swift判断字符 中文 英文 数字
comparison – Swift: how to find out if letter is Alphanumeric or Digit – Stack Overflow
swift – How to check is a string or number – Stack Overflow
iOS–判断字符串NSString中数字、中文、大小写英文 – 5ibc.net
swift check string chinese char number
How can I check if a string contains Chinese in Swift? – Stack Overflow
代码:
import UIKit var myString = "Hi! 大家好!It’s contains Chinese!" var a = false for c in myString.characters { let cs = String(c) a = a || (cs != cs.stringByApplyingTransform(NSStringTransformMandarinToLatin, reverse: false)) } print("\(myString) contains Chinese characters = \(a)") extension String { var containsChineseCharacters: Bool { return self.rangeOfString("\\p{Han}", options: .RegularExpressionSearch) != nil } } if myString.containsChineseCharacters { print("\(myString): Contains Chinese") }else{ print("\(myString): Not Contains Chinese") } myString = "zhang san" if myString.containsChineseCharacters { print("\(myString): Contains Chinese") }else{ print("\(myString): Not Contains Chinese") } |
效果:
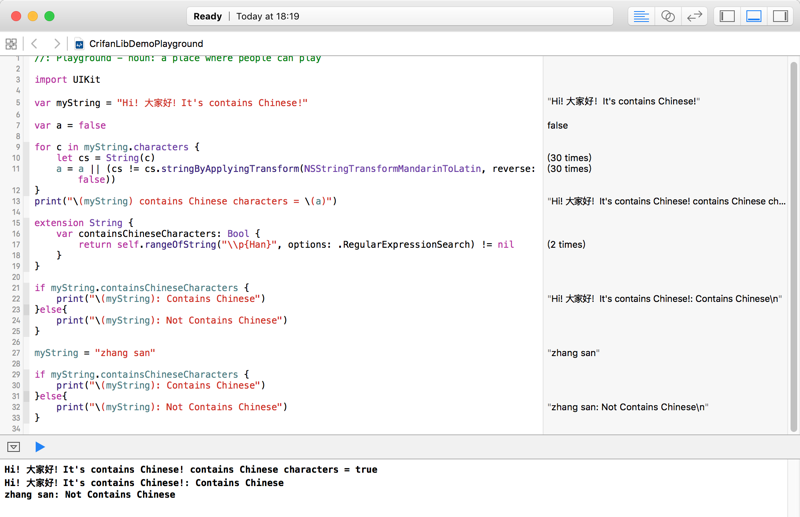
用stringByApplyingTransform去翻译,太耗时间
还是用RegularExpressionSearch正则效率高
至于上述的写法:
rangeOfString("\\p{Han}", options: .RegularExpressionSearch)
可以搜到中文
的原因
此处去找找。
搜:
rangeOfString
找到定义:
-》
-》
Search and Comparison Options – NSString Class Reference
-》
stringByReplacingOccurrencesOfString(_:withString:options:range:) – NSString Class Reference
-》
Searching, Comparing, and Sorting Strings
但是没有解决问题
搜:
swift string regex han p
参考:
-》
Regex Tutorial – Unicode Characters and Properties
\p{Han}
是属于Unicode Script
表示属于CJK的中日韩字符
最后用:
//: Playground – noun: a place where people can play import UIKit extension String { func replace(from:String, to:String) -> String { return self.stringByReplacingOccurrencesOfString(from, withString: to) } } //get first char(string) from input a string func getFirstChar(str:String) -> String { var firstChar:String = "" if !str.isEmpty{ firstChar = str[Range(start: str.startIndex, end: str.startIndex.advancedBy(1))] } return firstChar } //get last char(string) from input a string func getLastChar(str:String) -> String { var lastChar:String = "" if !str.isEmpty { lastChar = str[Range(start: str.endIndex.advancedBy(-1), end:str.endIndex )] } return lastChar } //split string into character array func splitSingleStrToCharArr(strToSplit:String) -> [Character] { //print("strToSplit=\(strToSplit)") //strToSplit=周杰伦 let splitedCharArr:[Character] = Array(strToSplit.characters) //print("splitedCharArr=\(splitedCharArr)") //splitedCharArr=["周", "杰", "伦"] return splitedCharArr } //split string into string array, normally seperator is white space //if origin string not containing white space, then pass the empty string here, will split to every single char as string func splitSingleStrToStrArr(strToSplit:String, seperatorStr:String) -> [String] { //print("strToSplit=\(strToSplit), seperatorStr=\(seperatorStr)") var splitedStrArr:[String] = [String]() if !seperatorStr.isEmpty { let seperatorChar:Character = splitSingleStrToCharArr(seperatorStr)[0] splitedStrArr = strToSplit.characters.split(seperatorChar).map(String.init) } else { //split string(without space) into every single char as string let splitedCharArr:[Character] = splitSingleStrToCharArr(strToSplit) for eachChar in splitedCharArr { splitedStrArr.append(String(eachChar)) } } //print("splitedStrArr=\(splitedStrArr)") return splitedStrArr } //merge character array into string func mergeCharArrToSingleStr(charArr:[Character]) -> String { //print("charArr=\(charArr)") //charArr=["一", "个", "字", "符", "串"] let mergedSingleStr:String = String(charArr) //"一个字符串" //print("mergedSingleStr=\(mergedSingleStr)") return mergedSingleStr } //merge string array into single string func mergeStrArrToSingleStr(strArr:[String]) -> String { //print("strArr=\(strArr)") var singleStr:String = "" for eachStr in strArr { singleStr += eachStr } //print("singleStr\(singleStr)") return singleStr } extension String { var containsChineseCharacters: Bool { return self.rangeOfString("\\p{Han}", options: .RegularExpressionSearch) != nil } var isAllChineseCharacters: Bool { var isAll = false if let chineseRangeIdx = self.rangeOfString("\\p{Han}+", options: .RegularExpressionSearch) { print("chineseRangeIdx=\(chineseRangeIdx)") let chineseSubStr = self.substringWithRange(chineseRangeIdx) print("chineseSubStr=\(chineseSubStr)") if chineseSubStr == self { isAll = true } } return isAll } var isAllLetters: Bool { var isAll = true for eachChar in self.characters { if !