折腾:
【已解决】从反编译小花生apk得到的包含业务逻辑代码中找到J字段解码的逻辑并用Python实现
期间,需要去研究看看,现有java代码中的:
com/huili/readingclub/activity/classroom/SelfReadingActivity.java
1 | paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8"); |
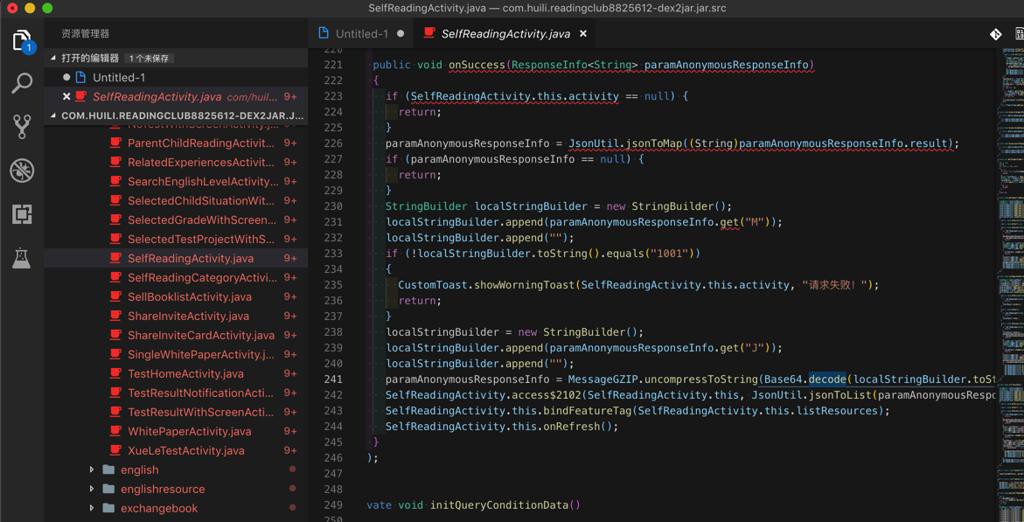
中的:
com/huili/readingclub/utils/Base64.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 | package com.huili.readingclub.utils;import java.util.Arrays;public class Base64{ private static final char[] CA = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray(); private static final int[] IA = new int['Ā']; static { Arrays.fill(IA, -1); int i = CA.length; for (int j = 0; j < i; j++) { IA[CA[j]] = j; } IA[61] = 0; } public static final byte[] decode(String paramString) { if (paramString != null) { i = paramString.length(); } else { i = 0; } if (i == 0) { return new byte[0]; } int j = 0; for (int k = 0; j < i; k = m) { m = k; if (IA[paramString.charAt(j)] < 0) { m = k + 1; } j++; } j = i - k; if (j % 4 != 0) { return null; } int m = 0; while (i > 1) { localObject = IA; k = i - 1; if (localObject[paramString.charAt(k)] > 0) { break; } i = k; if (paramString.charAt(k) == '=') { m++; i = k; } } int n = (j * 6 >> 3) - m; Object localObject = new byte[n]; k = 0; int i = 0; while (k < n) { m = 0; j = 0; while (m < 4) { i1 = IA[paramString.charAt(i)]; if (i1 >= 0) { j = i1 << 18 - m * 6 | j; } else { m--; } m++; i++; } int i1 = k + 1; localObject[k] = ((byte)(byte)(j >> 16)); m = i1; if (i1 < n) { k = i1 + 1; localObject[i1] = ((byte)(byte)(j >> 8)); m = k; if (k < n) { m = k + 1; localObject[k] = ((byte)(byte)j); } } k = m; } return (byte[])localObject; } |
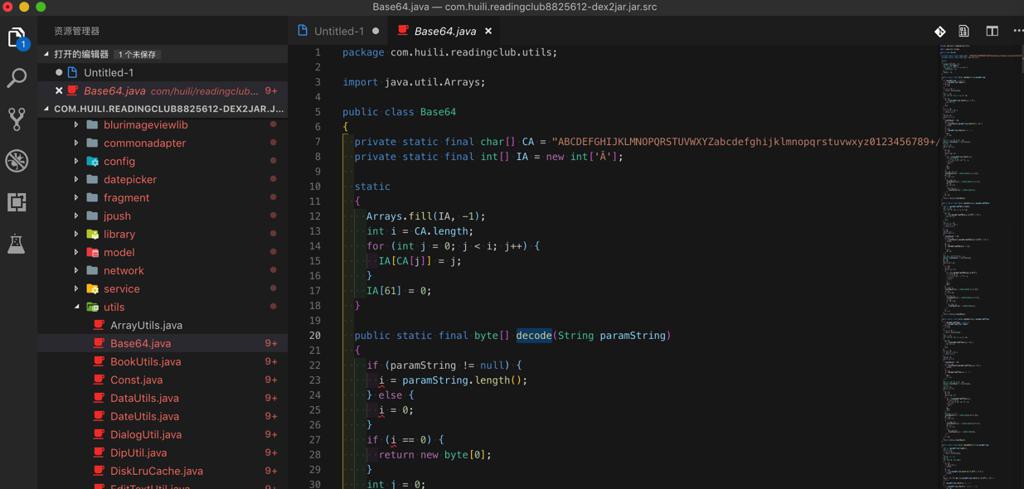
希望搞清楚其具体解密,解码的逻辑
以及如何用Python去实现
此刻所能知道的是:
之前好像听说过
Base64.decode
但是不清楚具体逻辑。
而此处希望是,此处的java的Base64.decode,是通用的base64的decode
且希望Python中能找到,同样算法逻辑的库,直接调用即可。
python base64 decode
