折腾:
【未解决】用Python代码从视频中提取出音频mp3文件
期间,对于已有的srt字幕文件:
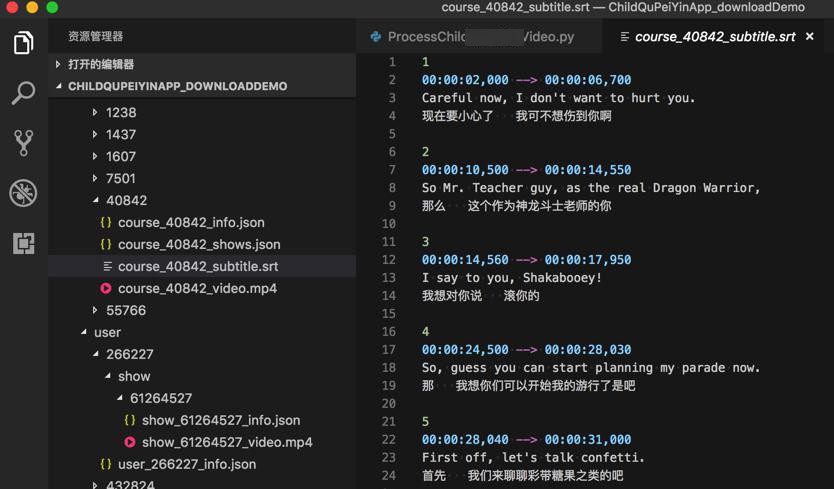
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | 100:00:02,000 --> 00:00:06,700Careful now, I don't want to hurt you.现在要小心了 我可不想伤到你啊200:00:10,500 --> 00:00:14,550So Mr. Teacher guy, as the real Dragon Warrior,那么 这个作为神龙斗士老师的你300:00:14,560 --> 00:00:17,950I say to you, Shakabooey!我想对你说 滚你的400:00:24,500 --> 00:00:28,030So, guess you can start planning my parade now.那 我想你们可以开始我的游行了是吧... |
或:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 100:00:02,310 --> 00:00:04,677I am a little turtle200:00:04,752 --> 00:00:07,540I crawl so slow300:00:07,670 --> 00:00:12,120I carry my house wherever I go.400:00:12,210 --> 00:00:16,927When I get tired, I put in my head, |
现在需要去用Python去处理和解析
希望得到结构化的数据,至少要包括:第几段,起始时间和结束时间,(第一条的)英文字幕
此处数据的结构,看起来格式还是很统一的,其实可以用正则re去匹配。
不过去找找是否有成熟的库,这样可以提高效率,避免重复造轮子
python parse srt file
看起来效果不错。
-》
看起来不是足够好用
所以先去试试:pysrt
先去安装pysrt:
其中此处特殊的是,Mac本地有多个Python,且Python3也有多个:
且此处选择了,看似pip3所对应的
Python 3.6.4 64-bit
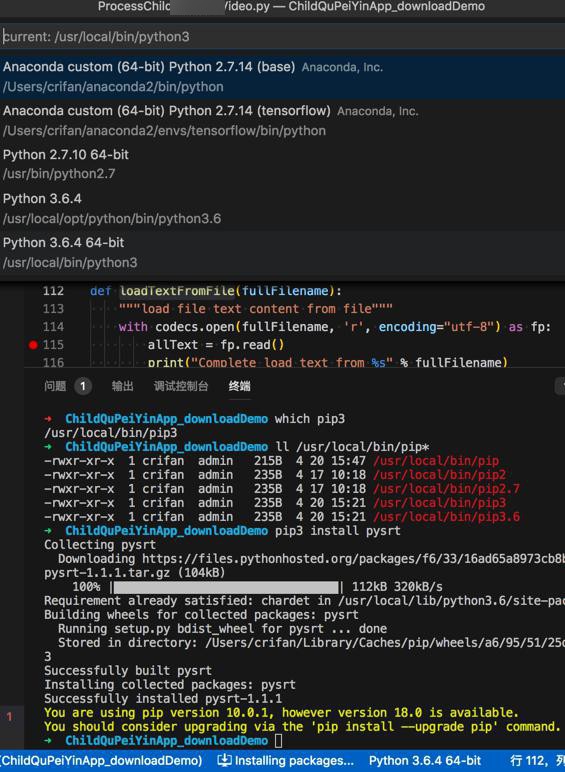
然后用pip3去安装:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | ➜ xxx_downloadDemo which pip3/usr/local/bin/pip3➜ xxx_downloadDemo ll /usr/local/bin/pip*-rwxr-xr-x 1 crifan admin 215B 4 20 15:47 /usr/local/bin/pip-rwxr-xr-x 1 crifan admin 235B 4 17 