( ((eachChar >= "A") && (eachChar <= "Z")) || ((eachChar >= "a") && (eachChar <= "z")) ){ isAll = false break } } return isAll } var isAllDigits: Bool { var isAll = true for eachChar in self.characters { if !((eachChar >= "1") && (eachChar <= "9")){ isAll = false break } } return isAll } } func genHeaderText(headerName:String) -> String { print("\r\ngenHeaderText") var headerText = "" //if all chinese name, get last one cn char if headerName.isAllChineseCharacters { print("\(headerName) isAllChineseCharacters") headerText = getLastChar(headerName) }else if headerName.isAllLetters { print("\(headerName) isAllLetters") let firstTwoChar = (headerName as NSString).substringToIndex(2) print("firstTwoChar=\(firstTwoChar)") headerText = firstTwoChar.uppercaseString }else if headerName.isAllDigits { print("\(headerName) isAllDigits") headerText = (headerName as NSString).substringToIndex(2) }else if headerName.containsString(" "){ print("\(headerName) contain empty space") let subStrArr:[String] = splitSingleStrToStrArr(headerName, seperatorStr: " ") print("subStrArr=\(subStrArr)") if subStrArr.count >= 2 { let firstStr = subStrArr[0] let secondStr = subStrArr[1] print("firstStr=\(firstStr), secondStr=\(secondStr)") let firstChar = getFirstChar(firstStr) let sencondChar = getFirstChar(secondStr) print("firstChar=\(firstChar), sencondChar=\(sencondChar)") let mergedTwoChar = firstChar + sencondChar print("mergedTwoChar=\(mergedTwoChar)") headerText = mergedTwoChar.uppercaseString } }else{ let firstTwoChar = (headerName as NSString).substringToIndex(2) print("firstTwoChar=\(firstTwoChar)") headerText = firstTwoChar.uppercaseString } print("\(headerName) -> \(headerText)") return headerText } let name1 = "赵四" let name2 = "crifan" let name3 = "crifan li" //字母,数字和中文混排,取前两个字符 let name4 = "123" let name5 = "C李" let name6 = "李CR" let name7 = "李L" let name8 = "L李" let name9 = "11李" let name10 = "李11" let name11 = "1李2" let name12 = "a244cc" let name13 = "a2三b444cc张" let name14 = "2937518054189267" genHeaderText(name1) genHeaderText(name2) genHeaderText(name3) genHeaderText(name4) genHeaderText(name5) genHeaderText(name6) genHeaderText(name7) genHeaderText(name8) genHeaderText(name9) genHeaderText(name10) genHeaderText(name11) genHeaderText(name12) genHeaderText(name13) genHeaderText(name14) |
输出:
genHeaderText chineseRangeIdx=0..<2 chineseSubStr=赵四 赵四 isAllChineseCharacters 赵四 -> 四 genHeaderText crifan isAllLetters firstTwoChar=cr crifan -> CR genHeaderText crifan li contain empty space subStrArr=["crifan", "li"] firstStr=crifan, secondStr=li firstChar=c, sencondChar=l mergedTwoChar=cl crifan li -> CL genHeaderText 123 isAllDigits 123 -> 12 genHeaderText chineseRangeIdx=1..<2 chineseSubStr=李 firstTwoChar=C李 C李 -> C李 genHeaderText chineseRangeIdx=0..<1 chineseSubStr=李 firstTwoChar=李C 李CR -> 李C genHeaderText chineseRangeIdx=0..<1 chineseSubStr=李 firstTwoChar=李L 李L -> 李L genHeaderText chineseRangeIdx=1..<2 chineseSubStr=李 firstTwoChar=L李 L李 -> L李 genHeaderText chineseRangeIdx=2..<3 chineseSubStr=李 firstTwoChar=11 11李 -> 11 genHeaderText chineseRangeIdx=0..<1 chineseSubStr=李 firstTwoChar=李1 李11 -> 李1 genHeaderText chineseRangeIdx=1..<2 chineseSubStr=李 firstTwoChar=1李 1李2 -> 1李 genHeaderText firstTwoChar=a2 a244cc -> A2 genHeaderText chineseRangeIdx=2..<3 chineseSubStr=三 firstTwoChar=a2 a2三b444cc张 -> A2 genHeaderText firstTwoChar=29 2937518054189267 -> 29 |
转载请注明:在路上 » [已解决]swift判断字符中文英文数字