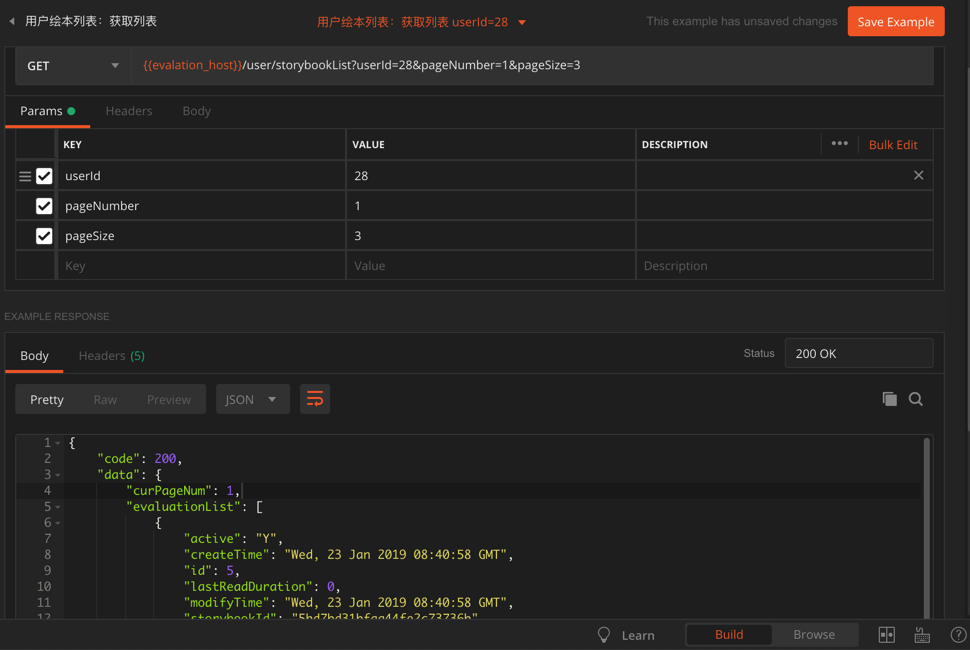
现有Flask项目,已经可以用pymysql中sql语句去查询到已有的mysql的数据库中:
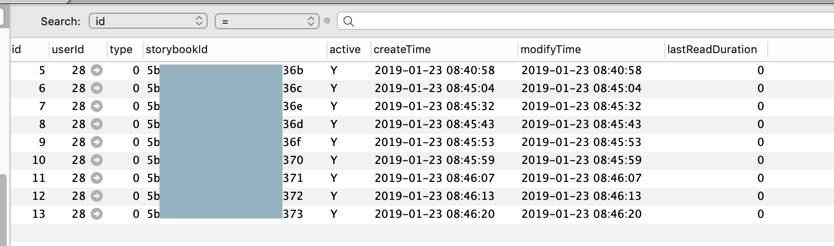
对应的数据了:
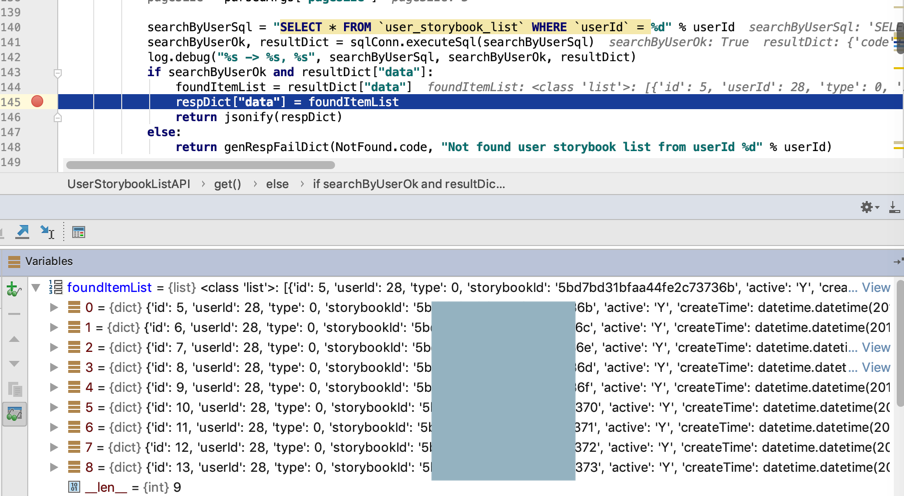
相关代码是:
pageNumber = parsedArgs["pageNumber"]
pageSize = parsedArgs["pageSize"]
searchByUserSql = "SELECT * FROM `user_storybook_list` WHERE `userId` = %d" % userId
searchByUserOk, resultDict = sqlConn.executeSql(searchByUserSql)
log.debug("%s -> %s, %s", searchByUserSql, searchByUserOk, resultDict)
if searchByUserOk and resultDict["data"]:
foundItemList = resultDict["data"]
respDict["data"] = foundItemList
return jsonify(respDict)
else:
return genRespFailDict(NotFound.code, "Not found user storybook list from userId %d" % userId)现在需要去:
实现返回结果的分页数据
根据page的size和number返回对应数据,最好加上:
中的字段:
respData = {
"evaluationList": evaluationList,
"curPageNum": pageNumber,
"numPerPage": pageSize,
"totalNum": totalCount,
"totalPageNum": totalPageNum,
"hasPrev": hasPrev,
"hasNext": hasNext,
}便于前端去分页显示
mysql select paging
MySQL Data – Best way to implement paging? – Stack Overflow
SELECT * FROM tbl LIMIT 5,10; # Retrieve rows 6-15
好像就基本够用了。
还要加上sort才行,根据此处的modifyTime
不过OFFSET含义更明确些:
SELECT column FROM table LIMIT {someLimit} OFFSET {someOffset};其他评论又说,为了性能,避免用OFFSET,和(当数量很大时)避免用LIMIT,
不过,此处希望,在不返回所有数据的情况下,统计总数
Optimized Pagination using MySQL • Code is poetry
SELECT COUNT(*) FROM city;
好像可以用COUNT(*)去计算
Efficient Pagination Using MySQL
解释:如果用OFFSET,则被跳过的数据,其实也还是返回了,放在内存里了,所以导致占用资源,速度变慢
如果是非常大的数据量,都会导致内存不够用
建议:
用LIMIT OFFEST N
性能:3700次查询/秒
不要用 LIMIT M,N
难道和OFFSET的逻辑是一样的?
性能:600次查询/秒
mysql – pagination sql query syntax – Stack Overflow
SELECT * FROM {$statement}
ORDER BY datetime ASC LIMIT {$startpoint} , {$limit}php – Pagination using MySQL LIMIT, OFFSET – Stack Overflow