1 2 3 4 5 6 7 8 | import base64mystr = 'O João mordeu o cão!'# Encodemystr_encoded = base64.b64encode(mystr.encode('utf-8'))# b'TyBKb8OjbyBtb3JkZXUgbyBjw6NvIQ=='# Decodemystr_encoded = base64.b64decode(mystr_encoded).decode('utf-8')# 'O João mordeu o cão!' |
其中的mystr,估计就是 上面的CA?
去试试:
1 2 3 | import base64a = 'eW91ciB0ZXh0'base64.b64decode(a) |
此处用代码:
1 2 3 4 5 | import base64encodedStr = "H4sIAAAAAAAEALVXW0\/bSBj9K1Ze9oVdYjtOnD6WbbdoL0SlfVrtg5tMg7eJjWynW7SqFFbcuqQQSrmkgdJCubRLCiy3XEHqT6k8Y+epf2E\/xyFXmy2VKkWRx554vjlnzjlffv3TM\/zAc43zMj2e8JAoIRXdEbUY8lzz4NIirrwlq7Pm9IG5l8PpPfNZRi9s4acLnh4PkqIxUR26mAx37iuypPXJD5EC48ERVUPx3hv2rEGkiEgNiWEtoaBexkvzNM0wtJflaT8fDHz3+3AUXnBPlh\/0yQlJ81yjmWCPRxOiKrwK1iZja3itgMdL1IdTyigtk5Xd6vK4uVcb24WZ798Ya5u158\/XyFGJTKWrC+fN+dZVdfWlmXlBXo5ZA\/sKllUT8bigjPRLAxIaRJKGpLC1o4\/JFeP5Dll5gjf2rV2nd\/FksQ7F39mPyVXrp3IsMpCw6n3cYwPJ0t04ju8bmRKemjCK23bV3fANamiY6pc0mbqNhIgoRTvxrAP5E3qIYjcbDwaUfklCSkiIot5AsBfvj1ZX1x3Q9AZ6PEIiIsr1GyzrbcDbWpiFSwhKS4gSdVuQInKcuiUnVFSDuTYPJrmDaV0BYNW1w+r6XO03s3vGXwV7x3FRCimiBS3L8zAUHtWHviCcPVkRo40JPON1pcU4m8HZip4vkePRRknGk7eeCwY4OthNQfqILMwCEV\/nKLPwzfiZAO\/zOR1l+suP8vYczm01n1\/1aDcxZyxBNTGvDdsw93H8ZVIwJ98ZYydQNixug2hXVZdCA3yLuQ7wycE72LExW\/maPuLz+gN0N\/gM4\/188DuE8H++0imIJhkO+NNM25mnLQm04c8EuMvwt8vGubc4lzZejAGUZHHSTB6SleNW\/IMO9pM9A7CrWxPGIZjQUjfkd4YQdVe9JysSunAfKqTIUUWIx9HVfYhnfa5GxLGutnNRQShxz1rAKsIBYwefabcWv78VZtYCtQ1mmgv6XXEmy\/OwFJwTcyeJn6X08rKxnSQL43pxGjC3nGcrY5TmcXqqAThr8dqBONBFpub08gt4mV6cAH7M41OS24Sd6IXp6mYZF\/41ph2Y6Kf6BKnGAfXzCHVTVFSNqiFNXRfVcELUrs4GwzPuscC3p4I1dmHnlqAMI6VPjsVESf18Ytqg93vdXR2\/P8GLoK1TkpmvQ52ttNr7p3JKLxbhAlfWzYPXthDwm21j6sA5h30OQqhYy6zsG+kJvD+Hx84vz+RfBE2UJSFG\/YAsMQwPiWHqRzGi1ghCinp1MmiGcyUjyLmC35kCToXdiCTCtduXRnV7JNBcq1Y4plMrftpdKnizUh1dIhNnQIx12Eu7eH+WLJ3gZEbPPyXZMzgGZKUIIiAzm+b2lnmeIa9OgVrwok\/l0YZ+fBzXRZTxJEuONu39kldzeGq1unzSzc\/Ao\/uyEmlY1h0Fobpa6G\/Zy3OkgyM7SbwsDWkCHWmA5xzEEmyqww