Q:
python同一行 获取不同数据怎么写?正则-CSDN问答
https://ask.csdn.net/questions/776189
“
python
例如
PRINTABLE:张三TEL;VOICE:13882200000TEL:+8618674060000 PRINTABLE:王二TEL;VOICE:13987200000 PRINTABLE:李四TEL;VOICE:13987200000TEL:+861549860000TEL:18674060000
我需要匹配上面的电话号码.有些只有一个.但是有些是连个.或者更多..
请问怎么写正则匹配呢??
我写的遇到有多个号码的就会出问题.”
A:
简答:同一行内,获取不同数据,用re.findall
注:而不是re.search,我最开始也差点搞错,写成re.search去尝试匹配多个的group了,发现不对,改为re.findall,即可
详解:
思路:
先把要匹配的内容,电话号码,出现的规律,用语言组织和表达出来
再去把规律,转换成正则
(1)先把要匹配的内容,电话号码,出现的规律,用语言组织和表达出来
上面多行字符串中,包含电话号码的规律,经过观察,可以描述如下
每一行中 电话号码的开始部分 有的是VOICE: 有的是TEL: 电话号码本身 内容的规律 有的是1xx开头的,比如 13987200000 有的是+86再加1xx开头的,比如 +861549860000 长度的规律 1xx部分,是固定的11位 如果有+86,则是 3+11=14位
(2)再去把规律,转换成正则
经过调试,代码如下:
#!/usr/bin/python
# -*- coding: utf-8 -*-
# Author: Crifan Li
# Update: 20191216
# Function: Using regex to extract phone numbers
import re
def reExtractPhone():
print(“=”*60)
# Method 1: single input mutiple line str
multipleLinePhoneStr = “””PRINTABLE:张三TEL;VOICE:13882200000TEL:+8618674060000
PRINTABLE:王二TEL;VOICE:13987200000
PRINTABLE:李四TEL;VOICE:13987200000TEL:+8615498601234TEL:18674060000″””
# phoneRule = “((\+86)?\d{11})”
phoneRule = “((VOICE:)|(TEL:))((\+86)?\d{11})”
matchPhoneList = re.findall(phoneRule, multipleLinePhoneStr, re.MULTILINE)
# print(“matchPhoneList=%s” % matchPhoneList)
print(“multipleLinePhoneStr=%s =>” % multipleLinePhoneStr)
if matchPhoneList:
for curIdx, eachMatchPhone in enumerate(matchPhoneList):
# print(“eachMatchPhone=%s” % (eachMatchPhone, ))
singlePhone = eachMatchPhone[3]
print(“[%d] singlePhone=%s” % (curIdx, singlePhone))
