折腾:
【已解决】把文本格式的剧本内容用Python批量导入后台系统
期间,就是去写正则去匹配这种内容:
<code>Place: School canteen Topic: food Tittle:Have lunch Age: 3-4 J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. Place: home Topic: house Tittle: Doing housework Age: 4-5 J: Do you like cooking, mom? M: Yes, I do a lot. What about you? J: Mom, you know me. I can’t cook. M: But can you help me wash dishes? J: Yes, I can help you. M: Let’s make a deal, ok? J: What kind of deal? M: I’m going to cook. J: And then? M: Then you wash the dishes after the meal. J: That’s ok. I’ d like to help you mom. M: You are a good boy. Place: Dentist Topic: Health-dentist Tittle:Toothache Age: 4-5 L: Hi, Mr. Smith. D: What’s wrong? L: I have a toothache. D: Open your mouth and say “Ahh”. L: Ahh… D: You have a bad tooth. L: Really? What should I do? D: You should brush your teeth three times a day. L: Okay. What else? D: Don’t eat too many sweets. L: Why? D: Eating too many, you will have a toothache. L: Ohh, it hurts. D: So don’t eat too many. L: Yes, Mr. Smith. Thank you! D: You’re welcome. Place: outside Topic: People-celebration Tittle:Halloween ... </code>
了。
其中对于:
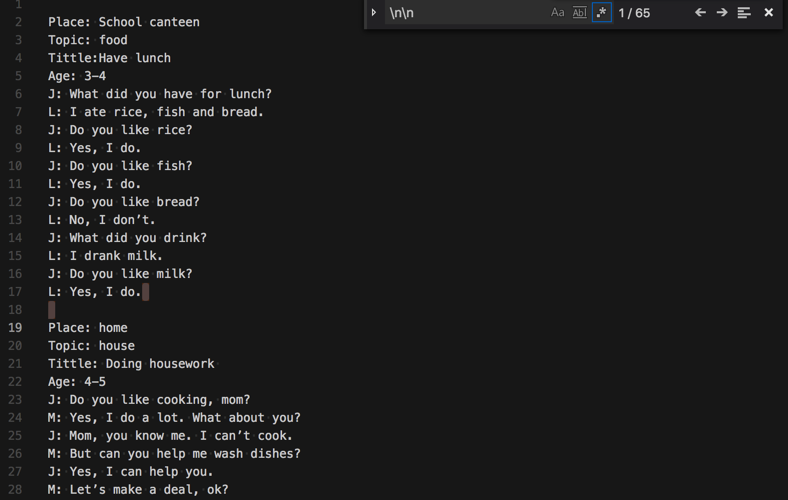
两段之间,有2个或更多个回车换行\n
的格式,要去写正则匹配
所以继续研究如何给re.search添加flags
已经匹配2或更多个\n的写法
python re 个数限制
python re flag example
python re multiple flag
6.2. re — Regular expression operations — Python 3.7.0 documentation
Regular Expression HOWTO — Python 3.7.0 documentation
regex – Using more than one flag in python re.findall – Stack Overflow
然后试了多次,遇到一些坑和心得,记录下来:
(1)(re.search或其他re的函数中的)多个flags时,中间用逻辑或
<code>scriptMatch = re.search("(?P<singleScript>place.+)\n{2,1000}", allLine, flags=re.I | re.M | re.DOTALL)
</code>(2)多行Multi Line模式时,只有加上re.DOTALL,其中的点.才能匹配换行符newline
试了试:
<code># scriptMatch = re.search("(?P<singleScript>place.+)\n\n+", allLine, flags=re.I | re.M)
scriptMatch = re.search("(?P<singleScript>place.+)\n{2, 1000}", allLine, flags=re.I | re.M)
</code>结果搜不到:

而此处之所以搜不到,则看起来是因为:
re.DOTALL
的问题:
https://docs.python.org/3/library/re.html#re.DOTALL
“re.DOTALL
Make the ‘.’ special character match any character at all, including a newline; without this flag, ‘.’ will match anything except a newline. Corresponds to the inline flag (?s).”
