that name is Chrysanthemum, all the kids wish they had flower names, too. For her part, Chrysanthemum blooms once again.In this award-winning picture book, favorite author\/illustrator Henkes once again demonstrates his talent for capturing the difficult dramas of childhood in simple text and cartoon-like illustrations. His mouse characters, depicted in energetic pen-and-ink and watercolor pictures, have all the depth and dimension of real kids (and parents). Especially appropriate for any child with a difficult or unusual name, this perceptive picture book will charm a wider audience with its wit and wisdom. |
【后记】
后来发现,对于p,soup也没有变成换行:
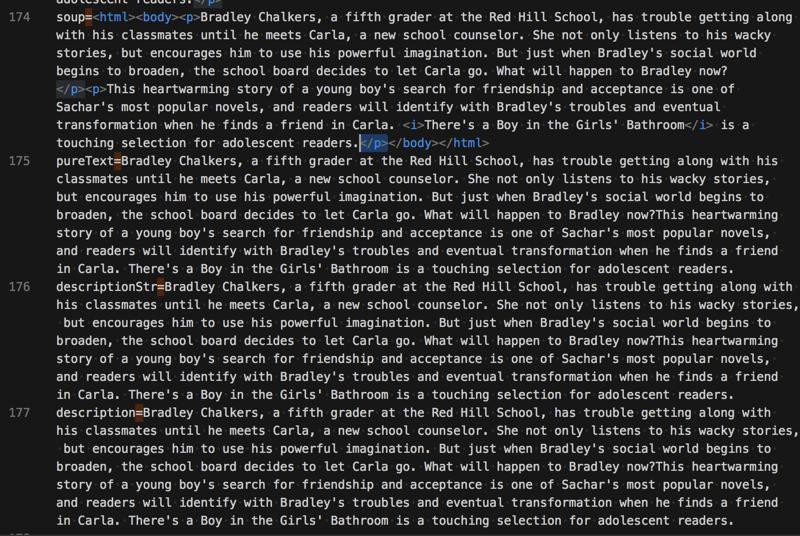
所以改为:
顺带优化了<br>的replace为re.sub,支持更多可能性:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | def htmlToString(htmlText, retainNewLine=True): if retainNewLine: # htmlText = htmlText.replace("<br>", '\n') # htmlText = htmlText.replace("<br/>", '\n') # htmlText = htmlText.replace("<br />", '\n') htmlText = re.sub("<br\s*/?>", "\n", htmlText) htmlText = re.sub("</p>", "\n", htmlText) print("htmlText=%s" % htmlText) soup = BeautifulSoup(htmlText, "lxml") print("soup=%s" % soup) pureText = soup.text # pureText = soup.get_text() # pureText = soup.get_text('\n') print("pureText=%s" % pureText) pureText = pureText.strip() return pureText |
效果是:
<br>和</p>加了换行
再去用strip去掉最后一个</p>的多余的换行
转载请注明:在路上 » 【已解决】PySpider中把一段html的字符串去除entity和unicode escape转义