折腾:
【未解决】从反编译小花生apk得到的包含业务逻辑代码中找到J字段解码的逻辑并用Python实现
期间,已经用:
【已解决】Python中实现java中的Base64.decode解码加密字符串
得到用base64去decode出来的bytes 字节码
现在需要去搞清楚,对于此处java中的:
com/huili/readingclub/activity/classroom/SelfReadingActivity.java
1 | paramAnonymousResponseInfo = MessageGZIP.uncompressToString(Base64.decode(localStringBuilder.toString()), "UTF-8"); |
-》
MessageGZIP.uncompressToString
代码:
com/huili/readingclub/utils/MessageGZIP.java
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | public static String uncompressToString(byte[] paramArrayOfByte, String paramString) { if ((paramArrayOfByte != null) && (paramArrayOfByte.length != 0)) { ByteArrayOutputStream localByteArrayOutputStream = new ByteArrayOutputStream(); Object localObject = new ByteArrayInputStream(paramArrayOfByte); try { paramArrayOfByte = new java/util/zip/GZIPInputStream; paramArrayOfByte.<init>((InputStream)localObject); localObject = new byte['Ā']; for (;;) { int i = paramArrayOfByte.read((byte[])localObject); if (i < 0) { break; } localByteArrayOutputStream.write((byte[])localObject, 0, i); } paramArrayOfByte = localByteArrayOutputStream.toString(paramString); return paramArrayOfByte; } catch (IOException paramArrayOfByte) { paramArrayOfByte.printStackTrace(); return null; } } return null; } |
中的:
MessageGZIP.uncompressToString
希望是put的gzip算法
这样找个python的gizp库,估计就可以了?
python gzip decompress
“gzip.decompress(data)
Decompress the data, returning a bytes object containing the uncompressed data.
New in version 3.2.”
去试试
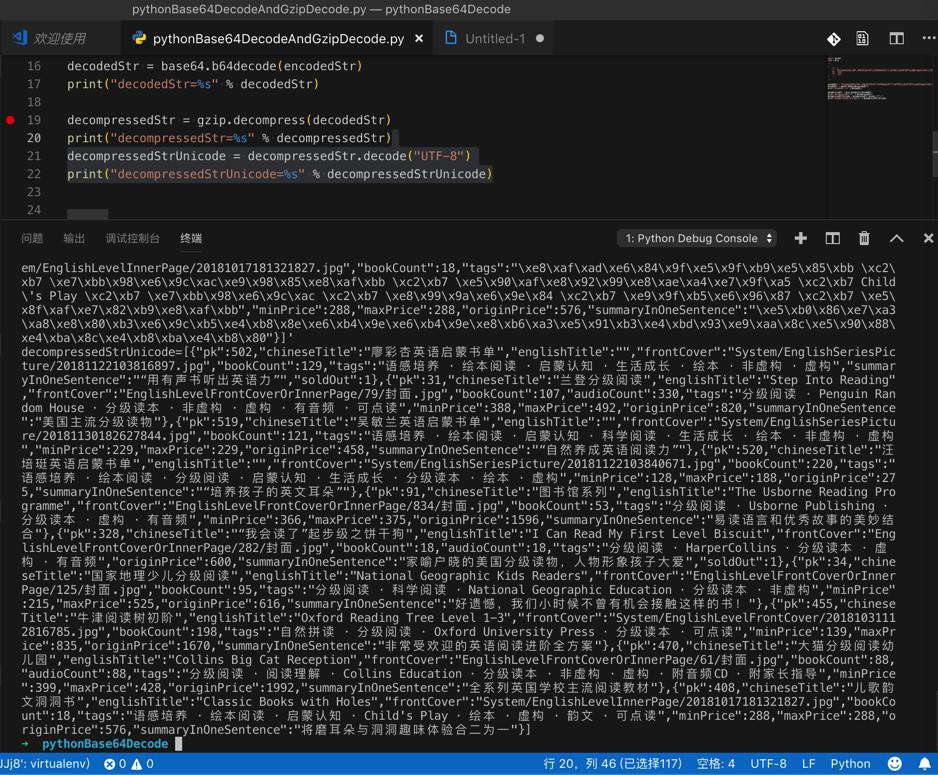
1 2 3 4 | import gzipdecompressStr = gzip.decompress(decodedStr)print("decompressStr=%s" % decompressStr) |
即可解压缩出来我们要的内容:
1 2 3 | decompressStr=b'[{"pk":502,"chineseTitle":"\xe5\xbb\x96\xe5\xbd\xa9\xe6\x9d\x8f\xe8\x8b\xb1\xe8\xaf\xad\xe5\x90\xaf\xe8\x92\x99\xe4\xb9\xa6\xe5\x8d\x95","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181122103816897.jpg","bookCount":129,"tags":"\xe8\xaf\xad\xe6\x84\x9f\xe5\x9f\xb9\xe5\x85\xbb \xc2\xb7 \xe7\xbb\x98\xe6\x9c\xac\xe9\x98\x85\xe8\xaf\xbb \xc2\xb7 \xe5\x90\xaf\xe8\x92\x99\xe8\xae\xa4\xe7\x9......xe6\x9c\xac \xc2\xb7 \xe8\x99\x9a\xe6\x9e\x84 \xc2\xb7 \xe9\x9f\xb5\xe6\x96\x87 \xc2\xb7 \xe5\x8f\xaf\xe7\x82\xb9\xe8\xaf\xbb","minPrice":288,"maxPrice":288,"originPrice":576,"summaryInOneSentence":"\xe5\xb0\x86\xe7\xa3\xa8\xe8\x80\xb3\xe6\x9c\xb5\xe4\xb8\x8e\xe6\xb4\x9e\xe6\xb4\x9e\xe8\xb6\xa3\xe5\x91\xb3\xe4\xbd\x93\xe9\xaa\x8c\xe5\x90\x88\xe4\xba\x8c\xe4\xb8\xba\xe4\xb8\x80"}]' |
不过,此处是b=bytes字节码
要去用utf-8编码解码出原始字符串,带中文的
加上:
1 2 | decompressedStrUnicode = decompressedStr.decode("UTF-8")print("decompressedStrUnicode=%s" % decompressedStrUnicode) |
果然可以解码得到真正的,包含中文的Unicode字符串:
