折腾:
【未解决】从匹配的170个host所找到的历史url手动整理出规则
期间,调试先保存出100个,发现:
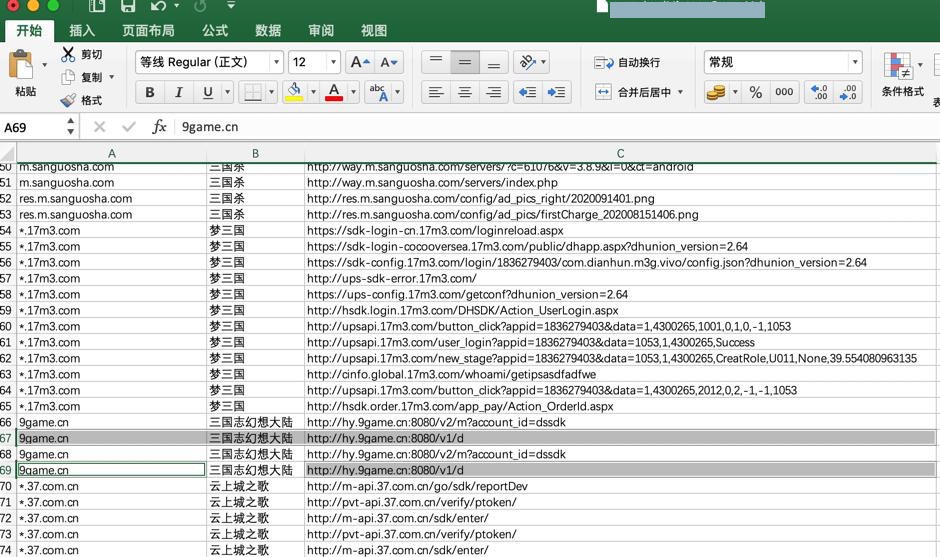
有完全重复的数据:
1 2 3 | 9game.cn 三国志幻想大陆 http://hy.9game.cn:8080/v1/d9game.cn 三国志幻想大陆 http://hy.9game.cn:8080/v1/d |
看来需要后续去去重。
python dict list unique
Python 3
1 2 3 4 5 6 7 | >>> L=[... {'id':1,'name':'john', 'age':34},... {'id':1,'name':'john', 'age':34},... {'id':2,'name':'hanna', 'age':30},... ]>>> list({v['id']:v for v in L}.values())[{'age': 34, 'id': 1, 'name': 'john'}, {'age': 30, 'id': 2, 'name': 'hanna'}] |
去试试
好像可以用:
values,变成tuple,然后再用set去重,再转回dict的list
期间涉及到:
想要去把keys和values
1 2 3 4 | uniquedDictList = [] for eachValueTuple in valueSet: uniquedDictList = { } |
合并成dict
后来发现不需要。
用:
1 2 3 4 5 | itemsSet = {} for eachDict in dictList: # dictItems = eachDict.items() # dict_items([('hostRule', 'm.sanguosha.com'), ('gameName', '三国杀'), ('gameUrl', 'http://way.m.sanguosha.com/update/?c=61100&v=3.8.9&l=0&cl=0&ct=android')]) dictItems = list(eachDict.items()) # tuple list: [('hostRule', 'm.sanguosha.com'), ('gameName', '三国杀'), ('gameUrl', 'http://way.m.sanguos...ct=android')] itemsSet.add(dictItems) |
报错:
1 2 | 发生异常: AttributeError'dict' object has no attribute 'add' |

搞错了,应该是:
1 | itemsSet = () |
也不对:
1 2 | 发生异常: AttributeError'tuple' object has no attribute 'add' |
参考:
是:
1 2 3 4 5 6 | itemsSet = set() for eachDict in dictList: # dictItems = eachDict.items() # dict_items([('hostRule', 'm.sanguosha.com'), ('gameName', '三国杀'), ('gameUrl', 'http://way.m.sanguosha.com/update/?c=61100&v=3.8.9&l=0&cl=0&ct=android')]) dictItems = list(eachDict.items()) # tuple list: [('hostRule', 'm.sanguosha.com'), ('gameName', '三国杀'), ('gameUrl', 'http://way.m.sanguos...ct=android')] itemsSet.add(dictItems) |
支持:
Use update to add elements from tuples, sets, lists or frozen-sets
报错:
1 2 | 发生异常: TypeErrorunhashable type: 'list' |
换成update
1 | itemsSet.update(dictItems) |
突然想到:
估计是内部直接变成多个元素了??