10:18 /usr/local/bin/pip2-rwxr-xr-x 1 crifan admin 235B 4 17 10:18 /usr/local/bin/pip2.7-rwxr-xr-x 1 crifan admin 235B 4 20 15:21 /usr/local/bin/pip3-rwxr-xr-x 1 crifan admin 235B 4 20 15:21 /usr/local/bin/pip3.6➜ xxx_downloadDemo pip3 install pysrtCollecting pysrt Downloading https://files.pythonhosted.org/packages/f6/33/16ad65a8973cb8bcb494af09ee1b9ab5ffdd6ff300bce5d3ac7d3cb1f2cc/pysrt-1.1.1.tar.gz (104kB) 100% |████████████████████████████████| 112kB 320kB/sRequirement already satisfied: chardet in /usr/local/lib/python3.6/site-packages (from pysrt) (3.0.4)Building wheels for collected packages: pysrt Running setup.py bdist_wheel for pysrt ... done Stored in directory: /Users/crifan/Library/Caches/pip/wheels/a6/95/51/25db5b533f7c8c3bccf661a7f2bf67caaf893f6f92bb37da33Successfully built pysrtInstalling collected packages: pysrtSuccessfully installed pysrt-1.1.1You are using pip version 10.0.1, however version 18.0 is available.You should consider upgrading via the 'pip install --upgrade pip' command. |
然后此处代码中去导入看看是否能识别
1 | import pysrt |
可以识别的。
还可以点击进去确认和看源码:
然后去试试pysrt解析srt文件的效果
代码:
1 | subtitleList = pysrt.open(subtitleFullPath, encoding="utf-8") |
VSCode中调试的结果是:
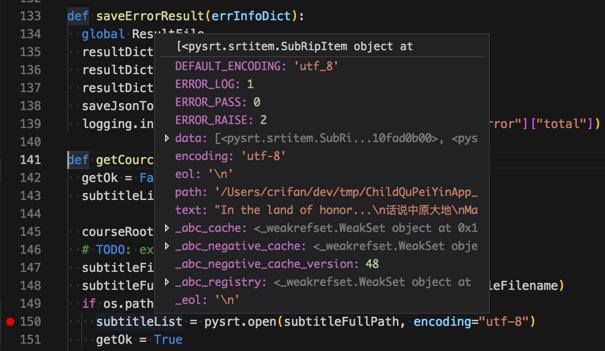
点开data是我希望要的subtitle的list:
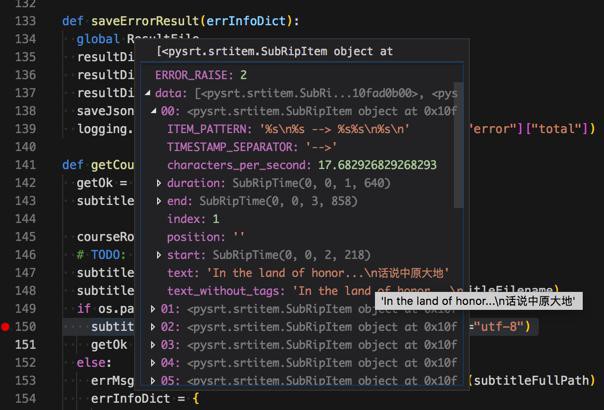
但是对应的每个srtitem中的text,竟然是英文和中文混合了?