(2)xxx{m,n}的m和n中间不能有多余空格
<code>scriptMatch = re.search("(?P<singleScript>place.+)\n{2, 1000}", allLine, flags=re.I | re.M | re.DOTALL)
</code>是匹配不到的:

原因是:
<code>\n{m,n}
</code>中m和n中间不能有空格:
<code>\n{m, n}
</code>即:
只能是:
<code>\n{2,1000}
</code>不能是:
<code>\n{2, 1000}
</code>否则匹配不到。
然后接着试试,用:
<code>scriptMatch = re.search("(?P<singleScript>place.+?)\n{2,1000}", allLine, flags=re.I | re.M | re.DOTALL)
</code>匹配到了,第一个script:

其中
<code>place.+? </code>
是非贪婪匹配,否则如果用
<code>place.+ </code>
则会匹配到整个文件的所有的script,不是我们要的效果了。
然后再去考虑,如何匹配多个组,分组的分组:
然后此处已经可以获得基本的要搜索的几个字段了,包括:
place,topic,title,age,content
不过要继续去想办法,看看是否可以直接从content中获取:
A:xxx
B:yyy
的对话组,而不用再去解析一遍了
其中想到了,用:
https://docs.python.org/3/library/re.html#re.VERBOSE
re.VERBOSE实现:
在复杂的正则中运行多余的空白分割和注释
-》便于自己和别人看懂正则的含义
不过发现此处情况特殊:
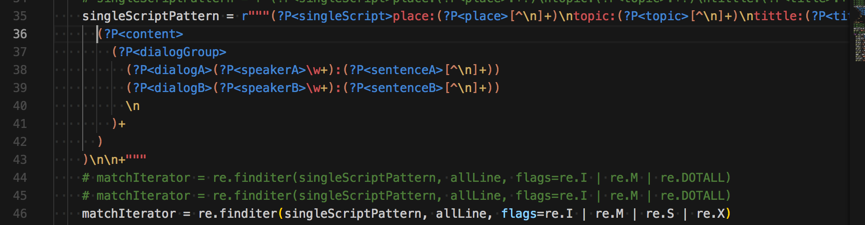
<code> singleScriptPattern = r"""(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n (?P<content> (?P<dialogGroup> (?P<dialogA>(?P<speakerA>\w+):(?P<sentenceA>[^\n]+)) (?P<dialogB>(?P<speakerB>\w+):(?P<sentenceB>[^\n]+)) \n )+ ) )\n\n+""" # matchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL) # matchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL) matchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.S | re.X) </code>
其中的很多个(?P<groupName>xxx)中的多个xxx都是包含多余的回车和换行和空白字符
所以导致不匹配了。
所以还是要去除上面的缩紧空白和换行。
结果:
<code>singleScriptPattern = r"""(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>(?P<dialogGroup>(?P<dialogA>(?P<speakerA>\w+):(?P<sentenceA>[^\n]+))(?P<dialogB>(?P<speakerB>\w+):(?P<sentenceB>[^\n]+))\n)+))\n\n+""" </code>
太复杂了,导致不知道中间哪个位置出错,而搜不出来了。
去慢慢增加复杂度
<code>singleScriptPattern = r"""(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>(?P<dialogGroup>\w+:[^\n]+\n)+)\n\n+""" </code>
结果语法错误:
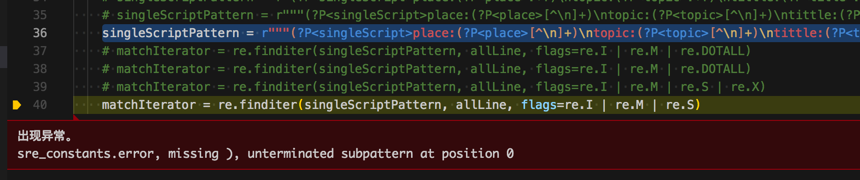
<code>出现异常。 sre_constants.error, missing ), unterminated subpattern at position 0 </code>
改为:
<code>singleScriptPattern = r"""(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>(?P<dialogGroup>\w+:[^\n]+\n)+))\n\n+""" </code>
结果只能搜索到其中一个,其他的就搜不到了。
算了,content内部的dialogGroup的dialogA和dialogB的格式太复杂,还是单独弄出来去匹配吧