Why Order By With Limit and Offset is Slow – Faster Pagination in Mysql
解释是:
LIMIT 50000, 20
意思是:
mysql先读取出50020个,扔掉前50000个,留下最后20个
-》所以会导致性能很低
实例:
SELECT * FROM events WHERE date > '2010-01-01T00:00:00-00:00' AND event = 'editstart' ORDER BY date LIMIT 50;
性能:
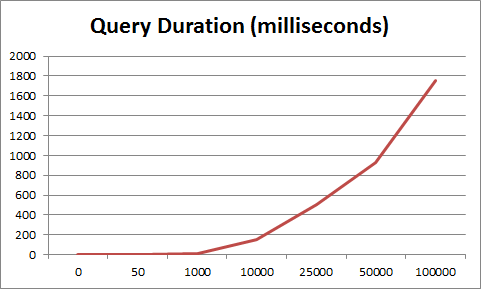
建议:
改用Seek
找到对应的,想要的要跳过的一堆的值的最后一个,然后从那之后再去取
比如:
SELECT *
FROM
events
WHERE
(date,id) > ('2010-07-12T10:29:47-07:00',111866)
AND event = 'editstart'
ORDER BY date, id
LIMIT 10或:
SELECT * FROM events WHERE date>='2010-07-12T10:29:47-07:00' and not (date='2010-07-12T10:29:47-07:00' and id < 111866) AND event = 'editstart' ORDER BY date, id LIMIT 10
但是很明显需要业务逻辑中对应数据和字段满足这种条件才能这么去查
算了,目前总体来说:
要查询的表的数据量很小,所以:
还是用LIMIT M,N
比较合适,不影响什么性能
以后数据量大了,再去优化性能
mysql LIMIT
MySQL的limit用法和分页查询的性能分析及优化 – 唐成勇 – SegmentFault 思否
【总结】
最后用代码:
userId = parsedArgs["userId"]
if userId is None:
return genRespFailDict(BadRequest.code, "Empty userId")
if userId <= 0:
return genRespFailDict(BadRequest.code, "Invalid userId %d" % userId)
pageNumber = parsedArgs["pageNumber"]
if pageNumber < 1:
return genRespFailDict(BadRequest.code, "Invalid pageNumber %d" % pageNumber)
pageSize = parsedArgs["pageSize"]
pageIndex = pageNumber - 1
offset = pageSize * pageIndex
orderBy = "modifyTime"
totalCount = -1
totalPageNum = -1
totalCountSql = "SELECT COUNT(*) from `user_storybook_list` WHERE `userId`=%d" % userId
totalCountOk, resultDict = sqlConn.executeSql(totalCountSql)
log.debug("%s -> %s, %s", totalCountSql, totalCountOk, resultDict)
if totalCountOk and resultDict["data"]:
totalCount = resultDict["data"][0]["COUNT(*)"]
if totalCount > 0:
totalPageNum = int(totalCount / pageSize)
if (totalCount % pageSize) > 0:
totalPageNum += 1