没有把中英文字幕分开?
通过打印出来后发现,还真的竟然是字幕混在一起了:
所以:不是我们要的
-》要买换库,要么自己再去拆分出不同字幕
-》考虑到demo中的:
>>> first_sub.start.seconds = 20
>>> first_sub.end.minutes = 5
对于time解析和支持的不错,那么还是用这个库吧,然后字幕自己拆分
不过要确保:不同语言的字幕,都只能是一行,单一语言的字幕,比如英语,内部不能有换行
看了看其他srt字幕的内容,的确满足这条,所以是可以通过\n换行符来拆分出两行字幕 或单行字幕
然后此处:第一行字幕就是英文,第二行可能没有,有的话则是中文字幕
对于换行,此处貌似都是\n,但是也要额外考虑到,是否可能会是\r或\r\n
所以要去找个严格的办法去判断:
python 判断字符串中包含换行
python check string contain newline
所以还是简单的去判断:
if “\n” in “xxx”
吧
然后通过拆分:
1 2 3 4 5 6 7 8 9 10 11 | subtitleEn = "" subtitleZhcn = "" subtitleText = eachSubtitle.text if "\n" in subtitleText: subtitleTextList = subtitleText.split("\n") subtitleEn = subtitleTextList[0] if len(subtitleTextList) > 1: subtitleZhcn = subtitleTextList[1] else: subtitleEn = subtitleText logging.info("[%d] %s | %s", curNum, subtitleEn, subtitleZhcn) |