5DMl12SY56ZXclEV6uitoI+ClSHXXj3CHRbFta82yXjfkD7mICunE+j2eXyO66eT5jx0Ujsc3zLMCJx3fIYoG8bjqZL9Ad3ZbAUv+0bg8XypZwsrluPi7c4boYBR\/TgJgwGraO5NWF4qdddcJ3mBbvblr2Fajd3N6wxhcFfp5W2l2tmhmzXa3v+\/oQvAQaAZKaxHvl9gwKtpHnYzqjng5aHa+bsMZ37KAGzizHym2RV6\/tdreuiIUMWU03afN2BxAwRHKp6tox9Ajk6CV8QHUOhMUEVQXvuA7oqtQfojYE3X4MdRmbg3ZaAqYmHToA3ywDbbDTnzn+ixvgviExFvlGpUIxYcSpx6pxUdunu5iY9r8bTFfrxQUu8bn9CWNjx2609PyMjaZ5soHnDvXKfPVdCpoBvZjS80U9n\/Q8\/u0\/UDEtQFAPAAA="decodedStr = base64.b64decode(encodedStr)print("decodedStr=%s" % decodedStr) |
结果是:
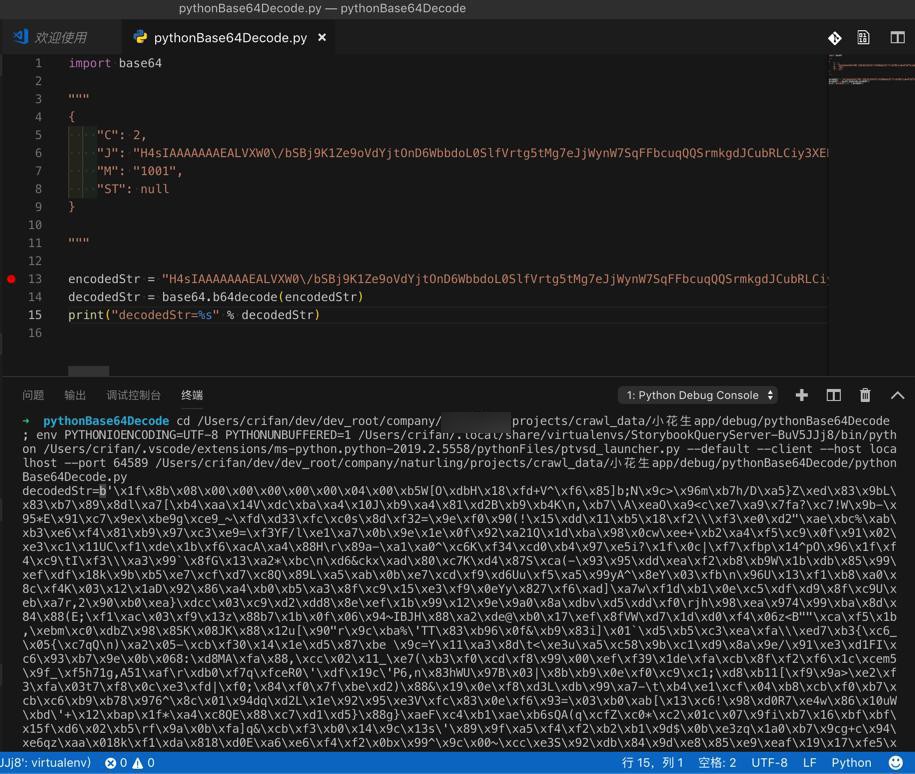
“生成的编码可逆,后一两位可能有“=””
->此处去看看原始字符串最后,果然有=:
1 2 3 4 5 6 7 8 | Python中进行Base64编码和解码>>> import base64>>> s = '我是字符串'>>> a = base64.b64encode(s)>>> print aztLKx9fWt/u0rg==>>> print base64.b64decode(a)我是字符串 |
“对图片进行 Base64 编解码”
->想起来了,之前接触过的,听到过的,base64,就是小图片,直接用base64编码的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | def convert_local_image(): # 原始图片 ==> base64 编码 with open('/path/to/alpha.png', 'r') as fin: image_data = fin.read() base64_data = base64.b64encode(image_data) fout = open('/path/to/base64_content.txt', 'w') fout.write(base64_data) fout.close() # base64 编码 ==> 原始图片 with open('/path/to/base64_content.txt', 'r') as fin: base64_data = fin.read() ori_image_data = base64.b64decode(base64_data) fout = open('/path/to/beta.png', 'wb'): fout.write(ori_image_data) fout.close() |
后来注意到前面java中的CA:
1 | private static final char[] CA = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/".toCharArray(); |
其实只是普通字符合并起来:
A-Z,a-z,0-9,+,/
而已
-》估计是用于表示encode或decode的结果中,字符的取值范围
通过搜索看,不是取值范围:
而是
1 2 3 4 5 6 7 8 9 10 | public static final byte[] encodeToByte(byte[] paramArrayOfByte, boolean paramBoolean)i3 = n + 1;arrayOfByte[n] = ((byte)(byte)CA[(i1 >>> 18 & 0x3F)]);n = i3 + 1;arrayOfByte[i3] = ((byte)(byte)CA[(i1 >>> 12 & 0x3F)]);int i6 = n + 1;arrayOfByte[n] = ((byte)(byte)CA[(i1 >>> 6 & 0x3F)]);i3 = i6 + 1;arrayOfByte[i6] = ((byte)(byte)CA[(i1 & 0x3F)]); |
