折腾:
【未解决】用Python爬取汽车之家的车型车系详细数据
期间,
去写代码调试
1 2 3 4 5 6 7 8 9 10 | class Handler(BaseHandler): UserAgent_Mac_Chrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36" crawl_config = { "User-Agent": UserAgent_Mac_Chrome, } # @every(minutes=24 * 60) def on_start(self): self.crawl(autohomeEntryUrl, callback=self.carBrandListCallback) |
还是会
HTTP 403: Forbidden
1 2 3 4 5 6 7 8 9 | [E 200814 20:38:23 base_handler:203] HTTP 403: Forbidden Traceback (most recent call last): File "/Users/xxx/.pyenv/versions/3.6.5/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 196, in run_task result = self._run_task(task, response) File "/Users/xxx/.pyenv/versions/3.6.5/lib/python3.6/site-packages/pyspider/libs/base_handler.py", line 175, in _run_task response.raise_for_status() File "/Users/xxx/.pyenv/versions/3.6.5/lib/python3.6/site-packages/pyspider/libs/response.py", line 184, in raise_for_status raise http_error requests.exceptions.HTTPError: HTTP 403: Forbidden |
看了看html是:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | <html> <head> <title> ERROR: ACCESS DENIED </title> </head> <body> <center> <h1> ERROR: ACCESS DENIED </h1> </center> <hr> <center> Fri, 14 Aug 2020 12:38:23 GMT (taikoo/BC232_dx-jiangsu-xuzhou-4-cache-1) </center> </BODY> </HTML><!-- web cache --> |
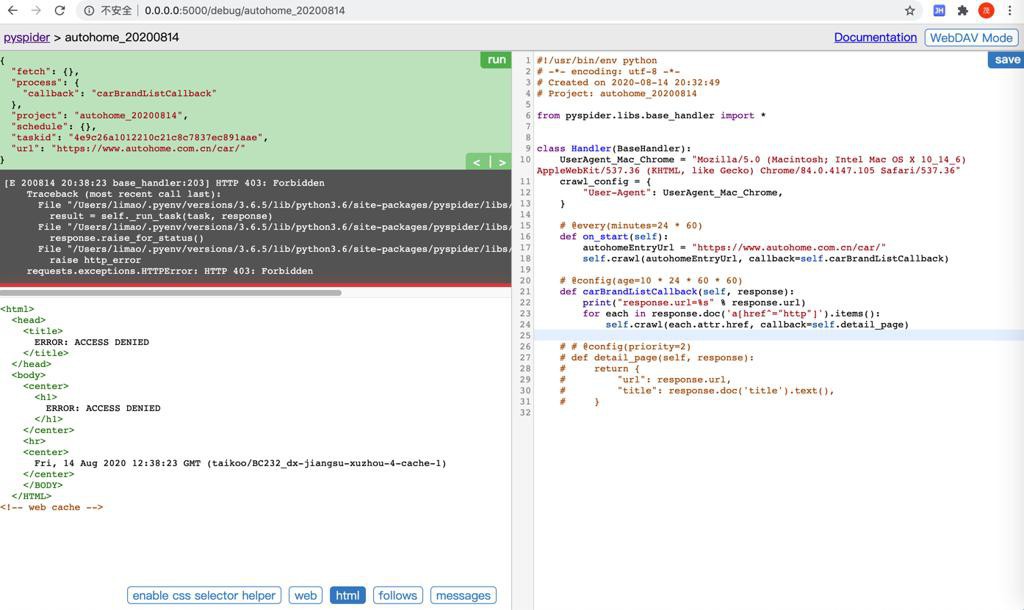
去看了看:
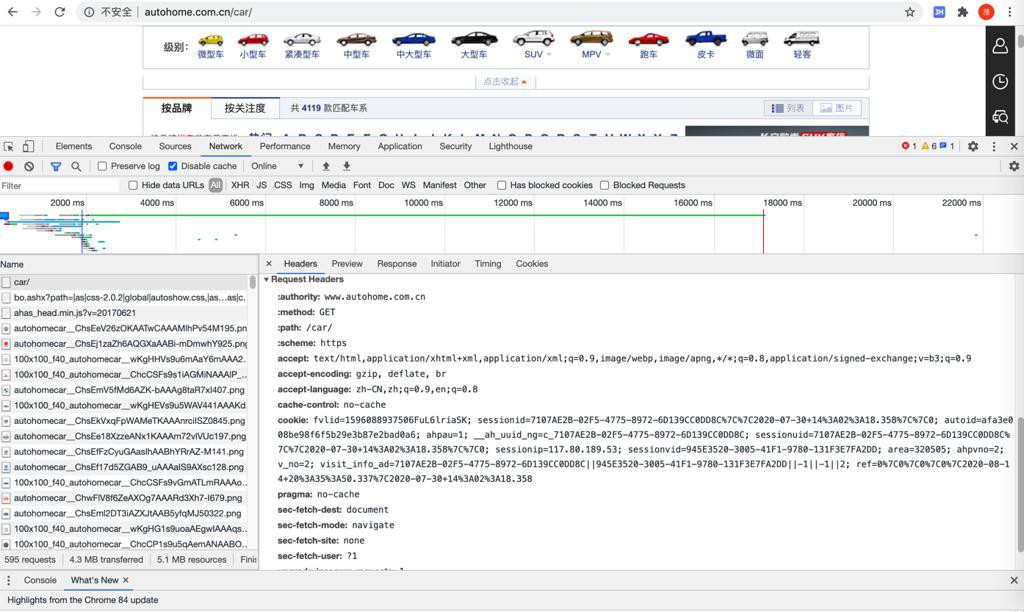
request headers还是不少的
尤其是cookie,感觉还是不容易解决。
在想,万一不好解决,就换:puppeteer
先去加上一些其他header试试
写错了,改为:
1 2 3 4 5 | crawl_config = { "headers": { "User-Agent": UserAgent_Mac_Chrome, } } |
结果:
还真就可以了。。。
【总结】
此处加上User-Agent:
1 2 3 4 5 6 7 8 9 10 11 12 13 | class Handler(BaseHandler): UserAgent_Mac_Chrome = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.105 Safari/537.36" crawl_config = { "headers": { "User-Agent": UserAgent_Mac_Chrome, } } # @every(minutes=24 * 60) def on_start(self): self.crawl(autohomeEntryUrl, callback=self.carBrandListCallback) |
即可。
转载请注明:在路上 » 【已解决】PySpider访问汽车之家报错:requests.exceptions.HTTPError HTTP 403 Forbidden