折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,
已经可以去用scrapy打开页面:
了,但是返回的页面,却是没有加载全部的内容:
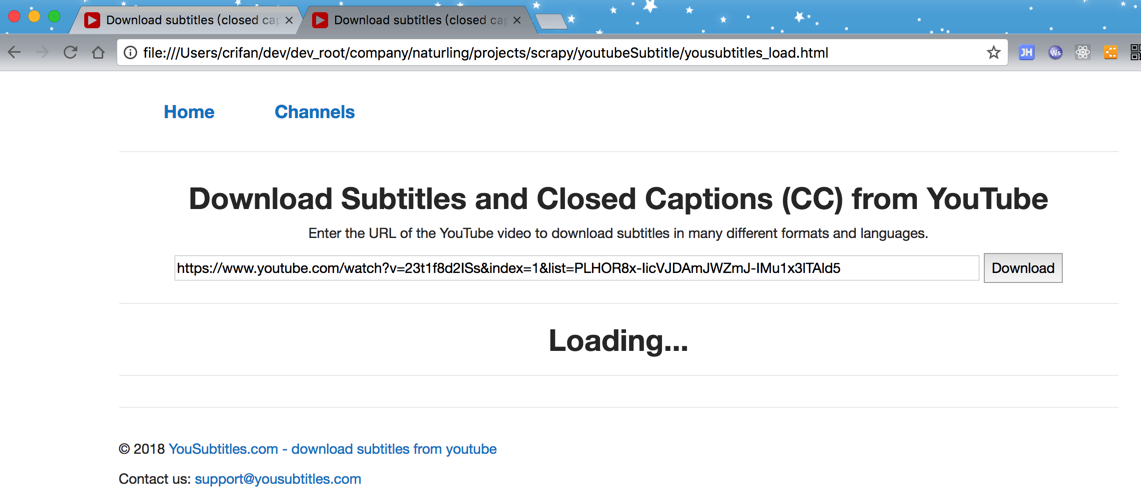
全部加载的应该是这样的:
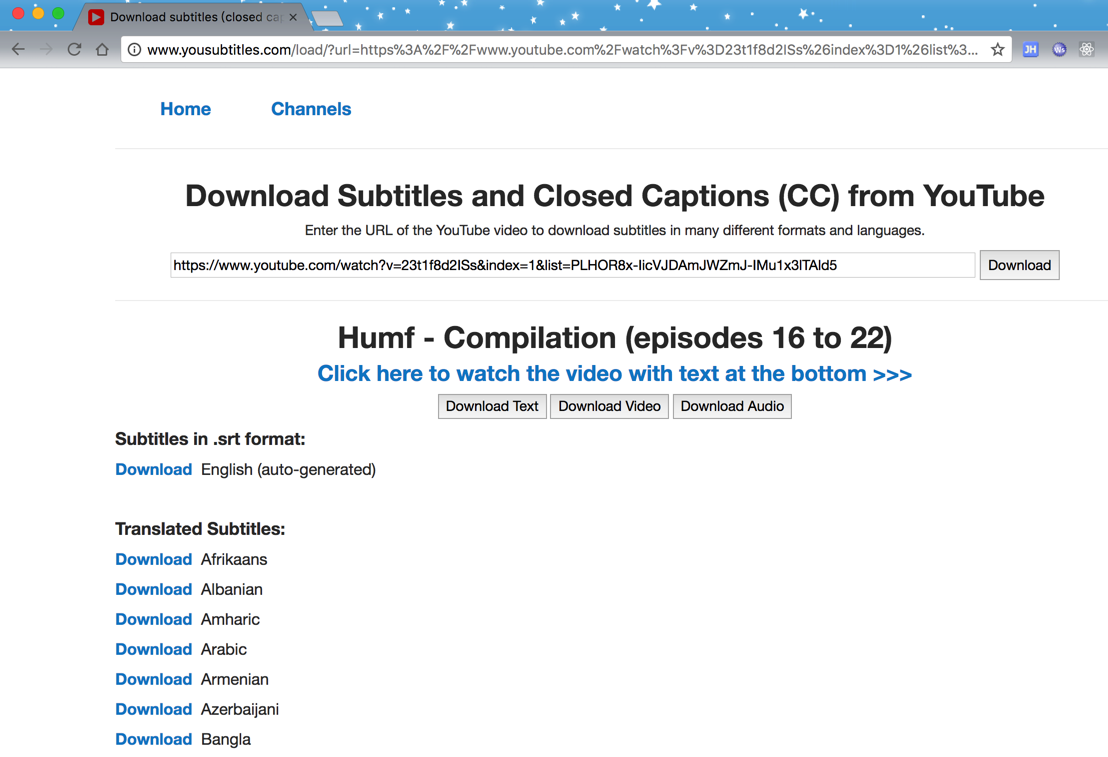
scrapy page load not completed
python – Scrapy response incomplete – Stack Overflow
scrapy page loading
python – Wait until the webpage loads in Scrapy – Stack Overflow
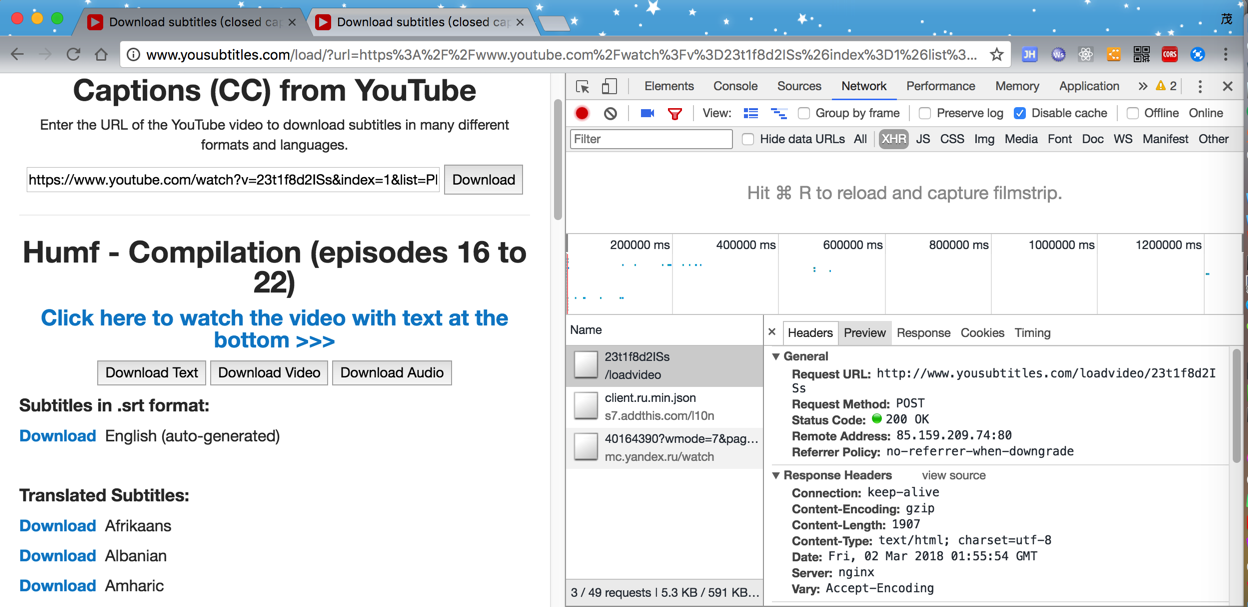
还是去用chrome调试,看看到底加载了数据的js和请求是什么
找到了:
POST /loadvideo/23t1f8d2ISs HTTP/1.1
Host: www.yousubtitles.com
Connection: keep-alive
Content-Length: 0
Pragma: no-cache
Cache-Control: no-cache
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://www.yousubtitles.com