用于编码为byte字节时候用的。
而对于上面python decode出来的:
1 2 | decodedStr=b'\x1f\x8b\x08\x00\x00\x00\x00\x00\x04\x00\xb5W[O\xdbH\x18\xfd+V^\xf6\x85]b;N\x9c>\x96m\xb7h/D\xa5}Z\xed\x83\x9bL\x83\xb7\x89\x8dl\xa7[\........b9\xfd\tcc\xc7n\xb4\xf4\xfc\x8c\x8d\xa6y\xb2\x81\xe7\x0e\xf5\xca|\xf5]\n\x9a\x01\xbd\x98\xd2\xf3E=\x9f\xf4<\xfe\xed?P1-@P\x0f\x00\x00' |
好像就可以了?
->后记:
“Base64是一种用64个字符来表示任意二进制数据的方法。
用记事本打开exe、jpg、pdf这些文件时,我们都会看到一大堆乱码,因为二进制文件包含很多无法显示和打印的字符,所以,如果要让记事本这样的文本处理软件能处理二进制数据,就需要一个二进制到字符串的转换方法。Base64是一种最常见的二进制编码方法。
Base64的原理很简单,首先,准备一个包含64个字符的数组:
1 | ['A', 'B', 'C', ... 'a', 'b', 'c', ... '0', '1', ... '+', '/'] |
“
->果然是:
上面的CA只是base64编码要求的,64个字符的数组
也提到了:
“base64 encoding takes 8-bit binary byte data and encodes it uses only the characters A-Z, a-z, 0-9, +, /* so it can be transmitted over channels that do not preserve all 8-bits of data, such as email.
Hence, it wants a string of 8-bit bytes. You create those in Python 3 with the b” syntax.”
待后续算法正常处理完毕,包括后面的gzip的解压缩?
真正得到我们要的字符串,才算真正的解码成功。
所以继续去:
【已解决】从反编译小花生apk得到的包含业务逻辑代码中找到J字段解码的逻辑并用Python实现
的:
不过发现此处解析出来 是b开头的bytes字节,而不是str字符串
-》在看了:
1 | MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8") |
中,好像是utf8编码的字符串,好像需要字符串?
所以在考虑 是不是需要再去解码出str,其中编码是utf-8?
那去看:
com/huili/readingclub/utils/Base64.java
的:
1 2 3 4 | public static final byte[] decode(String paramString) {... return (byte[])localObject;} |
很明显,返回的是 byte[] 字节码的数组
所以目前不需要把bytes转为str。
然后此处:
【已解决】python实现java的MessageGZIP.uncompressToString即gzip的解码
已经解决了,说明此处base64的decode是正常的,没问题的。
【总结】
此处java中的:Base64.decode
就是普通的,标准的,base64算法的decode
-》python中有对应base64的库去实现同样的逻辑:
1 2 3 4 | import base64encodedStr = "H4sIAAAAAAAEALVXW0\/bSBj9K1...........0U9n\/Q8\/u0\/UDEtQFAPAAA="decodedStr = base64.b64decode(encodedStr) |
即可。
注意:此处输出的是b’xx’,是bytes,二进制的字节。而不是以为的str,字符串。