1 | decompressedStrUnicode=[{"pk":502,"chineseTitle":"廖彩杏英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181122103816897.jpg","bookCount":129,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · 生活成长 · 绘本 · 非虚构 · 虚构","summaryInOneSentence":"“用有声书听出英语力”","soldOut":1},{"pk":31,"chineseTitle":"兰登分级阅读","englishTitle":"Step Into Reading","frontCover":"EnglishLevelFrontCoverOrInnerPage/79/封面.jpg","bookCount":107,"audioCount":330,"tags":"分级阅读 · Penguin Random House · 分级读本 · 非虚构 · 虚构 · 有音频 · 可点读","minPrice":388,"maxPrice":492,"originPrice":820,"summaryInOneSentence":"美国主流分级读物"},{"pk":519,"chineseTitle":"吴敏兰英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181130182627844.jpg","bookCount":121,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · 科学阅读 · 生活成长 · 绘本 · 非虚构 · 虚构","minPrice":229,"maxPrice":229,"originPrice":458,"summaryInOneSentence":"“自然养成英语阅读力”"},{"pk":520,"chineseTitle":"汪培珽英语启蒙书单","englishTitle":"","frontCover":"System/EnglishSeriesPicture/20181122103840671.jpg","bookCount":220,"tags":"语感培养 · 绘本阅读 · 分级阅读 · 启蒙认知 · 生活成长 · 分级读本 · 绘本 · 虚构","minPrice":128,"maxPrice":188,"originPrice":275,"summaryInOneSentence":"“培养孩子的英文耳朵”"},{"pk":91,"chineseTitle":"图书馆系列","englishTitle":"The Usborne Reading Programme","frontCover":"EnglishLevelFrontCoverOrInnerPage/834/封面.jpg","bookCount":53,"tags":"分级阅读 · Usborne Publishing · 分级读本 · 虚构 · 有音频","minPrice":366,"maxPrice":375,"originPrice":1596,"summaryInOneSentence":"易读语言和优秀故事的美妙结合"},{"pk":328,"chineseTitle":"“我会读了”起步级之饼干狗","englishTitle":"I Can Read My First Level Biscuit","frontCover":"EnglishLevelFrontCoverOrInnerPage/282/封面.jpg","bookCount":18,"audioCount":18,"tags":"分级阅读 · HarperCollins · 分级读本 · 虚构 · 有音频","originPrice":600,"summaryInOneSentence":"家喻户晓的美国分级读物,人物形象孩子大爱","soldOut":1},{"pk":34,"chineseTitle":"国家地理少儿分级阅读","englishTitle":"National Geographic Kids Readers","frontCover":"EnglishLevelFrontCoverOrInnerPage/125/封面.jpg","bookCount":95,"tags":"分级阅读 · 科学阅读 · National Geographic Education · 分级读本 · 非虚构","minPrice":215,"maxPrice":525,"originPrice":616,"summaryInOneSentence":"好遗憾,我们小时候不曾有机会接触这样的书!"},{"pk":455,"chineseTitle":"牛津阅读树初阶","englishTitle":"Oxford Reading Tree Level 1-3","frontCover":"System/EnglishLevelFrontCover/20181031112816785.jpg","bookCount":198,"tags":"自然拼读 · 分级阅读 · Oxford University Press · 分级读本 · 可点读","minPrice":139,"maxPrice":835,"originPrice":1670,"summaryInOneSentence":"非常受欢迎的英语阅读进阶全方案"},{"pk":470,"chineseTitle":"大猫分级阅读幼儿园","englishTitle":"Collins Big Cat Reception","frontCover":"EnglishLevelFrontCoverOrInnerPage/61/封面.jpg","bookCount":88,"audioCount":88,"tags":"分级阅读 · 阅读理解 · Collins Education · 分级读本 · 非虚构 · 虚构 · 附音频CD · 附家长指导","minPrice":399,"maxPrice":428,"originPrice":1992,"summaryInOneSentence":"全系列英国学校主流阅读教材"},{"pk":408,"chineseTitle":"儿歌韵文洞洞书","englishTitle":"Classic Books with Holes","frontCover":"System/EnglishLevelInnerPage/20181017181321827.jpg","bookCount":18,"tags":"语感培养 · 绘本阅读 · 启蒙认知 · Child's Play · 绘本 · 虚构 · 韵文 · 可点读","minPrice":288,"maxPrice":288,"originPrice":576,"summaryInOneSentence":"将磨耳朵与洞洞趣味体验合二为一"}] |
【总结】
java中的
MessageGZIP.uncompressToString
其实就是:
标准的,普通的,gzip的uncompress解压缩
所以用Python实现就是:
1 2 3 4 5 6 | import gzipdecompressedStr = gzip.decompress(decodedStr)print("decompressedStr=%s" % decompressedStr)decompressedStrUnicode = decompressedStr.decode("UTF-8")print("decompressedStrUnicode=%s" % decompressedStrUnicode) |
其中utf-8是此处字符的编码
即可得到,Unicode的,可以正常显示中文的,原始的字符串了。
转载请注明:在路上 » 【已解决】python实现java的MessageGZIP.uncompressToString即gzip的解码