所以总体上还是用之前的:
<code>singleScriptPattern = r"(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>.+?))\n\n+" </code>
然后得到了content后,再去处理
然后用:
<code> singleDialogPattern = r"(?P<speaker>\w+):\s*(?P<sentence>[^\n]+)\n"
singleDialogMatchIterator = re.finditer(singleDialogPattern, content, flags=re.I | re.M | re.S)
for dialogIdx, eachDialog in enumerate(singleDialogMatchIterator):
dialogNum = dialogIdx + 1
print("[%d] eachDialog=%s" % (dialogNum, eachDialog))
speaker = eachDialog.group("speaker")
print("speaker=%s" % speaker)
sentence = eachDialog.group("sentence")
print("sentence=%s" % sentence)
</code>是可以正常处理单个的content的:
<code>J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. </code>
结果是:
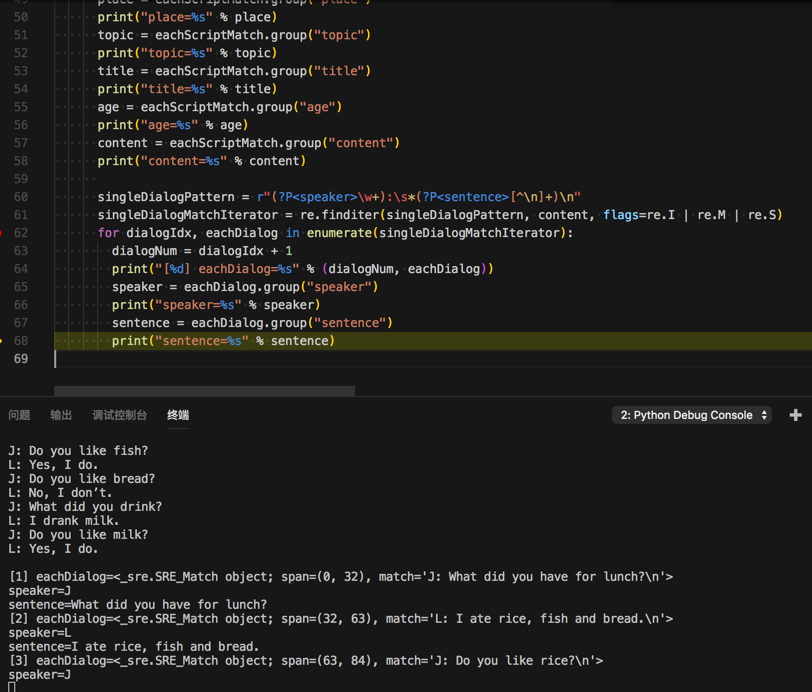
<code>content=J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. [1] eachDialog=<_sre.SRE_Match object; span=(0, 32), match='J: What did you have for lunch?\n'> speaker=J sentence=What did you have for lunch? [2] eachDialog=<_sre.SRE_Match object; span=(32, 63), match='L: I ate rice, fish and bread.\n'> speaker=L sentence=I ate rice, fish and bread. [3] eachDialog=<_sre.SRE_Match object; span=(63, 84), match='J: Do you like rice?\n'> speaker=J sentence=Do you like rice? [4] eachDialog=<_sre.SRE_Match object; span=(84, 98), match='L: Yes, I do.\n'> speaker=L sentence=Yes, I do. [5] eachDialog=<_sre.SRE_Match object; span=(98, 119), match='J: Do you like fish?\n'> speaker=J sentence=Do you like fish? [6] eachDialog=<_sre.SRE_Match object; span=(119, 133), match='L: Yes, I do.\n'> speaker=L sentence=Yes, I do. [7] eachDialog=<_sre.SRE_Match object; span=(133, 155), match='J: Do you like bread?\n'> speaker=J sentence=Do you like bread? [8] eachDialog=<_sre.SRE_Match object; span=(155, 171), match='L: No, I don’t.\n'> speaker=L sentence=No, I don’t. [9] eachDialog=<_sre.SRE_Match object; span=(171, 194), match='J: What did you drink?\n'> speaker=J sentence=What did you drink? [10] eachDialog=<_sre.SRE_Match object; span=(194, 211), match='L: I drank milk.\n'> speaker=L sentence=I drank milk. [11] eachDialog=<_sre.SRE_Match object; span=(211, 232), match='J: Do you like milk?\n'> speaker=J sentence=Do you like milk? [12] eachDialog=<_sre.SRE_Match object; span=(232, 246), match='L: Yes, I do.\n'> speaker=L sentence=Yes, I do. </code>