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8
Cookie: _ym_uid=1519808696639134764; _ym_isad=2; _ym_visorc_40164390=w; __atuvc=13%7C9; __atuvs=5a98a5092e989c01003
HTTP/1.1 200 OK
Server: nginx
Date: Fri, 02 Mar 2018 01:55:54 GMT
Content-Type: text/html; charset=utf-8
Content-Length: 1907
Connection: keep-alive
Vary: Accept-Encoding
Content-Encoding: gzip
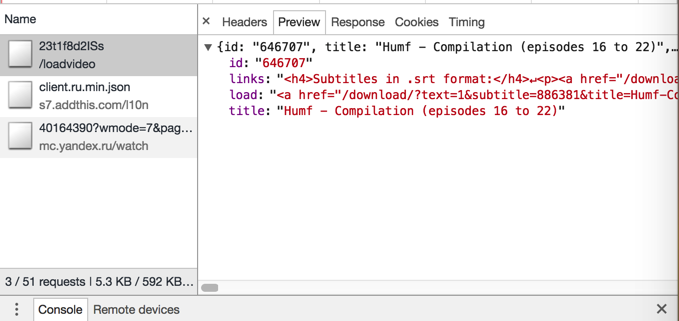
而得到的其中links是html的encode后的内容:
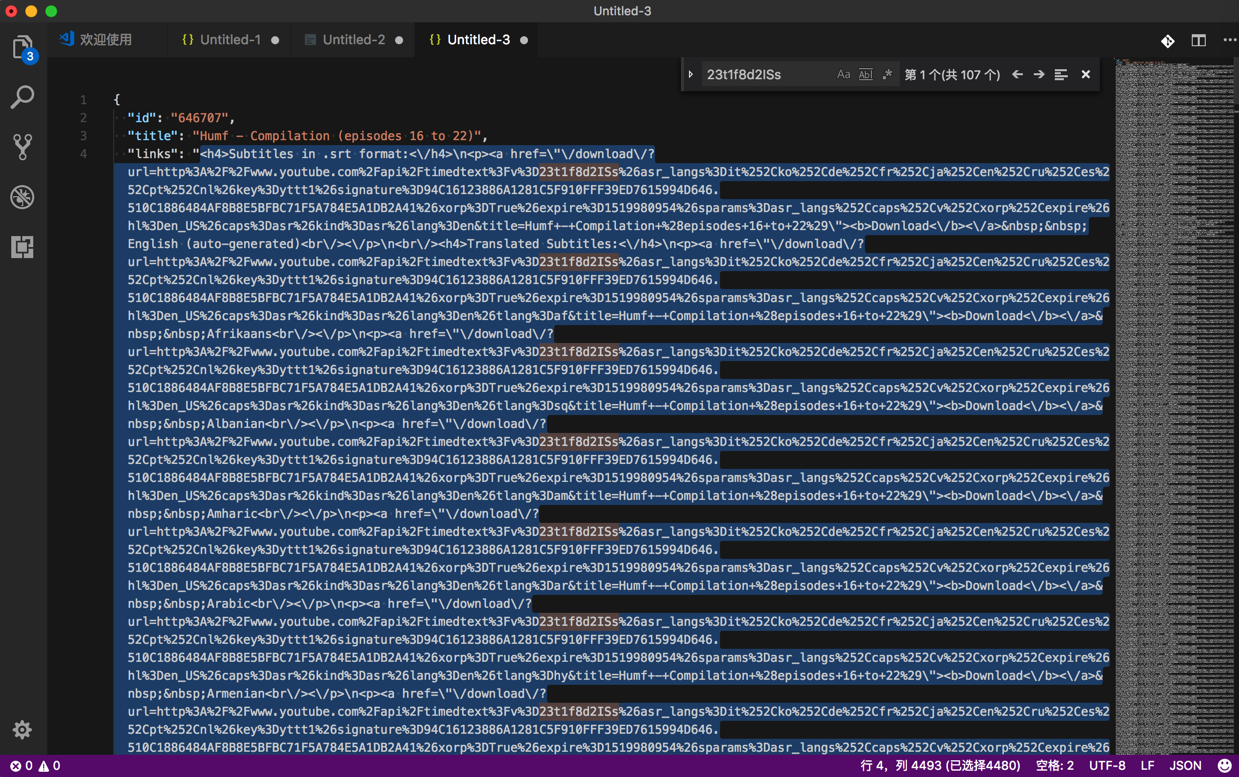
需要反向解析后,才能方便获取其中的href的链接地址
所以现在清楚了:
实际上此处用Scrapy去抓取的页面,只是普通的静态网页,而其中想要的内容是通过js动态的额外的http的post请求获得的。
所以此处想要实现:Scrapy加载全部网页内容,需要自己去调试页面,找到对应的js的http的请求,然后代码中再去模拟即可。