if pageNumber > totalPageNum:
return genRespFailDict(BadRequest.code, "Current page number %d exceed max page number %d" % (
pageNumber, totalPageNum))
hasPrev = False
if pageNumber > 1:
hasPrev = True
hasNext = False
if totalPageNum > 0:
if pageNumber < totalPageNum:
hasNext = True
searchByUserSql = "SELECT * FROM `user_storybook_list` WHERE `userId`=%d ORDER BY `%s` ASC LIMIT %d OFFSET %d" % (userId, orderBy, pageSize, offset)
searchByUserOk, resultDict = sqlConn.executeSql(searchByUserSql)
log.debug("%s -> %s, %s", searchByUserSql, searchByUserOk, resultDict)
if searchByUserOk and resultDict["data"]:
foundItemList = resultDict["data"]
respData = {
"evaluationList": foundItemList,
"curPageNum": pageNumber,
"numPerPage": pageSize,
"totalNum": totalCount,
"totalPageNum": totalPageNum,
"hasPrev": hasPrev,
"hasNext": hasNext,
}
respDict["data"] = respData
return jsonify(respDict)结果:
{
"code": 200,
"data": {
"curPageNum": 1,
"evaluationList": [
{
"active": "Y",
"createTime": "Wed, 23 Jan 2019 08:40:58 GMT",
"id": 5,
"lastReadDuration": 0,
"modifyTime": "Wed, 23 Jan 2019 08:40:58 GMT",
"storybookId": "5bd7bd31bfaa44fe2c73736b",
"type": 0,
"userId": 28
},
{
"active": "Y",
"createTime": "Wed, 23 Jan 2019 08:45:04 GMT",
"id": 6,
"lastReadDuration": 0,
"modifyTime": "Wed, 23 Jan 2019 08:45:04 GMT",
"storybookId": "5bd7bd31bfaa44fe2c73736c",
"type": 0,
"userId": 28
},
{
"active": "Y",
"createTime": "Wed, 23 Jan 2019 08:45:32 GMT",
"id": 7,
"lastReadDuration": 0,
"modifyTime": "Wed, 23 Jan 2019 08:45:32 GMT",
"storybookId": "5bd7bd31bfaa44fe2c73736e",
"type": 0,
"userId": 28
}
],
"hasNext": true,
"hasPrev": false,
"numPerPage": 3,
"totalNum": 9,
"totalPageNum": 3
},
"message": "Get user storybook list ok"
}