然后至此算是达到希望的效果了。
【总结】
此处对于内容:
<code> Place: School canteen Topic: food Tittle:Have lunch Age: 3-4 J: What did you have for lunch? L: I ate rice, fish and bread. J: Do you like rice? L: Yes, I do. J: Do you like fish? L: Yes, I do. J: Do you like bread? L: No, I don’t. J: What did you drink? L: I drank milk. J: Do you like milk? L: Yes, I do. Place: home Topic: house Tittle: Doing housework Age: 4-5 J: Do you like cooking, mom? M: Yes, I do a lot. What about you? J: Mom, you know me. I can’t cook. M: But can you help me wash dishes? J: Yes, I can help you. M: Let’s make a deal, ok? J: What kind of deal? M: I’m going to cook. J: And then? M: Then you wash the dishes after the meal. J: That’s ok. I’ d like to help you mom. M: You are a good boy. ... </code>
用代码:
<code>
with open(eachFullFilePath, "r") as fp:
allLine = fp.read()
# print("allLine=%s" % allLine)
# scriptMatch = re.search("(?P<singleScript>place.+)\n\n+", allLine, flags=re.I | re.M)
# scriptMatch = re.search("(?P<singleScript>place.+)\n{2, 1000}", allLine, flags=re.I | re.M | re.DOTALL)
# scriptMatch = re.search("(?P<singleScript>place.+)\n{2,1000}", allLine, flags=re.I | re.M | re.DOTALL)
# scriptMatch = re.search("(?P<singleScript>place.+?)\n{2,1000}", allLine, flags=re.I | re.M | re.DOTALL)
# scriptMatch = re.search("(?P<scriptList>(?P<singleScript>place.+?)\n{2,1000})+", allLine, flags=re.I | re.M | re.DOTALL)
# singleScriptPattern = r"(?P<singleScript>place:.+?)\n{2,1000}"
# singleScriptPattern = r"place:.+?\n{2,1000}"
# singleScriptPattern = "place:.+?\n{2,1000}"
# singleScriptPattern = r"(?P<singleScript>place:(?P<place>.+?)\ntopic:(?P<topic>.+?)\ntittle:(?P<title>.+?)\nage:(?P<age>.+?)\n(?P<content>.+?))\n{2,1000}"
# singleScriptPattern = r"(?P<singleScript>place:(?P<place>.+?)\ntopic:(?P<topic>.+?)\ntittle:(?P<title>.+?)\nage:(?P<age>.+?)\n(?P<content>.+?))