此处找到的额外的js的http请求是:
Request URL:http://www.yousubtitles.com/loadvideo/23t1f8d2ISs
Request Method: POST
然后再去解析返回的内容。
代码:
<code>import re
foundVideoId = re.search(r'v=(?P<videoId>[\w\-]+)', singleVideoUrl)
if foundVideoId:
videoId = foundVideoId.group("videoId")
self.logger.info("videoId=%s", videoId) # u'23t1f8d2ISs'
# http://www.yousubtitles.com/loadvideo/23t1f8d2ISs
loadVideoUrl = "http://www.yousubtitles.com/loadvideo/" + videoId
self.logger.info("loadVideoUrl=%s", loadVideoUrl) # u'http://www.yousubtitles.com/loadvideo/23t1f8d2ISs'
yield scrapy.Request(url=loadVideoUrl, callback=self.parseLoadVideoResp, method="POST")
def parseLoadVideoResp(self, response):
"""
parse response of yousubtitles load video for each youtube video id
:param response:
:return:
"""
# for debug
self.saveHtml("loadvideo", response.body)
respUrl = response.url
self.logger.info("respUrl=%s", respUrl)
</code>效果是:
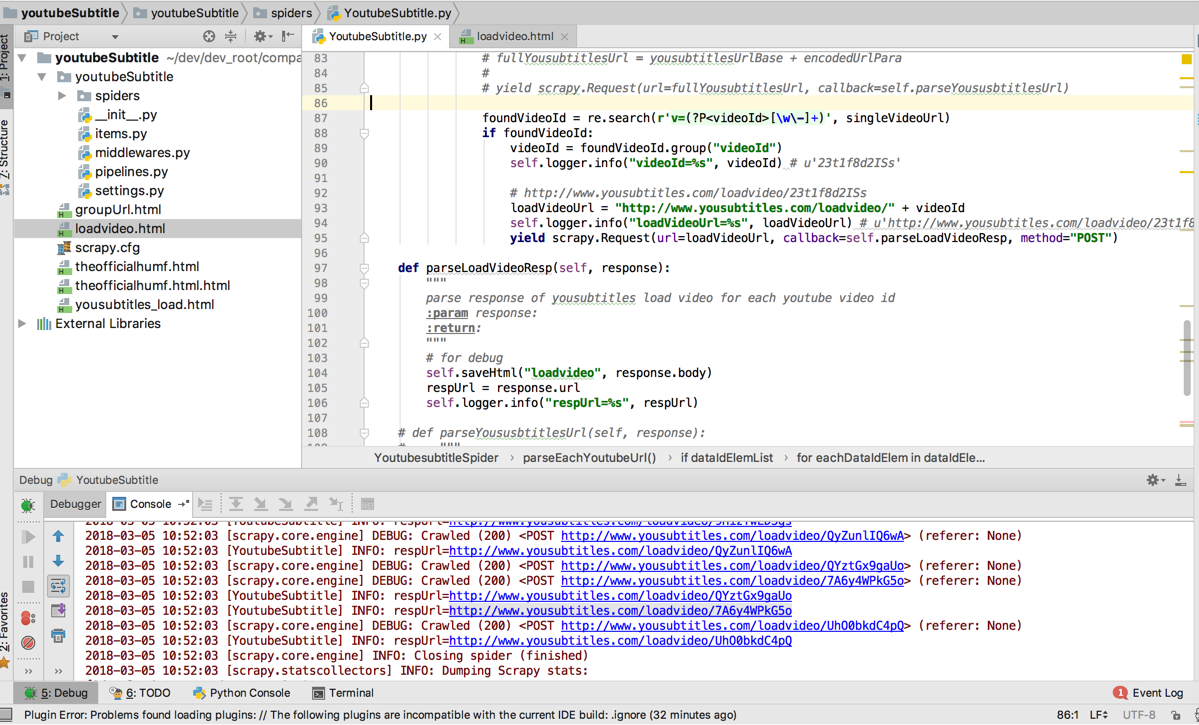
可以获得返回的内容:
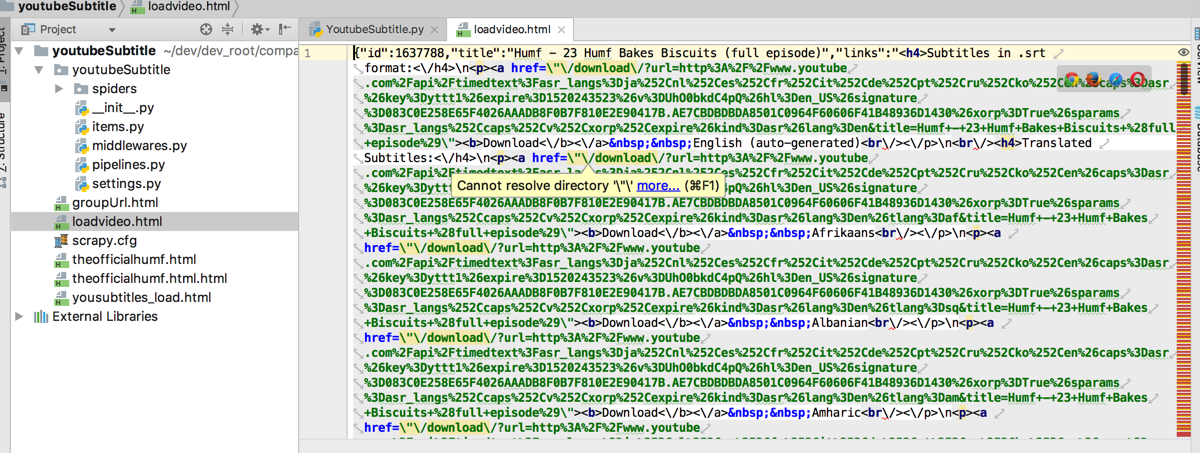
然后接着就可以去进行后续的解析等内容了。
【总结】
此处用Scrapy去抓取的页面,只是普通的静态网页,而其中想要的内容是通过js动态的额外的http的post请求获得的。
所以此处想要实现:Scrapy加载全部网页内容,需要自己去调试页面,找到对应的js的http的请求,然后代码中再去模拟即可。
而具体的额外的http请求是什么,需要自己调试页面去找的。
调试工具推荐Chrome/Firefox/Safari等,都可以。
转载请注明:在路上 » 【已解决】Scrapy如何加载全部网页内容