# [0] singlePhone=13882200000
# [1] singlePhone=+8618674060000
# [2] singlePhone=13987200000
# [3] singlePhone=13987200000
# [4] singlePhone=+8615498601234
# [5] singlePhone=18674060000
print(“=”*60)
# Method 2: mutiple input single line str
inputPhoneStrList = [
“PRINTABLE:张三TEL;VOICE:13882200000TEL:+8618674060000”,
“PRINTABLE:王二TEL;VOICE:13987200000”,
“PRINTABLE:李四TEL;VOICE:13987200000TEL:+8615498601234TEL:18674060000”,
]
for curIdx, eachInputPhoneStr in enumerate(inputPhoneStrList):
phoneRule = “((VOICE:)|(TEL:))((\+86)?\d{11})+”
matchPhoneList = re.findall(phoneRule, eachInputPhoneStr, re.DOTALL)
# print(“matchPhoneList=%s” % matchPhoneList)
print(“[%d] eachInputPhoneStr=%s =>” % (curIdx, eachInputPhoneStr))
for eachMatchPhone in matchPhoneList:
# print(“eachMatchPhone=%s” % (eachMatchPhone, ))
singlePhone = eachMatchPhone[3]
print(“singlePhone=%s” % singlePhone)
# [0] eachInputPhoneStr=PRINTABLE:张三TEL;VOICE:13882200000TEL:+8618674060000 =>
# singlePhone=13882200000
# singlePhone=+8618674060000
# [1] eachInputPhoneStr=PRINTABLE:王二TEL;VOICE:13987200000 =>
# singlePhone=13987200000
# [2] eachInputPhoneStr=PRINTABLE:李四TEL;VOICE:13987200000TEL:+8615498601234TEL:18674060000 =>
# singlePhone=13987200000
# singlePhone=+8615498601234
# singlePhone=18674060000
if __name__ == “__main__”:
reExtractPhone()
输出:
说明:
原内容中:+861549860000
是笔误,只有10位数字,所以匹配不到,
为了能匹配到,手动改为:+8615498601234
如果也要匹配到10位的号码,可以把
\d{11}改为
\d{10,11}【后记】
期间调试,借助了之前找到的正则的网站:
RegExr: Learn, Build, & Test RegEx
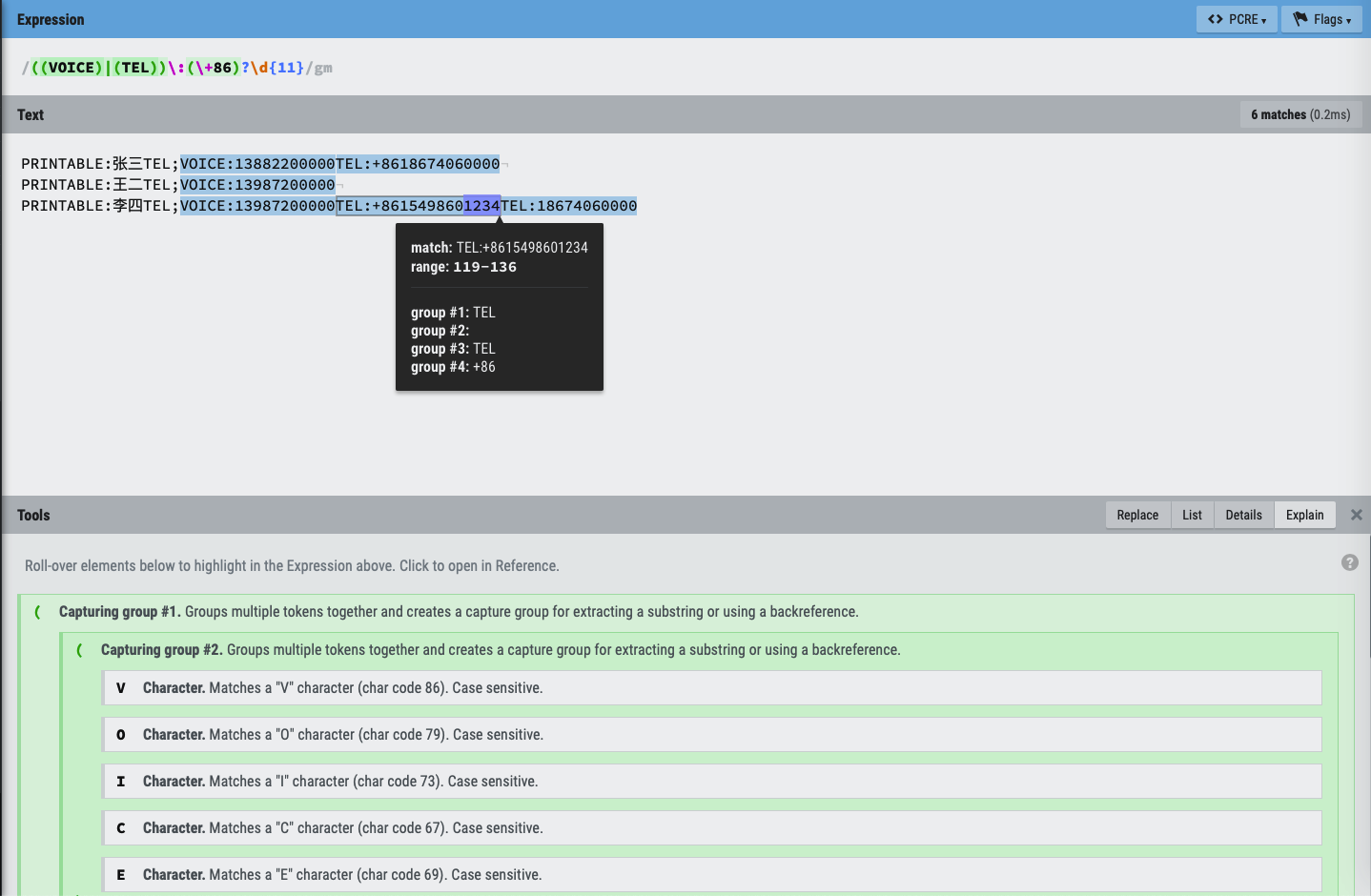
效果很不错,对于调试正则,很有帮助。
转载请注明:在路上 » 【问题解答】Python提取一个或多个电话号码