折腾:
期间,需要把一个dict的json,输出到文件中,且:
带缩进的,好看
不要\uxxx,要encode后的中文
然后再去把json写入到文件,且要格式化带缩进的效果:
<code>with open("currentJson.json", 'w') as tmpFp:
json.dump(currentJson, tmpFp, indent=2, encoding="utf-8")
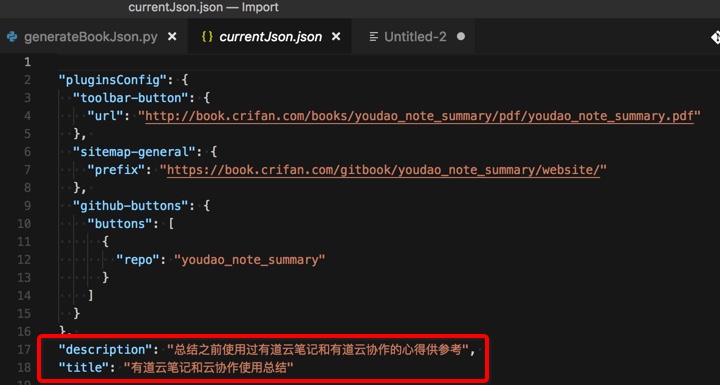
</code>结果输出中的内容,带\uxxxx而不是编码后的中文:
<code>{
"pluginsConfig": {
"toolbar-button": {
"url": "http://book.crifan.com/books/youdao_note_summary/pdf/youdao_note_summary.pdf"
},
"sitemap-general": {
"prefix": "https://book.crifan.com/gitbook/youdao_note_summary/website/"
},
"github-buttons": {
"buttons": [
{
"repo": "youdao_note_summary"
}
]
}
},
"description": "\u603b\u7ed3\u4e4b\u524d\u4f7f\u7528\u8fc7\u6709\u9053\u4e91\u7b14\u8bb0\u548c\u6709\u9053\u4e91\u534f\u4f5c\u7684\u5fc3\u5f97\u4f9b\u53c2\u8003",
"title": "\u6709\u9053\u4e91\u7b14\u8bb0\u548c\u4e91\u534f\u4f5c\u4f7f\u7528\u603b\u7ed3"
}
</code>试了试:
<code># json.dump(currentJson, tmpFp, indent=2)
# currentJsonUtf8 = currentJson.encode("utf-8")
# json.dump(currentJsonUtf8, tmpFp, indent=2)
</code>问题依旧。
python dict to file without unicode
Python Dict and File | Python Education | Google Developers
Suppress the u’prefix indicating unicode’ in python strings – Stack Overflow
python – How to get string objects instead of Unicode from JSON? – Stack Overflow
<code>currentJsonDump = json.dumps(currentJson, ensure_ascii=False) json.dump(currentJsonDump, tmpFp, indent=2, encoding="utf-8") </code>
问题依旧。
难道非要:
<code>>>> nl = json.loads(js)
>>> nl
[u'a', u'b']
>>> nl = [s.encode('utf-8') for s in nl]
>>> nl
['a', 'b']
</code>?
python json dump encoded string
python – Saving utf-8 texts in json.dumps as UTF8, not as \u escape sequence – Stack Overflow
dump后再去调用encode utf-8
<code>currentJsonDump = json.dumps(currentJson, ensure_ascii=False)
print("type(currentJsonDump)", type(currentJsonDump)) #('type(currentJsonDump)', <type 'unicode'>)
currentJsonUtf8 = currentJsonDump.encode("utf-8")
json.dump(currentJsonUtf8, tmpFp, indent=2, encoding="utf-8")
</code>问题依旧。
<code>import codecs
# with open("currentJson.json", 'w') as tmpFp:
with codecs.open("currentJson.json", 'w', encoding="utf-8") as tmpFp:
# json.dump(currentJson, tmpFp, indent=2, encoding="utf-8")
# json.dump(currentJson, tmpFp, indent=2)
# currentJsonUtf8 = currentJson.encode("utf-8")
# json.dump(currentJsonUtf8, tmpFp, indent=2)
currentJsonDump = json.dumps(currentJson, ensure_ascii=False)
print("type(currentJsonDump)", type(currentJsonDump)) #('type(currentJsonDump)', <type 'unicode'>)
currentJsonUtf8 = currentJsonDump.encode("utf-8")
print("type(currentJsonUtf8)", type(currentJsonUtf8))
json.dump(currentJsonUtf8, tmpFp, indent=2, encoding="utf-8")
</code>问题依旧。
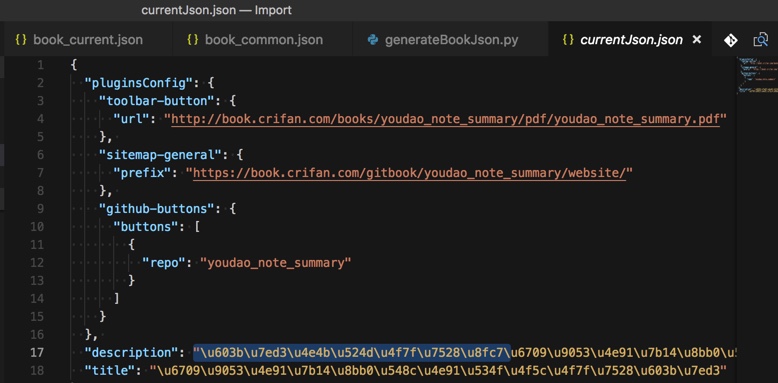
【总结】
最后用:
<code>import codecs
with codecs.open("currentJson.json", 'w', encoding="utf-8") as tmpFp:
json.dump(currentJson, tmpFp, indent=2, ensure_ascii=False)
</code>终于输出了中文了: