随机森林 原理
【总结】
- 随机森林
- =Random Forest=RF
- 是什么:一种算法
- 一种机器学习算法
- 作用
- 利用特征来分类,确定特征选取顺序,最终输出结果
- 产生结果的逻辑
- 依靠于决策树的投票选择来决定最后的分类结果
- 所属领域
- 集成学习(Ensemble Learning)方法
- 机器学习的一大分支
- 随机森林:最早的集成学习算法之一
- 特点:
- 宏观
- 新兴起的
- 高度灵活的
- 具体
- 在当前所有算法中,具有极好的准确率
- 能够有效地运行在大数据集上
- 能够处理具有高维特征的输入样本,而且不需要降维
- 能够评估各个特征在分类问题上的重要性
- 在生成过程中,能够获取到内部生成误差的一种无偏估计
- 对于缺失值问题也能够获得很好得结果
- 应用领域
- 市场营销
- 建模
- 统计客户信息
- 来源、保留和流失
- 医疗保健保险
- 预测
- 疾病的风险和病患者的易感性
- 相关基础知识
- 信息、熵以及信息增益的概念
- 决策树
- 图解
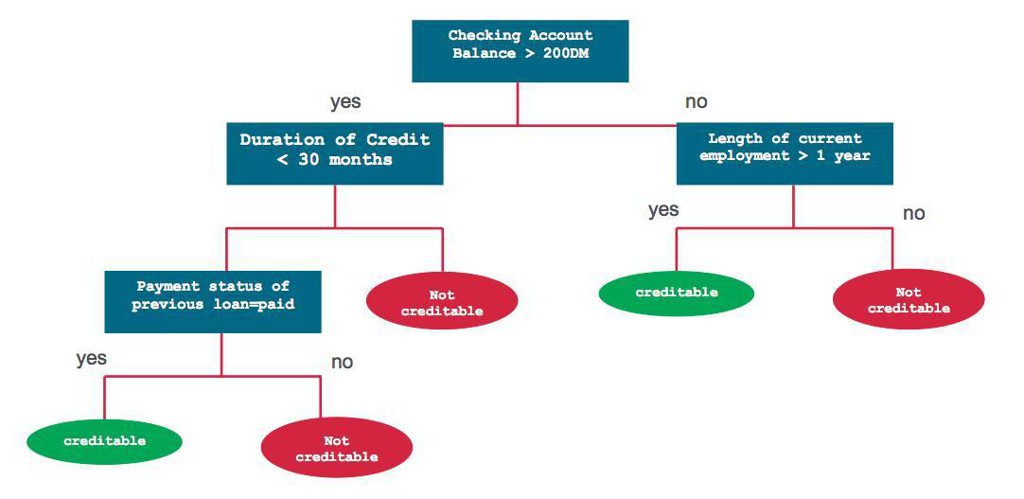
- 一种树形结构
- 每个内部节点表示一个属性上的测试
- 每个分支代表一个测试输出
- 每个叶节点代表一种类别
- 常见算法
- C4.5
- ID3
- CART
- 集成学习
- 通过建立几个模型组合的来解决单一预测问题
- 目的:提高预测的效果
- 原理:
- 生成多个分类器/模型,各自独立地学习和作出预测
- 这些预测最后结合成单预测
- 优于任何一个单分类的做出预测
- 随机森林的生成
- 图解

- 集成学习
- 核心逻辑:三个臭皮匠,顶个诸葛亮,集成学习就是几个臭皮匠集成起来比诸葛亮还牛逼
- Bagging
- =Bootstrap aggregating=有放回采样的集成
- 集成学习的一种
- 模型平均方法(model averaging approach)的特例
- 目的和效果
- 提高用于统计分类回归的机器学习算法的稳定性和精度
- 减小方差
- 防止过拟合
- =防止噪声影响
- 因为它的样本是有放回采样
- 一些特例就很可能不会被采集到
- 即使采集到,也因为投票而被否决
- 从样本上防止了过拟合
- 用途
- 典型代表:用决策树
- 即随机森林
- 其他任何方法
- 朴素贝叶斯
- 逻辑
- 一人一票
- 样本权值是一样的
- 各分类器的权值也都相等
- Boosting
- =提升方法
- 提升的含义
- 将容易找到的识别率不高的弱分类算法提升为识别率很高的强分类算法
- 一种提高任意给定学习算法(弱分类算法)准确度的方法
- 起源
- Valiant提出的PAC学习模型
- PAC=Probably Approximately Correct=概率近似正确
- 是什么
- 一种常用的统计学习方法
- 一种框架算法
- 如何实现=实现方式
- 通过构造一个预测函数系列,然后以一定的方式将他们组合成一个预测函数
- 特点
- 应用广泛且有效
- 适用于:分类问题
- 作用
- 通过改变训练样本的权重,学习多个分类器
- 并将这些分类器进行线性组合,提高分类的性能
- 常见算法
- AdaBoost算法
- 最具代表性
转载请注明:在路上 » 【整理】随机森林 原理