折腾:
期间,虽然已解决了:
但是又出错:
1 2 3 4 5 6 7 | [E 190329 10:43:58 base_handler:203] self.__call__() not implemented! Traceback (most recent call last): File "/Users/crifan/.local/share/virtualenvs/crawler_xiaohuasheng_app-zY4wnqo9/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/crifan/.local/share/virtualenvs/crawler_xiaohuasheng_app-zY4wnqo9/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 168, in _run_task raise NotImplementedError("self.%s() not implemented!" % callback) NotImplementedError: self.__call__() not implemented! |
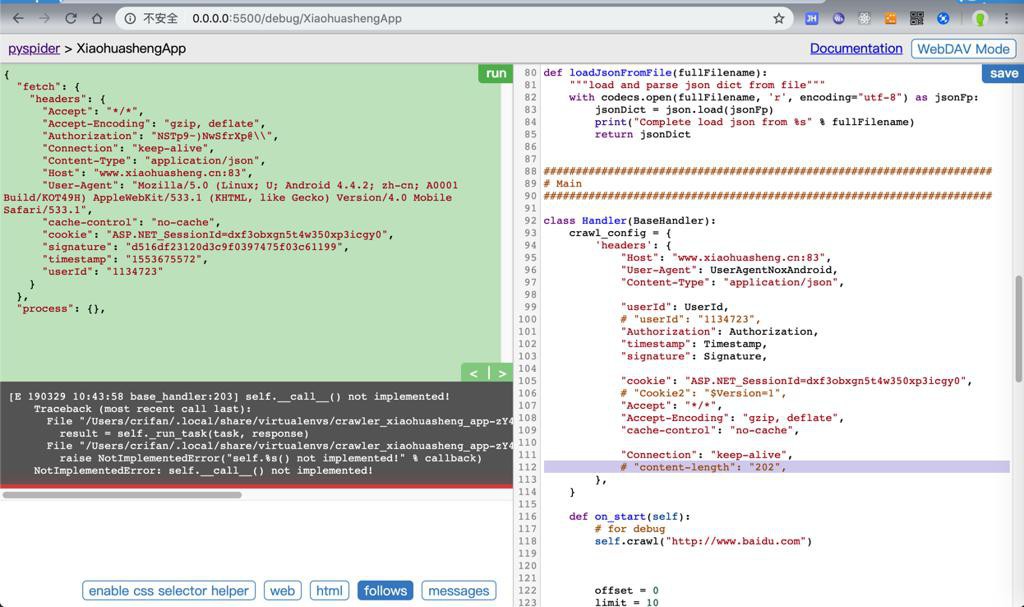
那去掉整个headers试试
问题依旧还是:
1 | NotImplementedError: self.__call__() not implemented! |
搜:
PySpider NotImplementedError: self.__call__() not implemented
难道是没加callback所以不执行?
通过换用:
网页打开,get会返回:
{“M”:”9998″}
所以试试访问这个如何
1 2 3 4 5 6 | # for debug self.crawl(ParentChildReadingUrl, method="GET", callback=self.getParentChildReadingCallback, save=parentChildReadingParamDict ) |
是可以的:
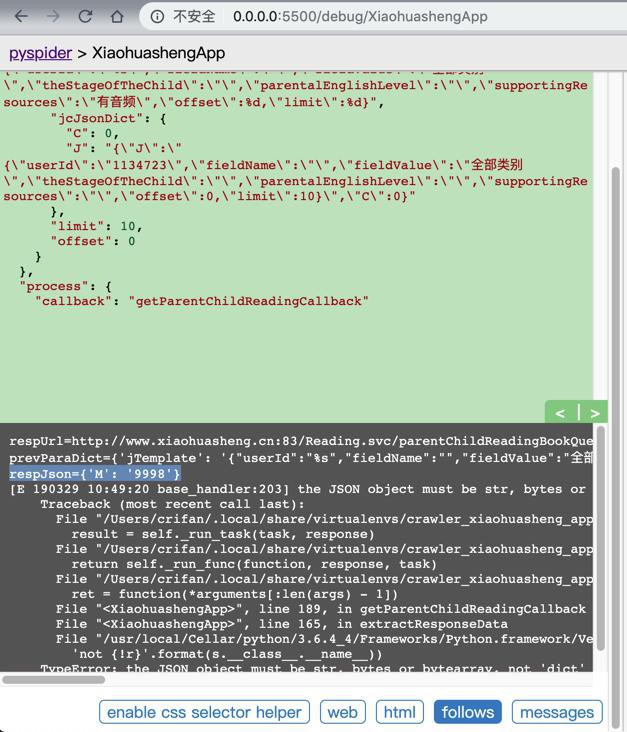
-》说明url请求没问题。
-》说明正常加了callback,估计就可以了。
-》也再次注意到了,出错提示中有:
raise NotImplementedError(“self.%s() not implemented!” % callback)
说的就是callback参数没有加
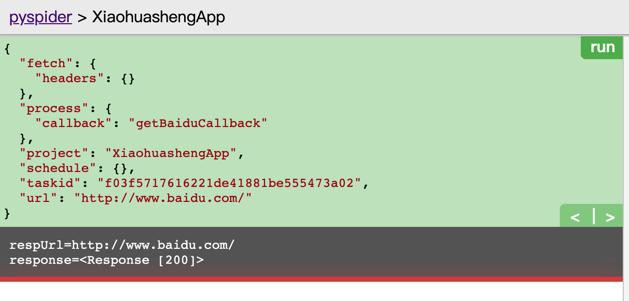
然后去试试
1 2 3 4 5 6 7 8 9 | def on_start(self): # for debug def getBaiduCallback(self, response): respUrl = response.url print("respUrl=%s" % respUrl) print("response=%s" % response) |
即可正常返回内容:
1 2 | respUrl=http://www.baidu.com/response=<Response [200]> |
【总结】
PySpider中的self.crawl中,如果没有加上callback参数,则会报错:
1 2 | raise NotImplementedError("self.%s() not implemented!" % callback) NotImplementedError: self.__call__() not implemented! |
解决办法是:
必须加上callback参数
备注说明:
-》否则你获取某个页面,但是不处理返回内容,等价于无用操作
-》所以此处提示你必须要加上callback才行
-》只不过此处最终的报错信息:
NotImplementedError: self.__call__() not implemented!
解释的不够清楚,而错误信息堆栈中的:
raise NotImplementedError(“self.%s() not implemented!” % callback)
则解释清楚,是需要我们是实现callback参数才可以。
转载请注明:在路上 » 【已解决】PySpider中执行self.crawl出错:NotImplementedError self.__call__() not implemented