\n\n+"
# singleScriptPattern = r"""(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>(?P<dialogGroup>(?P<dialogA>(?P<speakerA>\w+):(?P<sentenceA>[^\n]+))(?P<dialogB>(?P<speakerB>\w+):(?P<sentenceB>[^\n]+))\n)+))\n\n+"""
# singleScriptPattern = r"(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>.+?))\n\n+"
singleScriptPattern = r"(?P<singleScript>place:(?P<place>[^\n]+)\ntopic:(?P<topic>[^\n]+)\ntittle:(?P<title>[^\n]+)\nage:(?P<age>[^\n]+)\n(?P<content>.+?\n))\n+"
# allScriptMatchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL)
# allScriptMatchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.DOTALL)
# allScriptMatchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.S | re.X)
allScriptMatchIterator = re.finditer(singleScriptPattern, allLine, flags=re.I | re.M | re.S)
print("allScriptMatchIterator=%s" % allScriptMatchIterator)
# if allScriptMatchIterator:
for scriptIdx, eachScriptMatch in enumerate(allScriptMatchIterator):
scriptNum = scriptIdx + 1
print("[%d] eachScriptMatch=%s" % (scriptNum, eachScriptMatch))
singleScript = eachScriptMatch.group("singleScript")
print("singleScript=%s" % singleScript)
place = eachScriptMatch.group("place")
print("place=%s" % place)
topic = eachScriptMatch.group("topic")
print("topic=%s" % topic)
title = eachScriptMatch.group("title")
print("title=%s" % title)
age = eachScriptMatch.group("age")
print("age=%s" % age)
content = eachScriptMatch.group("content")
print("content=%s" % content)
singleDialogPattern = r"(?P<speaker>\w+):\s*(?P<sentence>[^\n]+)\n"
singleDialogMatchIterator = re.finditer(singleDialogPattern, content, flags=re.I | re.M | re.S)
for dialogIdx, eachDialog in enumerate(singleDialogMatchIterator):
dialogNum = dialogIdx + 1
print("[%d] eachDialog=%s" % (dialogNum, eachDialog))
speaker = eachDialog.group("speaker")
print("speaker=%s" % speaker)
sentence = eachDialog.group("sentence")
print("sentence=%s" % sentence)
</code>可以解析出我们要的:
txt中多个script:
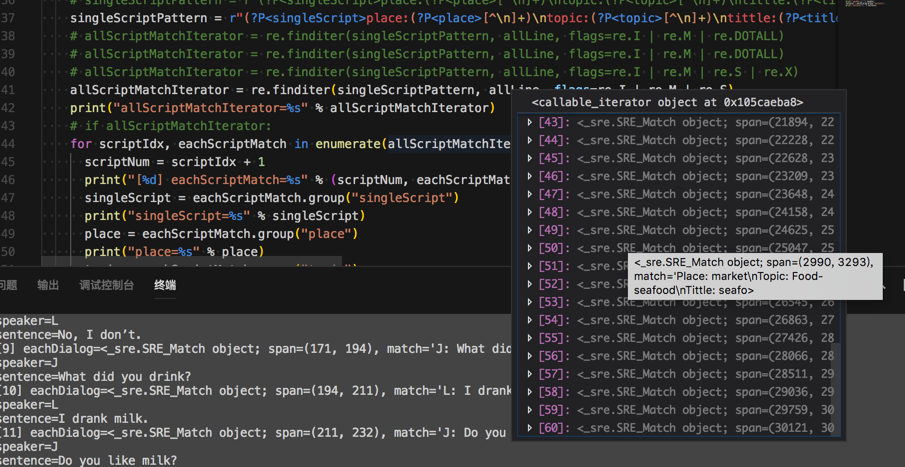
一个script的不同字段,以及每个script的content中多行:
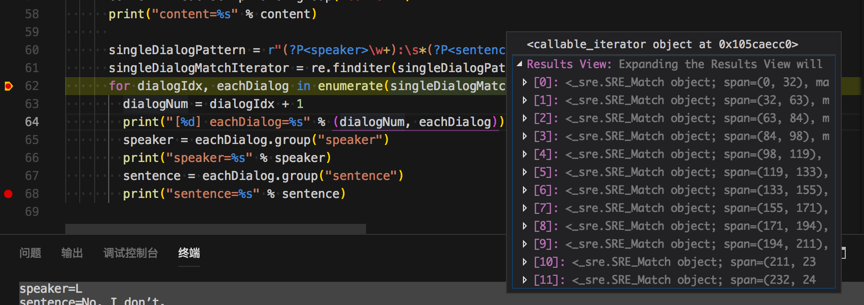
中每一行的speaker和sentences了:
转载请注明:在路上 » 【已解决】Python 3中用正则匹配多段的脚本内容