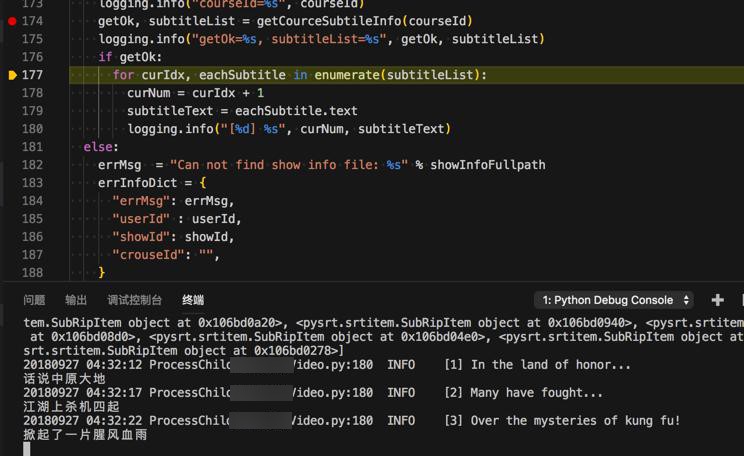
输出效果:
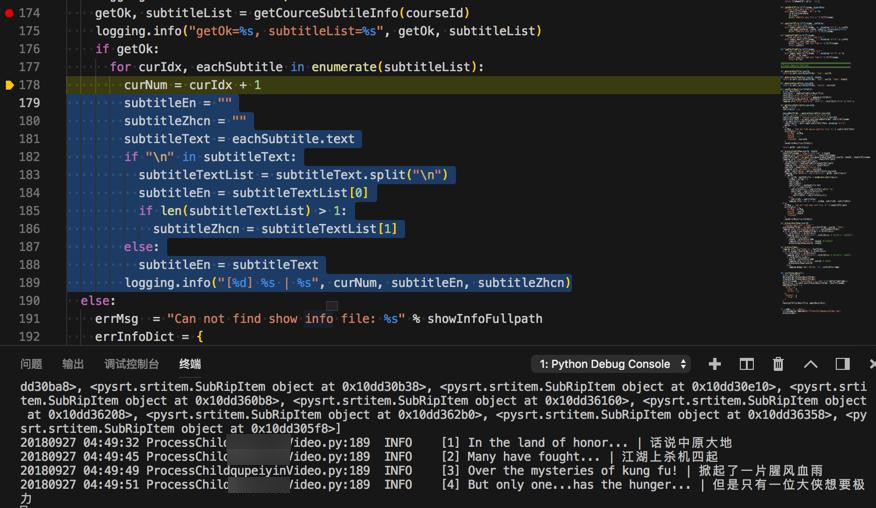
再去拿到起始时间段
代码:
1 2 | startTime = eachSubtitle.startendTime = eachSubtitle.end |
获取到时间,效果不错:
有 hours,minutes,seconds,milliseconds
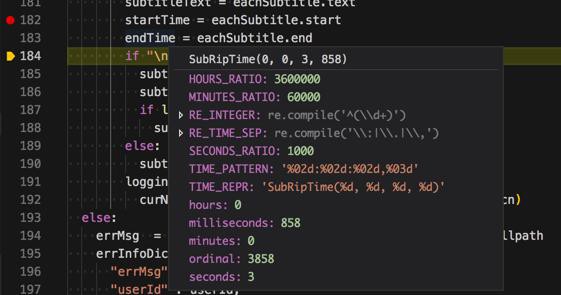
输出如下:
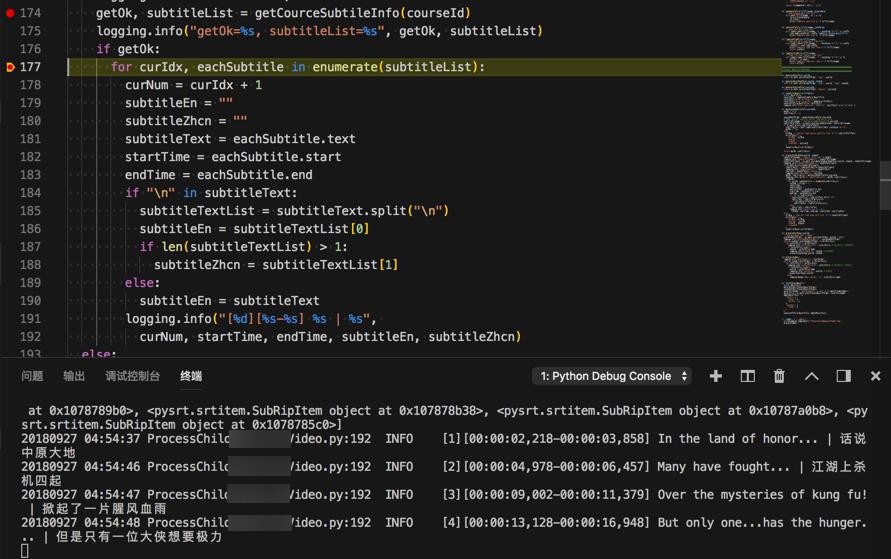
【总结】
最后用库pysrt,去解析srt字幕
代码:
1 2 3 4 5 6 | import pysrt subtitleFilename = "course_%s_subtitle.srt" % courseId subtitleFullPath = os.path.join(courseRootFolder, subtitleFilename) if os.path.exists(subtitleFullPath): subtitleList = pysrt.open(subtitleFullPath, encoding="utf-8") getOk = True |
效果:
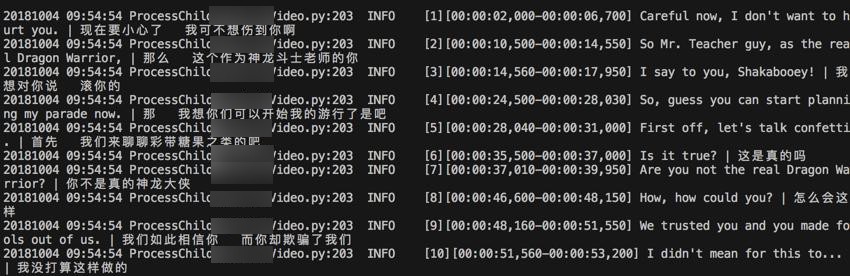
转载请注明:在路上 » 【已解决】Python解析.srt字幕文件