折腾:
【记录】用Python的Scrapy去爬取Youtube中Humf的字幕
期间,去调用
想办法下载字幕,结果无法提示:
DEBUG: Forbidden by robots.txt
2018-03-01 16:47:48 [YoutubeSubtitle] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D1p7rmxYPbf8%26index%3D32%26list%3DPLHOR8x-IicVJF_L_NsctdpDLwzJDEbW4i>, spider=<YoutubesubtitleSpider ‘YoutubeSubtitle’ at 0x10b41e710>
2018-03-01 16:47:48 [YoutubeSubtitle] INFO: request.meta{‘depth’: 2, ‘proxy’: ‘http://127.0.0.1:1087’}
2018-03-01 16:47:48 [scrapy.downloadermiddlewares.robotstxt] DEBUG: Forbidden by robots.txt: <GET http://www.yousubtitles.com/load/?url=https%3A%2F%2Fwww.youtube.com%2Fwatch%3Fv%3D1p7rmxYPbf8%26index%3D32%26list%3DPLHOR8x-IicVJF_L_NsctdpDLwzJDEbW4i>
2018-03-01 16:47:48 [scrapy.core.engine] INFO: Closing spider (finished)
而无法继续打开url。
scrapy DEBUG: Forbidden by robots.txt
爬虫出现Forbidden by robots.txt – CSDN博客
python – getting Forbidden by robots.txt: scrapy – Stack Overflow
去看看log中是否有robots.txt:
果然是有的:

2018-03-01 16:47:46 [YoutubeSubtitle] INFO: YoutubesubtitleSpiderMiddleware process_request: request=<GET http://www.yousubtitles.com/robots.txt>, spider=<YoutubesubtitleSpider ‘YoutubeSubtitle’ at 0x10b41e710>
2018-03-01 16:47:46 [YoutubeSubtitle] INFO: request.meta{‘dont_obey_robotstxt’: True, ‘proxy’: ‘http://127.0.0.1:1087’}
去setting中设置ROBOTSTXT_OBEY为false
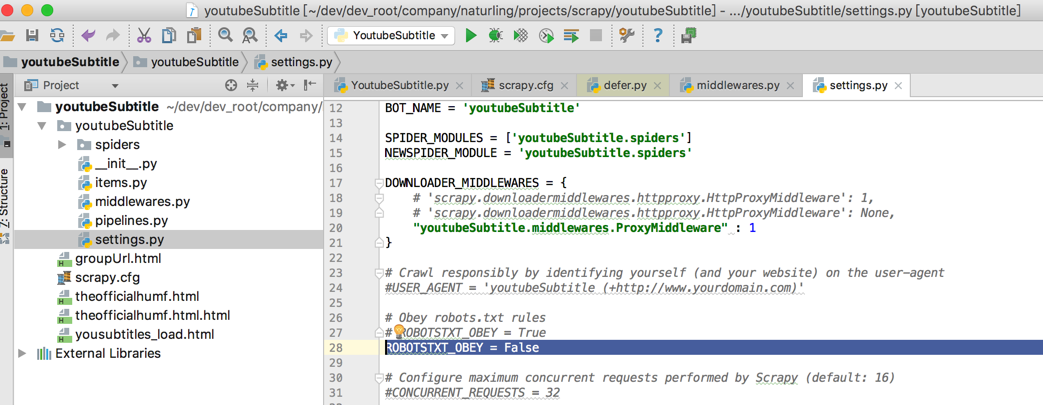
然后再去试试
即可正常加载url,执行到对应断点:
【总结】
Scrapy默认遵守robots协议,所以针对某些网站,设置了robots.txt的规则,不允许爬取其中某些资源,则Scrapy就不会去爬取。
通过去setting中设置ROBOTSTXT_OBEY为false:
ROBOTSTXT_OBEY = False
即可不遵守协议,而去爬取对应页面内容了。