如果是,那就不是我们要的
想要这个 复杂的tuple的list 是单个集合元素
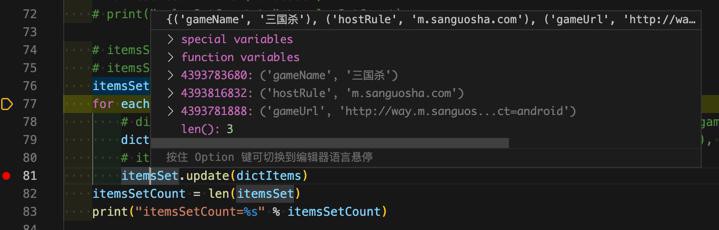
果然是的:
update,变成,把值,拆分成多个(可hash的)元素,加进去了。。。
此处加了3个元素。。。
不是我们要的
算了,只能用:
最简单的for循环去处理了
python list unique
python list unique function
1 | dictList = dictList.unique() |
没有unique函数
用自己之前的试试:
1 2 3 4 5 6 7 8 9 10 11 | # remove overlapped item in the listdef uniqueList(old_list): newList = [] for x in old_list: if x not in newList : newList.append(x) return newListdictList = uniqueList(dictList) |
看看dict能否判断是否相等 或者 in list
1 2 3 4 5 6 7 8 9 | def uniqueList(old_list): newList = [] for curItem in old_list: if curItem not in newList: newList.append(curItem) else: # for debug print("Duplicated %s" % curItem) return newList |
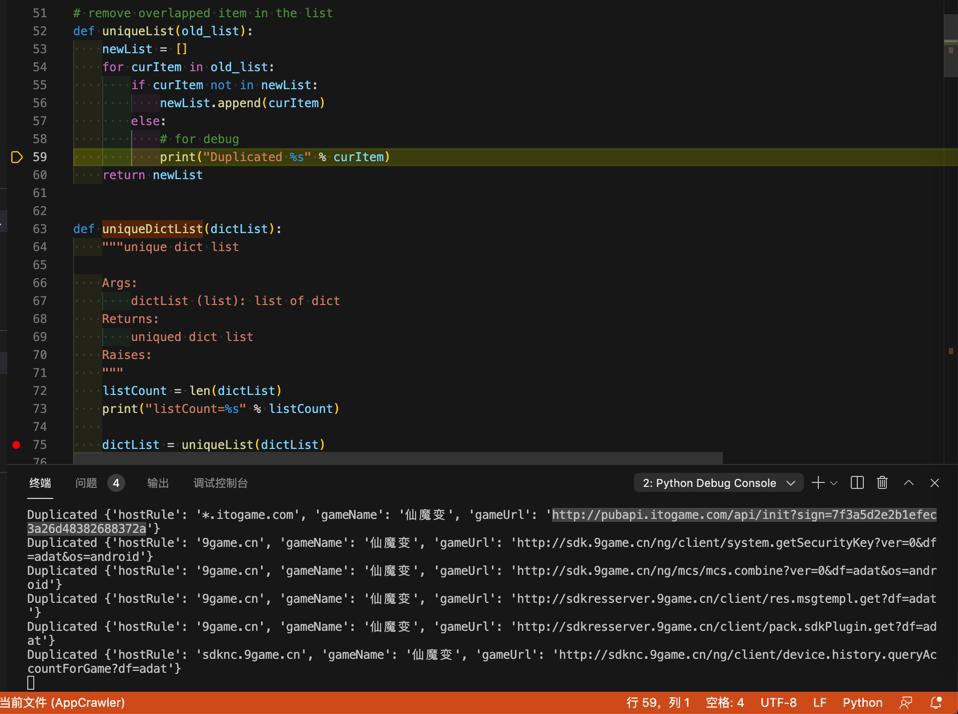
即, 用之前自己已经写好的函数,其实就可以判断 dict是否在dict中
可以实现去重的效果了:
1 2 | 20210511 10:20:10 generateMatchedHostUrl.py:194 INFO matchedUrlDictCount=10020210511 10:20:13 generateMatchedHostUrl.py:198 INFO uniquedMatchedUrlDictCount=72 |
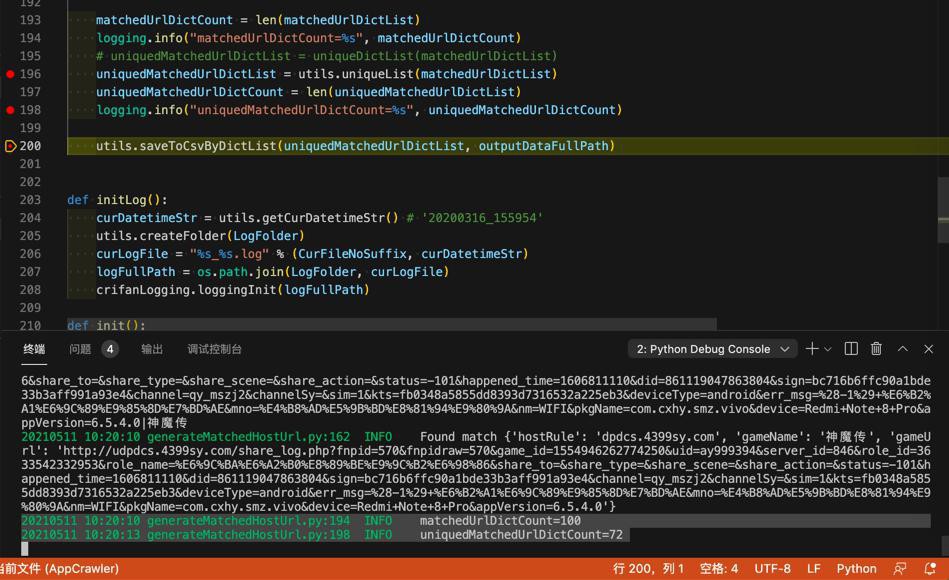
【总结】
此处对于dict的list
每个dict是普通的字符串的dict
比如:
1 |
则:
可以直接用之前的函数实现:数组去重
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | def uniqueList(oldList): """unique list Args: oldList (list): old list Returns: uniqued new list Raises: """ newList = [] for curItem in oldList: if curItem not in newList: newList.append(curItem) # else: # # for debug # print("Duplicated %s" % curItem) return newList |
详见:
转载请注明:在路上 » 【已解决】Python中给字典的数组去重